Ad Optimization Best Practices: The 2026 Performance Playbook
The definitive 2026 guide to ad optimization best practices — a high-output creative production system, statistically honest A/B testing, budget governance and pacing rules, the metrics that matter, structured account hygiene, an optimization cadence, and an FAQ that settles the hard questions performance teams keep arguing about.

Ad Optimization Best Practices: The 2026 Performance Playbook
Updated June 21, 2026 — written and reviewed by the AdMapix Research team.
Ad optimization best practices are the disciplined, repeatable methods that turn an advertising budget into efficient, scalable results — covering how you produce creative, how you test it, how you govern budget, which metrics you actually trust, and the cadence you run it all on. In 2026, with global mobile ad spend pushing past the $430 billion mark and creative fatigue compressing the useful life of an ad to a couple of weeks, the gap between campaigns that scale and campaigns that stall comes down to optimization discipline, not budget size. This playbook distills the practices used by top-performing growth teams — whether you run user acquisition for a gaming app, a direct-to-consumer (DTC) brand, or a fintech product — into a system you can act on this week. For the creative-evidence layer that feeds your testing, pair this with the ad creative analysis scorecard and the creative testing framework; for the competitive context, see the competitor ad analysis framework.
A word on what optimization is and isn't, because the term gets stretched until it's meaningless. Optimization is not "checking the dashboard and pausing the worst ad." That's reaction, and reaction without a system just chases noise. Real ad optimization is a closed loop: a production engine that ships enough creative to feed testing, a testing engine that produces statistically honest verdicts, a budget-governance layer that scales winners without lighting money on fire, and a measurement layer that points at the metric that actually pays your bills. Each part is necessary; any one missing and the others underperform. This guide builds all four, in order, and then gives you the cadence that keeps them running.
The single most important reframe before we start: optimization is a throughput problem, not a cleverness problem. Most teams don't lose because they picked the wrong color or wrote a weak CTA — they lose because they can't produce, test, and learn fast enough to keep up with how quickly creative decays and competition iterates. The teams that win in 2026 aren't smarter; they have a faster, more honest loop. Everything below is engineered to raise your throughput of verified learning — the only currency that compounds.
TL;DR — The 2026 Optimization Playbook in One Screen
- Optimization is a closed loop: produce → test → govern budget → measure → repeat. A weakness in any stage caps the whole system; fix the bottleneck, not the easiest stage.
- Creative is the biggest lever. In account after account, the creative explains far more of the performance variance than bid tweaks or audience micro-targeting. Build a modular, always-on production engine so creative is never the constraint.
- Test one variable at a time, to statistical significance. Never call a winner below ~90% confidence; aim for 95% before scaling budget. Underpowered, multi-variable tests are how teams ship noise and call it insight.
- Govern budget with rules, not vibes. Scale winners in measured steps, kill losers on pre-set thresholds, and respect the learning phase — most "broken" campaigns were just restarted into instability.
- Optimize to the metric that pays you (ROAS, CAC payback, contribution margin), not the vanity metric that's easy to move (CTR, CPM). Upper-funnel metrics are diagnostics, not goals.
- Lean toward consolidation. Modern algorithms learn faster with more signal per ad set; fragmenting budget across dozens of tiny ad sets starves the learning phase.
- Run it on a cadence: daily guardrail checks, a weekly optimization sprint, a monthly structural review. Discipline beats heroics.
- Public ad evidence (including from AdMapix) shows you what creative is running in your market — useful for ideas — but it can't reveal competitor spend, ROAS, or targeting. Your own analytics is the only place performance is proven.
The Optimization Loop: Why Order Matters
Before the tactics, internalize the loop, because the order is load-bearing. Production comes first because you cannot test what you cannot make — a brilliant testing methodology starved of creative variants tests nothing. Testing comes second because budget governance is meaningless without verified winners to scale; scaling an unvalidated ad just spends faster into uncertainty. Budget governance comes third because it's the lever that converts a proven winner into actual growth. Measurement wraps all three because it's how you know whether any of it worked — and the wrong metric makes the entire loop optimize toward the wrong outcome.
