Creative Testing Framework in 2026: Isolate, Prioritize & Scale Winning Ads
A 2026 creative testing framework — why confounded variables ruin most tests, how to isolate one variable per experiment, how to prioritize the backlog by impact and falsifiability, the test record that makes results reusable, how to read statistical significance and sample size without fooling yourself, the win/loss/flat decision rules, the testing-velocity question, how to scale winners and diversify the portfolio, and how competitor evidence feeds the hypothesis stage.

Creative Testing Framework in 2026: Isolate, Prioritize & Scale Winning Ads
By the AdMapix Research Team — Updated June 21, 2026
A creative testing framework is a repeatable system for deciding which ad ideas to test first, how to isolate what you're actually measuring, and what to do once a result comes in. It exists because most teams test the wrong way: they ship five creatives that differ on hook, offer, format, and audience all at once, then can't explain why one won — so they learn nothing reusable. In 2026, with creative the primary performance lever and creative fatigue compressing the value of every winner, the teams that win aren't the ones with the most creative; they're the ones with a system that turns each test into a reusable learning and each winner into a scalable asset. This guide is for creative strategists, performance marketers, agencies, ecommerce and SaaS teams, and founders who run their own ads. By the end you'll have a backlog scored by impact and confidence, a one-variable test design, an honest read on significance and sample size, and a decision rule for wins, losses, and inconclusive results.

We've watched teams run thousands of creative tests, and the difference between the ones that compound learnings and the ones that spin in place is never the quality of the ideas — it's the discipline of the system. A team with a one-variable design, a prioritized backlog, and pre-committed win conditions out-learns a team with better ideas and no system, every time. This guide is that system. It connects to two adjacent disciplines: our ad creative fatigue analysis guide for diagnosing when a creative needs replacing (which feeds the testing pipeline), and our paid ads analytics tools guide for the metrics and data-trust questions that grade a test's result. This guide is the testing engine between them.

TL;DR — Creative Testing Framework in One Screen
- Isolate one variable per test. A creative that changes hook, offer, and format at once produces an unattributable winner — you learn the bundle worked once, but can't reuse any component. One variable, everything else held against a control.
- Prioritize the backlog by impact and falsifiability, not by production ease. Run high-impact, easy-to-prove, low-effort tests first; park micro-tweaks until the big levers (hook, offer) are settled.
- Write the hypothesis and win condition before launch. Deciding the metric and threshold after seeing the data is how teams rationalize a flat result into a "win."
- Read significance and sample size honestly. Most creative tests are called too early on too little volume — an underfed test stays inconclusive forever, and a noisy early lead reverses.
- Every outcome needs a decision rule and an owner. Win, loss, and flat each lead to a specific next action; a test with no decision rule changes nothing.
- Scale winners deliberately. A winning concept isn't one ad — it's a vein to mine with variants, and a winner that's scaled and diversified is worth far more than one that's run once and left to fatigue.
- Competitor evidence feeds the hypothesis stage, never the result. You can see what competitors run repeatedly (a weak signal it earns its spend); you can't see their performance. Your own controlled test is the only proof.
What Most Teams Get Wrong Before They Start
The core failure of creative testing is confounded variables, not bad ideas. If a winning ad has a new hook, a new offer, and a new format, you've learned that the bundle worked once — but you can't reuse any single component with confidence, because you don't know which one carried it. A real framework forces you to name the one thing under test and hold everything else constant, so the result is attributable: you know exactly what won and can reuse it.
That constraint is also what makes the backlog tractable. Once a test maps to a single variable, you can stack-rank candidate tests by two things you can estimate before spending money: how much the variable could move your primary metric, and how cleanly a result would prove or disprove the hypothesis. Tests that are high-impact and easy to falsify go first. Without the one-variable discipline, the backlog is just a wishlist of full creatives with no way to prioritize and no way to learn from the results.
There's a deeper reason the discipline matters in 2026: because creative fatigues fast (see our fatigue analysis guide), you'll be refreshing constantly — and a refresh informed by attributable learnings ("problem-first hooks beat feature-first for our cold audience") is a confident bet, while a refresh informed by an unattributable winner ("that one ad worked, let's make more like it… somehow") is a guess. The whole value of testing is the reusable learning, and confounded variables destroy reusability. Isolate the variable, and every test compounds into knowledge; confound the variables, and every test is a one-off lottery ticket.