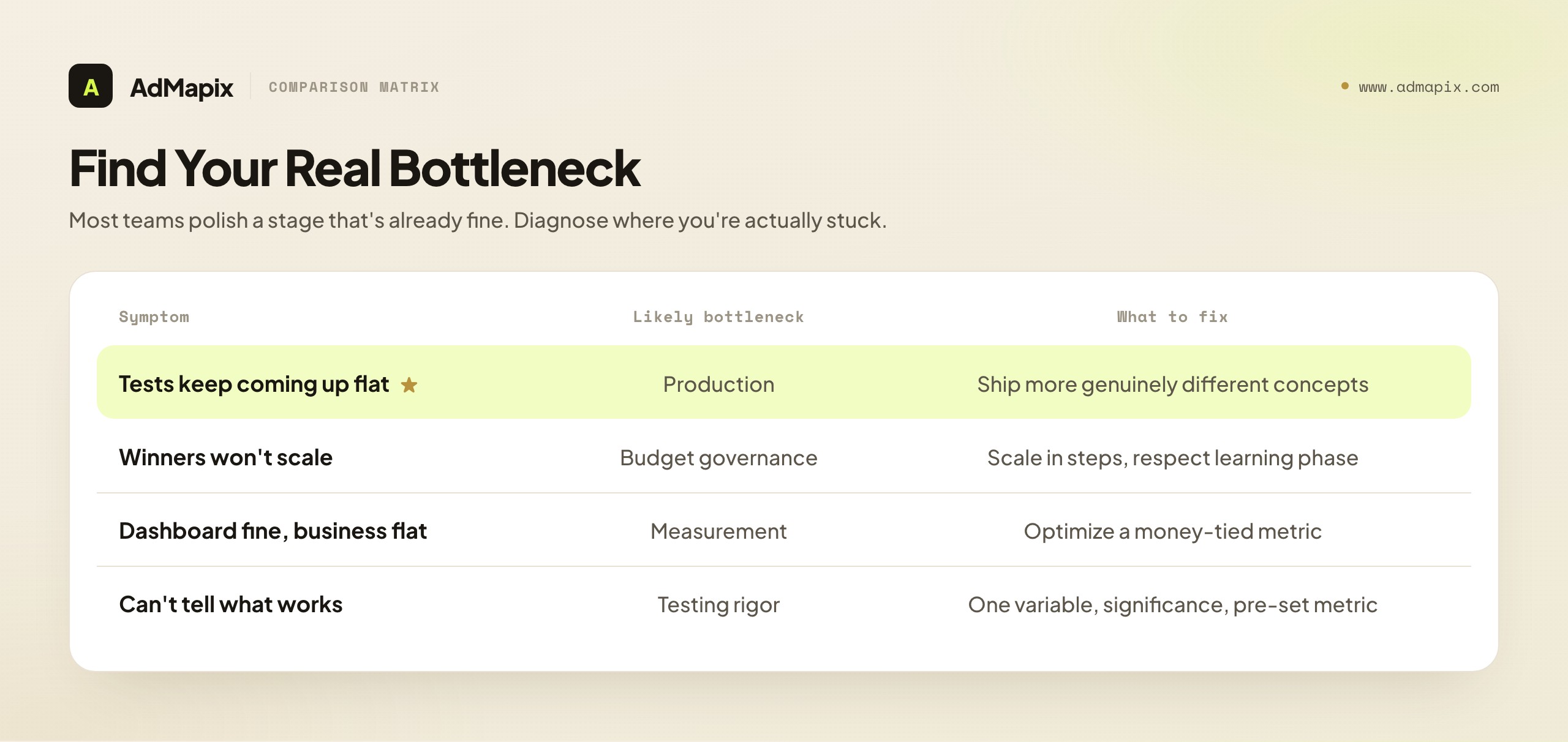
The diagnostic value of the loop is that it tells you where you're stuck. If your creative testing keeps coming up flat, the bottleneck might be production (not enough genuinely different concepts to test) rather than testing methodology. If your winners don't scale, the bottleneck is budget governance, not creative. If everything looks fine on the dashboard but the business isn't growing, the bottleneck is measurement — you're optimizing a metric that doesn't connect to money. Most teams obsess over one stage (usually testing tactics or bid strategy) while their real constraint sits elsewhere. Audit the whole loop, find the genuine bottleneck, and fix that. Optimizing a stage that isn't your constraint is motion without progress.
This is also why "best practices" lists that are just a bag of disconnected tips fail in practice. A tip about CTA copy is worthless if your constraint is that you only ship two ads a month. The practices below are organized as a system precisely so you can locate and attack your actual bottleneck rather than polishing the part that's already fine.
There's a deeper reason the loop framing matters: optimization compounds, and compounding only works when the cycle actually closes. A single isolated improvement — a better hook, a tighter audience — is a one-time gain. But a loop that ships verified learning every week means each cycle starts from a higher baseline than the last: this week's winner becomes next week's control, this week's tagged data sharpens next week's hypotheses, this week's freed budget (from killing losers) funds next week's tests. That compounding is the entire reason disciplined teams pull away from undisciplined ones over a year, even when they started with the same budget and the same platforms. The undisciplined team makes a string of one-time gains and plateaus; the disciplined team's baseline keeps ratcheting up. Optimization, done as a loop, is less like a series of clever moves and more like compound interest — boring per cycle, decisive over time. Keep that in mind every time a "quick win" tempts you to skip a stage; the quick win that breaks the loop costs more than it pays.
Part 1 — A High-Output Creative Production System
Creative fatigue is the silent killer of ad performance: across major platforms, a creative's effectiveness commonly degrades 30–40% after just 10–14 days of sustained exposure to the same audience. Yet many teams still produce reactively, refreshing only when click-through rates have already cratered — which means they're perpetually a step behind the decay curve. The fix is a modular, always-on production system that treats creative as a continuous output, not a series of one-off projects.

The foundation is the modular creative framework: instead of treating each ad as a unique production effort, break every creative into interchangeable components.
- Hook (0–3 seconds): the opening scene, headline, or motion that stops the scroll and states a stake.
- Value proposition / body (3–10 seconds): the core benefit, the proof, the demonstration that earns the attention the hook bought.