The One-Variable Framework
Use a single variable per test and decide the win condition before launch. The table below is the canonical structure of one test — pick the dimension, change only it, hold everything else constant against a control, and define the win signal upfront.
| Dimension | What you change | Hold constant | Win signal | Decision if it loses |
|---|---|---|---|---|
| Hook | First 1-3 seconds / first line | Offer, format, audience, landing page | Higher hold rate or CTR vs. control | Archive hook, keep current opener |
| Offer | Discount, bundle, guarantee, free tier | Hook, format, audience, landing page | Higher CVR at equal or better CPA | Retest with clearer value framing |
| Format | UGC vs. studio, static vs. video, aspect ratio | Hook, offer, audience, landing page | Better cost per result on target placement | Keep current format, retest later |
| Proof | Reviews, demo, before/after, social proof | Hook, offer, format, audience | Higher CVR or lower bounce on landing | Try a different proof type |
| CTA / landing path | Button copy, destination, page match | Hook, offer, format, audience | Higher CVR with stable upstream CTR | Fix message-match before retesting |
The dimensions aren't equal in leverage, which is why prioritization (next section) matters. The hook and the offer are the highest-leverage variables — they move the primary metric most — so they're where you test first and hardest. Format is moderate leverage and often channel-specific. Proof and CTA/landing path are lower-leverage refinements that matter once the big levers are settled. The discipline is the same across all of them: change one, hold the rest, define the win signal before you launch, and decide the loss action in advance. A test designed this way produces a result you can act on and reuse; a test that changes several dimensions at once produces a result you can only admire.

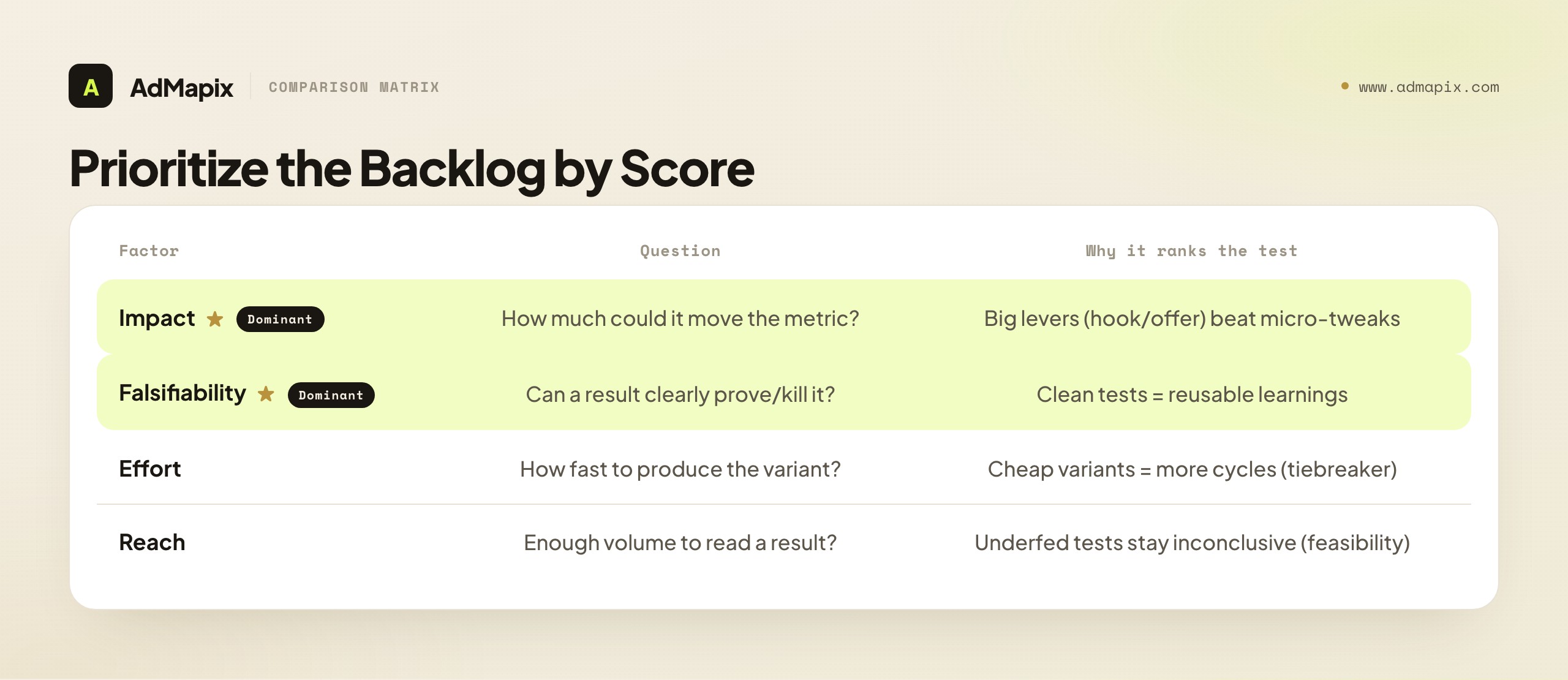
How to Prioritize the Backlog
Score each candidate test, then sort — the point is to spend the next test budget where it teaches you the most per dollar, not where production is cheapest. A scored backlog is what turns a pile of creative ideas into a sequenced testing plan.
| Factor | Question to answer | Why it ranks the test |
|---|---|---|
| Impact | If this wins, how much could it move the primary metric? | High-leverage variables (hook, offer) usually beat micro-tweaks |
| Confidence to falsify | Can a result clearly prove or kill the hypothesis? | Clean tests produce reusable learnings; muddy ones waste spend |
| Effort | How long to produce the variant? | Cheap, fast variants let you run more cycles |
| Reach | Will the audience get enough volume to read a result? | Underfed tests stay inconclusive forever |
A simple working rule: run high-impact, high-confidence-to-falsify, low-effort tests first. Park low-impact micro-tweaks until the big levers (hook and offer) have been settled, because optimizing a button color on a creative whose hook doesn't land is wasted motion — you're polishing a frame nobody stays to see.