- Call to action (final frame or overlay): the conversion trigger — button copy, offer, urgency cue.
By versioning each layer independently, a team of two can produce 30+ genuinely distinct variants from a single core concept. Critically, modular production and clean testing reinforce each other: when the only thing that changed between two ads is the hook module, your test is automatically a clean one-variable experiment, so your results are interpretable. Modularity isn't just a speed hack; it's the production architecture that makes honest testing possible at volume.
Run production on a creative sprint cadence so output never depends on inspiration striking:
| Sprint week | Activity | Output |
|---|---|---|
| Week 1 | Concept ideation + script writing | 3–5 creative briefs |
| Week 2 | Production + editing (modular assets) | 15–30 ad variants |
| Week 3 | Launch + early-signal monitoring | Performance tagging |
| Week 4 | Kill underperformers, iterate on winners | 10–15 refreshed variants |
The discipline that pays off most: tag every creative with metadata at upload — format (static / video / playable), theme (UGC / product demo / testimonial), and hook type (question / pattern-interrupt / social proof / specific-number). This makes post-analysis dramatically faster and, more importantly, reveals which creative DNA drives your best performers. After a quarter of tagged data you can answer "do specific-number hooks beat question hooks for our cold audience?" with evidence instead of opinion — and that compounding library of what-works is one of the most durable assets a performance team can build. Untagged creative is a one-time spend; tagged creative is an investment that keeps paying as the dataset grows.
Where does the inspiration for new concepts come from? Partly your own winners, partly your team's ideas — and partly from what's running in your market. Tools that surface public ad creative (including AdMapix) give you a searchable, cross-network view of the hooks, formats, and offers competitors and category leaders are putting out, which is a rich source of hypotheses to test. The honest framing matters: you're mining the market for ideas to test in your account, not copying ads you assume are winners. We'll cover that limit in detail later, but note it here so you build the right habit from the start.
A balance worth getting right in production: iterate on winners and explore genuinely new concepts in parallel. Most of your output should be variations and refinements of what's already working — the cheapest, most reliable gains live in iterating a proven concept (a new hook on a winning body, a sharper proof beat, a localized cut). But a portion of every sprint must go to exploration — concepts that are different in kind, not just degree — because winners inevitably fatigue and a pipeline that only iterates will eventually have nothing fresh to iterate on. A useful split is roughly 70% iteration on proven concepts and 30% exploration of new ones; the exact ratio matters less than the discipline of always funding both. Teams that only iterate get very good at squeezing a dying concept; teams that only explore never compound a winner. You need both engines running, and the sprint cadence is where you enforce the balance instead of letting whichever feels urgent crowd out the other.
There's also a quality floor worth defending. Volume without a baseline of craft just produces more bad ads faster, which fatigues your audience and trains the algorithm on noise. Modular production should raise throughput without lowering the bar — each module (hook, body, proof, CTA) earns its place in the library by passing a test, so assembling from tested modules yields variants that are fast to make and already de-risked. The goal is high volume of viable creative, not high volume of creative. A team shipping thirty mediocre variants a month is not ahead of a team shipping eight strong ones; throughput only helps when the floor holds.
Part 2 — A/B Testing That Actually Moves the Needle
Most A/B testing in advertising is quietly broken. Teams run underpowered tests, declare winners too early off a lucky first day, and confound their results by changing several elements at once. The result is a team that feels data-driven while shipping noise. Honest testing rests on three non-negotiable rules.

Rule 1 — One variable per test. Always isolate a single change. If you swap the hook and the headline and the variant wins, you've learned nothing about which mattered — and you can't reuse the learning. Ranked by the average lift we typically see when isolated, the variables most worth testing are:
- Video hook (first 3 seconds) — the highest-leverage element by a wide margin; commonly the difference between a dead ad and a scaler.
- Headline / primary copy — strong influence on conversion once the hook earns the view.
- Creative format (video vs. static vs. playable) — often a large swing, and highly vertical-dependent.
- Offer / value framing — risk-reversal and specificity frequently beat raw discounts.
- CTA copy — a smaller but real lift, and cheap to test.
- Color / visual treatment — usually the smallest lever; test it last, after the big rocks.
The ranking is itself a best practice: test the high-leverage variables first. Teams that start by A/B testing button colors while their hook is broken are optimizing the rounding error. Fix the hook, then the headline, then work down.
Rule 2 — Test to statistical significance, not to your patience. Never call a winner below roughly 90% statistical confidence, and reach 95% before you scale real budget behind it. Early leads reverse constantly — a variant that's "up 40%" on day one with 800 impressions is telling you almost nothing. Set a minimum sample size per variant before you launch, and don't peek-and-stop the moment you like the number, because checking repeatedly and stopping on a favorable reading is one of the most common ways teams fool themselves into shipping a coin-flip.

Use sample-size guardrails as a floor, not a target — the noisier the metric and the smaller the true effect, the more data you need:
| Metric being tested | Minimum impressions per variant | Minimum conversions per variant |
|---|---|---|
| Click-through rate (CTR) | ~5,000 | N/A |
| Install rate / IPM | ~20,000 | ~100 installs |
| Conversion rate (CVR) | ~30,000 | ~100 conversions |
| Cost per acquisition (CPA) | Run to ~100+ conversions per variant | ~100 |
| ROAS | Often weeks of data + a full purchase cycle | Enough purchases to stabilize |
Rule 3 — Pre-register the metric and the threshold. Decide the success metric and the win threshold before you see any data. Picking the metric after the results are in — "well, it lost on CVR but it won on CTR, so let's call it a win" — is how motivated reasoning sneaks into a process that's supposed to be objective. Write down "this test wins if variant B beats A on CVR by ≥10% at 95% confidence over 30,000 impressions" before launch, and hold yourself to it. The whole point of testing is to constrain your own optimism; a test you can reinterpret after the fact constrains nothing. The deeper mechanics of designing clean experiments — sequential vs. parallel tests, holdouts, dealing with the platform's own optimization — live in the creative testing framework, which this section pairs with directly.
Part 3 — Budget Governance and Pacing
A proven winner only matters if you can scale it without breaking it, and a loser only stops costing you when you actually kill it. Budget governance is the set of rules that does both — and it's where discipline most often collapses into emotion. The two failure modes are mirror images: scaling too aggressively (which throws campaigns back into the unstable learning phase and tanks efficiency) and holding onto losers too long (hope is not a budget strategy).

Scale winners in measured steps. When a creative clears your testing bar, increase its budget gradually rather than 5x-ing it overnight. Large, sudden budget jumps reset the platform's optimization and push the campaign back into learning, where performance is volatile and expensive. A common, durable practice is to raise budget in increments of roughly 20–30% and then let the system re-stabilize before the next step. Patience here is counterintuitive but it's the difference between scaling a winner and detonating it.
Respect the learning phase. Modern ad platforms need a minimum volume of conversions before their optimization stabilizes — frequently cited as on the order of ~50 conversions per ad set per week. Below that, you're not seeing the ad's true performance; you're seeing noise from an algorithm that hasn't learned yet. Two implications follow. First, don't judge a campaign's verdict during learning. Second, don't make constant edits — every significant change can reset the learning phase, so a team that "optimizes" by tweaking something daily keeps their campaigns perpetually unstable and then blames the platform. Many "broken" campaigns are simply ones that were never allowed to exit learning.
Kill losers on pre-set thresholds. Define, in advance, the conditions under which an ad or ad set gets paused — e.g., "if CPA exceeds target by 50% after 100+ conversions, pause." Pre-committing removes the emotion ("but I love this creative") and the sunk-cost paralysis ("we've spent so much already"). The threshold should be tied to a metric that's stabilized, not a panic reaction to one bad day. Disciplined killing frees budget for testing, which feeds the loop. A team that can't kill its darlings starves its own engine.
Pace against your real constraint. If you're cash-constrained, optimize for CAC payback period (how fast you recoup acquisition cost). If you're growth-funded, you may tolerate longer payback for faster scale. Budget governance is downstream of your business model, not a universal formula. The "right" pacing for a bootstrapped DTC brand and a venture-backed app chasing market share are genuinely different, and copying the wrong one is a classic, expensive mistake.
Budget the test, not just the scale. A subtle governance discipline that pays off: reserve a fixed fraction of spend — commonly 10–20% — for testing, and protect it. When results are good, the temptation is to pour everything into the proven winners and stop testing; when results are bad, the temptation is to cut "non-essential" testing first. Both instincts are wrong, because they starve the very engine that produced (or could rescue) your performance. Testing budget is not discretionary; it's the R&D line that keeps your creative pipeline ahead of the decay curve. Treat it as a fixed cost of staying competitive, not a luxury you fund only when flush. The teams that survive a downturn in performance are the ones who kept testing through it and had fresh winners ready when the old ones fatigued.
Diversify so a single point of failure can't sink you. Concentration is efficient until the thing you concentrated on breaks — a single winning creative fatigues, a single platform changes its algorithm or your costs there spike, a single audience saturates. Governance includes maintaining enough breadth — a handful of viable creatives at any time, presence on more than one channel where it makes sense — that no single failure takes out your whole program overnight. This is in tension with consolidation (which argues for concentrating signal), and the resolution is to consolidate within a channel for the algorithm's benefit while keeping strategic diversity across creatives and channels. Efficiency and resilience both matter; the art is holding them in balance rather than maximizing one until the other breaks.
Part 4 — Account Structure and Hygiene: Consolidate for Signal
How you structure your account directly affects how well the platform's algorithm can learn — and in 2026, the dominant best practice has shifted decisively toward consolidation. Fragmenting your budget across dozens of tiny, hyper-segmented ad sets feels precise but starves each one of the conversion volume it needs to exit the learning phase. The modern algorithms are very good at finding the right audience if you give them enough signal per ad set — and you do that by consolidating, not by hand-slicing audiences into thin segments.

The practical guidance: prefer fewer, broader, well-funded ad sets over many narrow, underfunded ones. Let the platform's optimization do the audience-finding it's designed for, and concentrate your human effort on the creative and the offer — the levers you actually control and that actually move performance. Over-segmentation is a holdover from an earlier era of manual targeting; in the current environment it usually hurts, because every extra ad set divides your conversion signal and pushes more of your spend into perpetual learning.