The scoring doesn't need to be elaborate. A 1-5 rating on impact and falsifiability, multiplied (or just summed), gives you a priority score that sequences the backlog. The two factors that should dominate are impact (test the big levers first, because a hook win is worth more than a CTA win) and falsifiability (test the clean experiments first, because a muddy test that can't produce an attributable result wastes the budget). Effort and reach are tiebreakers and feasibility checks — a high-impact test you can't produce or can't feed enough volume drops in priority not because it's unimportant but because it's not runnable yet. The output is a ranked list: the next test is always the highest-scoring runnable one, which removes the recurring "what should we test next?" debate from every planning meeting.
A practical note on scoring discipline: the goal of the score isn't precision, it's sequencing. You don't need the score to be exactly right — you need it to reliably float the high-impact, easy-to-prove tests to the top and sink the low-impact micro-tweaks. So resist over-engineering the scoring model; a quick 1-5 on impact and falsifiability, eyeballed, is enough to produce a usable sequence. The failure mode isn't an imprecise score — it's no score, which leaves the team testing whatever's easiest to produce or whatever the loudest person suggested, both of which systematically under-test the high-leverage levers (because hooks and offers are often harder to produce than a button-color tweak). The discipline the scoring enforces is the one that matters most: test the things that could move the metric a lot before the things that could move it a little, even when the big-lever tests are more work. A team that scores its backlog — even crudely — and tests in score order will reach a stronger creative position than a team with better individual ideas that tests in convenience order, because the scored team spends its budget on the questions that matter while the convenience-ordered team optimizes the margins. Score crudely, sequence rigorously, and the backlog becomes a plan instead of a wishlist.
Test Methods: A/B, Sequential, and Why Multivariate Usually Backfires
Once you've committed to one variable per test, there's still a methodology choice — how you actually run the test — and picking the right method for your volume keeps you from either over-engineering or under-powering the experiment. The three common methods suit different situations, and the most sophisticated-sounding one is usually the wrong choice for creative.
- A/B (the default). One variant against a control, splitting the audience, measured on the primary metric. This is the workhorse of creative testing because it's clean, attributable, and readable at modest volume. For most teams, most of the time, A/B is the right method — it directly answers "did changing this one variable help?"