Hygiene matters alongside structure. Keep a clean naming convention so you can actually analyze performance later (a campaign called "Test 4 final FINAL v2" tells you nothing in three months). Audit for audience overlap, where your own ad sets bid against each other and inflate your costs — a self-inflicted wound that's invisible unless you look for it. Prune dead campaigns rather than leaving them paused-but-cluttering. Maintain exclusions so you're not re-paying to reach people who already converted. None of this is glamorous, and that's exactly why it's neglected — and why the teams that do it have a quiet, durable edge over those that don't. Account hygiene is the flossing of performance marketing: boring, easy to skip, and quietly decisive over time.
A consolidation caveat worth stating plainly, because "consolidate" can be over-applied into its own mistake: consolidation is about giving each ad set enough conversion signal, not about cramming unrelated things together. Don't merge fundamentally different objectives, wildly different geos with different economics, or prospecting and retargeting into one undifferentiated blob just to chase the word "consolidated." The principle is enough signal per learning unit, and a learning unit should still be coherent enough that the algorithm is optimizing toward one sensible goal. Consolidate within a coherent objective and audience; keep genuinely different objectives separate. The failure mode at both extremes is the same — starved or confused learning — so the skill is finding the level of grouping where each ad set both has enough volume to learn and a clear, single thing to learn toward. That judgment, more than any rule of thumb about ad-set counts, is what separates clean account structure from cargo-culted "best practice."
Part 5 — Measure What Pays You, Not What's Easy to Move
The fastest way to optimize yourself into failure is to optimize the wrong metric. Upper-funnel metrics — CTR, CPM, impressions, even cost per click — are diagnostics, useful for understanding why something is or isn't working. They are not goals. A high CTR on an ad that doesn't convert is a more efficient way to lose money. The metrics that should govern your decisions are the ones tied to the business: return on ad spend (ROAS), customer acquisition cost (CAC) and its payback period, and ultimately contribution margin.

Here's the discipline. Pick one north-star efficiency metric that maps to how your business actually makes money — usually ROAS or CAC payback for performance accounts — and make every scaling and killing decision against it. Use upper-funnel metrics as a diagnostic ladder: if conversions are weak, walk up the funnel to find the break. Low CTR? The creative or targeting is off. Good CTR but low CVR? The landing page or offer is the leak, not the ad. Good CVR but bad ROAS? Your unit economics or audience quality is the problem, not the creative. The funnel metrics tell you where the problem is; the north-star metric tells you whether you have one.
Two honest caveats keep measurement from lying to you. Attribution is imperfect — platform-reported conversions, especially in a privacy-restricted, post-IDFA world, tend to over-credit the platform's own role, so triangulate platform numbers against your own analytics and, where you can afford it, incrementality testing (geo holdouts, lift studies). Don't bet the business on a single platform's self-graded report card. And beware the metric that's easy to move: if a metric responds instantly to a small tweak, it's often too far from the money to matter. The metrics that actually pay you tend to move slowly and stubbornly, which is precisely why they're the honest ones to optimize. A metric you can juice in an afternoon is usually a vanity metric in disguise.
A third caveat deserves its own emphasis because it bites teams that have otherwise done everything right: optimize for value, not just volume. Two campaigns can deliver identical CACs while one acquires customers worth twice as much over their lifetime. If your bidding and your reporting treat every conversion as equal, you'll happily scale the campaign that brings cheap, low-value customers and starve the one bringing expensive, high-value ones — and your CAC will look great while your business quietly weakens. Where the platform supports it, feed value signals (predicted LTV, purchase value, tiered conversion values) into your bidding so the algorithm optimizes for profitable customers, not just more customers. Even where it doesn't, segment your own analysis by customer value so you don't mistake a volume win for a margin win. The deepest, most durable optimization isn't lowering CAC — it's raising the value of what each acquisition dollar buys, and that only shows up in metrics close enough to the money to see it.
One more practical note on cohorts. Averages lie, especially in advertising, because a single blended ROAS or CAC hides wildly different sub-populations — new vs. returning, by geo, by creative theme, by acquisition week. The optimizers who consistently outperform look at cohorts, not just blended numbers: how did the customers acquired in week 12 pay back versus week 8? Did the specific-number-hook cohort retain better than the testimonial cohort? Cohort analysis is where you discover that your "best" campaign on a blended basis is actually carried by a small high-value segment and dragging in a lot of low-value volume — an insight invisible at the aggregate level and decisive once you see it. Build cohorting into your monthly review; it's the difference between optimizing what you can measure and optimizing what actually matters.
Part 6 — What Public Ad Evidence Can and Cannot Tell You
A complete optimization practice draws ideas from the market, not just from your own account — but only if you're honest about what market evidence can and cannot prove. This is the guardrail that keeps competitive inspiration from becoming expensive imitation.

From public ad evidence you can read: which creatives competitors and category leaders are running, the formats and placements they use, the hooks and offers and proof they've chosen, and roughly how long a creative has stayed live. That's a genuine, valuable source of hypotheses — "the leaders all switched to specific-number hooks; let's test that against our generic open." From public evidence you cannot read: a competitor's actual spend, their ROAS or conversion rate, their impressions or reach, the audience they targeted, or whether any given ad was a winner or a quietly-killed loser. The most tempting trap is longevity — "it's run for two months, so it must work" — but that's a soft signal, not proof. Ads run long because they win, because the account is neglected, or because they're brand placements judged on metrics you'll never see.
This is the exact lane where tools like AdMapix are clear about their scope. AdMapix gives you searchable, cross-network creative evidence — saved ad examples, video breakdowns, recurring reports — so you can see what's actually running across platforms in your category and harvest ideas to test. That's real value for the production and ideation stages of your loop. But AdMapix cannot show you a competitor's spend, ROAS, impressions, or targeting, because that data isn't public, and it doesn't claim to. Its strength is evidence of creative, not proof of performance. Build your optimization on that honest foundation: use market evidence to generate hypotheses, and use your own analytics to verify which ones actually pay. The optimization loop always closes inside your account, where performance is real — never in a competitor's library, where it's forever a guess. Treat a rival's long-running ad as confirmed truth and you'll eventually scale a copy of someone else's mistake.
Part 7 — Working With the Algorithm, Not Against It
In 2026 the platforms run on automation — automated bidding, broad targeting, dynamic creative, and budget optimization that shuffle spend across ad sets in real time. A huge share of "optimization" effort is wasted because teams fight these systems instead of feeding them. The shift in mindset is from manual control to signal management: you no longer hand-tune every bid and audience; you give the algorithm clean inputs, enough volume to learn, and the freedom to do what it's good at, then you concentrate your human judgment on the things the algorithm can't do — creative, offer, and strategy.

Three principles make this productive rather than helpless. First, feed the algorithm signal, not constraints. Every narrow audience, every exclusion, every tiny ad set is a constraint that reduces the system's room to optimize and slows its learning. Broad targeting plus strong creative usually beats narrow targeting plus mediocre creative, because the algorithm can find pockets of demand you'd never hand-segment. Second, optimize for the right conversion event. Automated bidding optimizes toward whatever event you tell it to — so if you optimize for clicks, you get clicks (and not necessarily customers). Point it at the deepest reliable event you have enough volume on, ideally purchase or a high-value action, so the system learns to find buyers, not browsers. Third, give it volume and stability. Automation needs conversion volume to learn and stability to converge; the same learning-phase discipline from budget governance applies — consolidate for volume, then stop poking it.
The crucial caveat: automation is powerful but not magic, and it optimizes ruthlessly toward the goal you set, which means a badly-set goal produces confidently-wrong results at scale. If your conversion event is mis-configured, your tracking is leaking, or your value signal is wrong, the algorithm will efficiently optimize toward garbage. So the human's job moves up the stack: get the measurement and the creative right, set the correct objective, and then trust the system to execute — while verifying its results against your own analytics, because the platform grading its own homework will always flatter itself. Working with the algorithm doesn't mean blind trust; it means dividing labor correctly. Let the machine do bid and audience optimization at a speed and scale no human can match, and reserve human judgment for creative, offer, objective-setting, and the honest measurement the machine can't be trusted to self-report.
A Worked Optimization Example, End to End
Let's run the full loop on a realistic account so the parts connect. Imagine you run UA for a subscription fitness app: budget is meaningful but not unlimited, your north-star is CAC payback (you need to recoup acquisition cost inside 60 days), and your current campaigns have plateaued — spend is flat, CAC is creeping up, and the team is "optimizing" by nervously tweaking bids every morning.
Diagnose the bottleneck first. Before touching anything, you walk the loop. Creative production: the team ships maybe four new ads a month — clearly thin. Testing: the few tests run change several things at once and get called after two days. Budget: winners get 5x'd impulsively and then crater. Measurement: the team optimizes to CPI (cost per install), a metric far upstream of CAC payback. So the diagnosis isn't "bids are wrong" — it's that every stage of the loop is weak, and the morning bid-tweaking is actively harmful because it keeps resetting the learning phase. The first decision is to stop the daily tinkering, which is making things worse.
Fix production. You stand up a modular system: one strong concept becomes a hook library, a body, and a few CTAs, and a two-person sprint now ships 20+ tagged variants a month instead of four. Creative is no longer the constraint. You seed the hook library partly from your own past winners and partly from a market scan of what category leaders are running — treating those as hypotheses to test, not ads to copy.
Fix testing. You move to one-variable tests with pre-set metrics and sample sizes. The first test isolates the hook: three new openers against the current generic one, on the same body, judged on day-3 trial-start rate at a pre-set sample, to 95% confidence. No peeking, no early calls. A clear winner emerges — a specific-number hook beats the generic open meaningfully.
Fix budget governance. Instead of 5x-ing the winner, you scale it in 25% steps, letting each step re-stabilize, and you respect the learning phase by not touching it between steps. You also finally kill three long-running losers the team had kept out of attachment, freeing budget for the next test round.
Fix measurement. You re-point automated bidding from CPI to the trial-start event (the deepest reliable event with enough volume), and you start reconciling platform-reported trials against your own analytics, which reveals the platform was over-crediting itself by a noticeable margin. Now decisions are governed by CAC payback, with CPI and CTR demoted to diagnostics.