- Sequential (when volume is tight). When you can't afford to split the audience (a small audience or budget), you run the control for a period, then the variant for a comparable period, and compare. It's noisier than a true split (because conditions change over time — seasonality, auction shifts), so it's a fallback for low-volume situations, not a first choice. Read sequential results with extra caution because the time confound is real.
- Multivariate (usually a trap for creative). Testing many combinations of multiple variables at once (hook × offer × format) sounds efficient but almost always backfires in creative testing: it requires enormous volume to read all the combinations, it reintroduces the confounding the one-variable discipline exists to prevent, and it produces results most teams can't act on. Multivariate has a place in high-volume conversion-rate optimization with simple elements, but for creative — where each cell is a full ad needing real volume — it fragments your budget across too many under-fed cells. Stick to sequential one-variable tests instead.
The practical guidance: A/B test one variable against a control as your default, fall back to sequential testing only when volume forces it (and read those results cautiously), and resist the multivariate temptation for creative. The goal is a clean, attributable, adequately-powered result — and a series of clean A/B tests delivers that far more reliably than one ambitious multivariate test that fragments your budget and reintroduces the confounding you worked to avoid. Simpler methods, run in sequence, beat complex methods run once — the elegance you want is in the discipline of the design, not the sophistication of the statistics.
Concept vs. Execution: What Layer Are You Actually Testing?
A subtle but crucial distinction in creative testing is whether you're testing a concept (an angle, a strategy) or an execution (a specific rendering of a concept) — because confusing the two leads to wrong conclusions about what won or lost. Knowing which layer you're testing tells you what a result actually proves.
The two layers and why the distinction matters:
- Concept-level testing asks "does this angle work?" — does a problem-first hook beat a feature-first hook, does a bundle offer beat a discount, does UGC beat studio. A concept-level result is broadly reusable: if problem-first hooks win, that's a strategic learning that informs many future creatives.
- Execution-level testing asks "is this specific rendering better?" — does this particular problem-first hook beat that particular one, both within the same proven concept. An execution-level result is narrower: it tells you which of two executions of an already-proven concept is stronger, useful for optimizing a winner but not for strategy.
The mistake teams make is reading an execution result as a concept result, or vice versa. If a specific problem-first hook loses to a specific feature-first hook, that doesn't necessarily mean problem-first concepts lose — it might mean that particular execution was weak. A single execution's failure doesn't kill the concept; you'd need several executions of a concept to fail before concluding the concept doesn't work. Conversely, one execution winning doesn't prove the concept — it might be a strong execution of a mediocre concept.
The practical discipline: test concepts first (the high-leverage strategic question — which angle works), establish the winning concepts, then test executions within the proven concepts (the optimization question — which rendering is strongest). This sequencing means you settle the strategy before optimizing the tactics, which is the right order — there's no point optimizing executions of a concept that doesn't work. And when you read a result, ask which layer it's at: a concept-level win is a strategic learning to build many creatives on; an execution-level win is a refinement of an existing winner. Confusing the layers leads to abandoning good concepts because of a weak execution, or over-generalizing from a single execution's win — both expensive errors the concept-vs-execution distinction prevents.
The Test Record That Makes Results Reusable
Every test needs a written record so the result is usable next quarter, not just this week — and the discipline of writing it before launch is what stops teams from rationalizing a flat result into a win. A test without a written hypothesis and a pre-committed win condition isn't an experiment; it's a hope with a budget.
The minimum a test record needs, captured before the test launches:
- Hypothesis. A falsifiable statement: "A problem-first hook will out-hold a feature-first hook for cold traffic." Not "let's try a problem-first hook" — a prediction you can prove wrong.
- Variable under test. The single dimension changing (hook, first 3 seconds). Everything else identical to the control. Naming it forces the one-variable discipline.
- Control. The current best creative the variant runs against. Without a clear control, there's nothing to measure the result against.
- Primary metric and tiebreaker. The one metric that decides the test (3-second hold rate), plus a tiebreaker (CTR). Picking the metric upfront prevents metric-shopping after the data lands.
- Win condition. The pre-committed threshold: "Problem-first beats control on hold rate at the volume we can afford." Decided before launch, not after.