The result and the lesson. Over a couple of cycles, CAC payback improves not because of one clever trick but because the loop started working: enough creative to test, honest tests, disciplined scaling, and the right metric. Notice that the highest-leverage move was the unglamorous one — stopping the daily bid-tweaking and fixing production throughput — not a bidding hack. That's almost always the shape of real optimization wins: find the genuine constraint, fix the system around it, and resist the urge to fiddle with the stage that was already fine.
The Optimization Cadence: Daily, Weekly, Monthly
All of the above only compounds if you run it on a rhythm. Heroic one-off optimization sprints feel productive and accomplish little; a sustained cadence is what separates teams that improve quarter over quarter from teams that re-discover the same lessons forever.

Daily — guardrail checks (10–15 minutes). Scan for anomalies, not for verdicts: spend pacing on track, no campaign spiking or flatlining, no obvious delivery break. The daily check is about catching fires, not making optimization decisions — judging a campaign daily is how you reset the learning phase and chase noise. Resist the urge to tweak; just make sure nothing's on fire.
Weekly — the optimization sprint (60–90 minutes). This is where decisions happen. Review tests that have reached significance and ship the verdicts. Scale winners a measured step. Kill losers that hit their thresholds. Pull the week's fresh creative ideas from your market scan and the previous batch's tagged-performance data, and queue the next round of one-variable tests. Leave the sprint with a clear set of actions taken and a ranked test queue for next week.
Monthly — the structural review (half a day). Zoom out from the week-to-week. Audit account structure for over-segmentation and audience overlap, prune dead campaigns, review your creative-DNA data for the patterns driving winners, reconcile platform-reported numbers against your own analytics, and grade your own hit-rate — what fraction of last month's tests actually produced a verified, shipped improvement? The monthly review is where you catch systemic drift the weekly sprint is too close to see.
The cadence is the meta-best-practice that makes every other practice durable. Skip the daily check and you miss fires. Skip the weekly sprint and decisions pile up and get made in panic. Skip the monthly review and structural rot accumulates invisibly until performance mysteriously erodes. Three time horizons, three different jobs — run all three and optimization stops being a thing you do when results dip and becomes a system that quietly compounds.
The hardest part of the cadence is not the work; it's the restraint it demands at the daily level. Performance marketers are wired to act, and a dashboard updating in real time is a slot machine that rewards fiddling with the illusion of control. The single most valuable habit the cadence enforces is doing nothing most days — letting tests run to significance, letting scaled campaigns re-stabilize, letting the algorithm learn — and saving real decisions for the weekly sprint when you have enough signal to make them well. A team that internalizes "the daily check is for fires, the weekly sprint is for decisions" will outperform a more talented team that optimizes anxiously every morning, because the anxious team is, without realizing it, sabotaging its own learning phases and chasing noise. Discipline, in optimization, often looks like patience — and patience is the rarest skill on most performance teams.
Common Optimization Mistakes (and the Fix)
Even teams that know the practices fall into the same traps. Naming them is cheaper than re-learning them in production.

- Optimizing the rounding error. Testing button colors while the hook is broken. Fix: attack high-leverage variables first; the hook before the headline before the CTA before the color.
- Calling winners on day one. Declaring victory off an early, lucky lead. Fix: pre-set sample sizes, reach 90–95% confidence, and never peek-and-stop.
- Scaling too fast. 5x-ing a winner overnight and resetting it into learning. Fix: scale in 20–30% steps and let it re-stabilize.
- Constant tinkering. Editing campaigns daily, keeping them perpetually in learning. Fix: make changes deliberately, then leave them alone long enough to learn.
- Over-segmentation. Splitting budget across dozens of thin ad sets that never exit learning. Fix: consolidate; give the algorithm signal.
- Optimizing the vanity metric. Chasing CTR or CPM instead of ROAS or CAC payback. Fix: pick a north-star tied to money; use funnel metrics as diagnostics only.
- Hoarding losers. Keeping creative you love because you love it. Fix: pre-set kill thresholds and honor them; free the budget for testing.
- Trusting platform attribution blindly. Betting the business on a platform's self-graded report. Fix: triangulate with your own analytics and incrementality tests.
- Treating competitor ads as answers. Copying a rival's long-running ad as if it's a proven winner. Fix: treat market evidence as hypotheses, verify in your own account.
Most underperformance is one or two of these, not an exotic failure. Run down the list before you conclude the platform changed or the market got harder — usually the call is coming from inside the house.
FAQ
What are the most important ad optimization best practices?
In priority order: build a high-output modular creative system so creative is never your bottleneck; test one variable at a time to statistical significance; govern budget with pre-set rules for scaling winners and killing losers; consolidate your account structure to feed the algorithm signal; and optimize to a money-tied metric (ROAS or CAC payback), not a vanity metric. Run all of it on a daily/weekly/monthly cadence. The system matters more than any single tip.
What's the single biggest lever in ad optimization?
Creative — specifically the hook. In account after account, creative explains far more of the performance variance than bid tweaks or audience micro-targeting, and the first three seconds of a video carry the most weight within creative. If you can only fix one thing, fix your creative production throughput and your hooks. Bid and audience optimization are real but second-order next to creative.
How long should I run an A/B test before calling a winner?
Until it reaches statistical significance against a pre-set sample size — never just until you're impatient. Don't call a winner below ~90% confidence, and reach ~95% before scaling budget behind it. As guardrails, that's roughly 5,000+ impressions per variant for CTR tests and ~100+ conversions per variant for CVR/CPA tests. Set the threshold before you launch, and don't peek-and-stop the moment the number looks good.
Why shouldn't I scale a winning ad quickly?
Because large, sudden budget increases reset the platform's optimization and throw the campaign back into the unstable, expensive learning phase. Scale in measured steps — commonly 20–30% increments — and let the system re-stabilize between steps. Patience preserves the efficiency that made the ad a winner in the first place; aggression detonates it.
Should I use broad or narrow targeting in 2026?
Lean broad and consolidate. Modern algorithms learn faster and target better with more conversion signal per ad set, so fragmenting budget across many narrow, hyper-segmented ad sets usually starves each one and traps your spend in perpetual learning. Concentrate budget into fewer, broader, well-funded ad sets, and put your human effort into creative and offer — the levers you actually control.
What metric should I optimize my ads toward?
The one tied to how your business makes money — usually ROAS or CAC payback period, ultimately contribution margin. Upper-funnel metrics (CTR, CPM, CPC) are diagnostics that tell you where a problem is, not goals to chase. A high CTR on an ad that doesn't convert is just an efficient way to lose money. Pick one north-star, govern decisions by it, and use funnel metrics only to locate breaks.
Can ad optimization tools show me what's working for my competitors?
They can show you what creative competitors are running — hooks, formats, offers, longevity — which is a great source of hypotheses to test. They cannot show you a competitor's spend, ROAS, impressions, or targeting, because that data isn't public. Treat market evidence as ideas to test in your own account (where performance is measurable), never as proof of what worked for them. Longevity is a soft signal, not a verdict.
What does AdMapix help with in an optimization workflow?
AdMapix gives you searchable, cross-network creative evidence — saved ad examples, video breakdowns, recurring reports — that feeds the ideation and production stages of your loop with what's actually running across platforms in your category. It's a hypothesis generator, not a performance oracle: it can't reveal competitor spend, ROAS, or targeting, and the only place your optimization decisions get verified is your own analytics.
How often should I be optimizing my campaigns?
On a cadence, not constantly. Daily: a 10–15 minute guardrail check for fires (not decisions). Weekly: a 60–90 minute optimization sprint where you ship test verdicts, scale winners, kill losers, and queue new tests. Monthly: a half-day structural review of account hygiene, creative-DNA patterns, attribution reconciliation, and your hit-rate. Optimizing constantly (daily tweaks) actually hurts by keeping campaigns in the learning phase.
Why do my campaigns perform worse right after I make changes?
Almost certainly the learning phase. Significant edits — budget jumps, audience changes, new creative at scale — reset the platform's optimization, and performance is volatile and inefficient until it re-learns (often needing ~50 conversions per ad set per week to stabilize). Make changes deliberately and then leave them alone long enough to exit learning. Many "broken" campaigns are simply ones never allowed to stabilize between constant tweaks.
Is creative fatigue real, and how fast does it set in?
Yes, and fast. Creative effectiveness commonly degrades 30–40% after just 10–14 days of sustained exposure to the same audience, and the decay has accelerated as ad volume and AI-generated variants have exploded. The defense is a modular, always-on production system that ships fresh creative continuously rather than reactively refreshing only after performance has already cratered. Production throughput, not cleverness, is what keeps you ahead of the decay curve.
Related Reading
Feed your testing with sharper creative ideas using the ad creative analysis scorecard, and run your experiments cleanly with the creative testing framework. For the competitive context that generates hypotheses, see the competitor ad analysis framework and the broader ad creative intelligence playbook. For tooling, compare the best ad spy tools for 2026 and the best ad intelligence tools.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Pathmatics Alternative in 2026: Ad Spend Intelligence vs. Creative Workflow
A complete 2026 buyer's guide to choosing a Pathmatics alternative — why teams look past Pathmatics (now Sensor Tower), what it actually measures, a layered comparison of spend-intelligence suites versus creative-workflow tools across coverage, data type, price, and fit, who should choose which, a practical migration plan, the honest limits of estimated spend, and where a lighter cross-network creative tool like AdMapix fits.

Moat Alternative in 2026: Ad Verification vs. Creative Intelligence
A complete 2026 buyer's guide to choosing a Moat alternative — why teams look past Oracle Moat, what Moat actually does (viewability, invalid traffic, brand safety), the critical split between the ad-verification layer and the creative-intelligence layer, a layered comparison across coverage and fit, who should choose which, a practical migration plan, the honest limits of public creative data, and where a creative-research tool like AdMapix fits.

Semrush Ad Intelligence Alternative in 2026: PPC Research or Creative Evidence?
A 2026 decision framework for choosing a Semrush ad intelligence alternative — when PPC keyword and spend research wins, when competitor creative and video evidence wins, how AdClarity fits, a fair-trial method, and how to build a two-layer stack.