- Decision rule. What happens on win, loss, and flat — each leads to a specific action: win → promote and spin variants of the winning angle; loss → archive the angle, keep control; flat → extend the test or rule it inconclusive, never ship.
- Evidence and owner. The source examples that generated the hypothesis, the asset, format, date, metric context, and a caveat — plus the named owner who builds the next variant or writes the report.
The two fields that do the heavy lifting are the hypothesis and the win condition, both committed before launch. They're what convert a vague "let's see what happens" into a real experiment with a falsifiable prediction and a decision rule — which is the entire difference between testing that compounds into knowledge and testing that produces a folder of inconclusive results nobody can interpret. Write the record before you spend, and the result is reusable; write it after, and you'll talk yourself into whatever conclusion you wanted.

Reading Significance and Sample Size Without Fooling Yourself
The most common way creative tests go wrong after a clean design is being called too early on too little volume — so reading significance and sample size honestly is what separates a real result from a coin flip you over-interpreted. Most "winning creative" calls are made before the test had enough data to mean anything, and the early lead reverses as often as not.
The honest principles for reading a test result:
- Underfed tests stay inconclusive. A test needs enough volume — impressions, clicks, conversions — for a difference between the variant and the control to be distinguishable from noise. A test split across too small an audience, or stopped after a day, simply can't produce a trustworthy result. Reach is a precondition, not a nice-to-have.
- Early leads are noisy and often reverse. In the first hours or days, the variant and control bounce around because the sample is small. A variant that's "winning" on day one frequently loses by day three as the sample grows. Don't call a winner on an early lead; wait for the result to stabilize.
- The metric closer to the conversion needs more volume. A hold-rate or CTR test reads faster (those events are frequent); a CVR or CPA test needs far more volume because conversions are rarer. Match your patience to the metric — a creative test on a downstream conversion metric needs more spend and time than one on an upstream engagement metric.
- Significance isn't certainty. Even a "significant" result has a probability of being noise; a single significant test is evidence, not proof. The strongest learnings come from results that replicate — a hook angle that wins across several tests is far more trustworthy than one that won once.
The practical discipline: decide upfront how much volume the test needs to read (tied to the metric and the effect size you'd care about), don't call the winner until the test hits that volume and the result stabilizes, and treat a single significant result as evidence to be confirmed rather than proof to bet the account on. This is where the testing framework connects to measurement — for the data-trust grading that tells you how much to believe a test result, see our paid ads analytics tools guide. The teams that test well aren't the ones that run the most tests; they're the ones that don't fool themselves about which results are real.

Decision Rules: Win, Loss, and Flat
A test only matters if win, loss, and flat each lead to a specific next action and an owner — so the decision rules are what turn a result into progress rather than a number nobody acts on. The most under-specified part of most testing programs is what happens after the result, especially for the two outcomes teams hate to face: the loss and the flat.
The three outcomes and their rules:
- Win. The variant beat the control on the primary metric at sufficient volume. The action: promote the winner and mine the winning angle — spin variants of the same hook, offer, or format that won, because a win is a vein to explore, not a single ad to run. A win that isn't mined for variants leaves most of its value on the table.
- Loss. The variant lost to the control. The action: archive the angle (so you don't re-test it) and keep the control. A loss is a real learning — you now know that angle doesn't work for this audience, which is reusable knowledge. The mistake is treating a loss as a failure rather than a learning; a clean loss is a successful test.
- Flat / inconclusive. No meaningful difference, or insufficient volume to tell. The action: either extend the test to gather more volume (if the hypothesis is high-value and underfed) or rule it inconclusive and move on (if it ran enough and genuinely tied). The critical rule: a flat result does not ship — shipping a variant that didn't beat the control just churns creative for no gain. Most rationalized "wins" are actually flats that someone wanted to ship.
The discipline that makes decision rules work is committing them before launch and assigning an owner to execute them. A win with no one assigned to mine the variants leaves value unrealized; a loss with no one archiving the angle gets re-tested; a flat with no rule gets rationalized into a ship. The decision rule plus the owner is what closes the loop from "we got a result" to "we did something with it" — and a testing program that doesn't close that loop is just generating numbers, not compounding into a creative advantage.

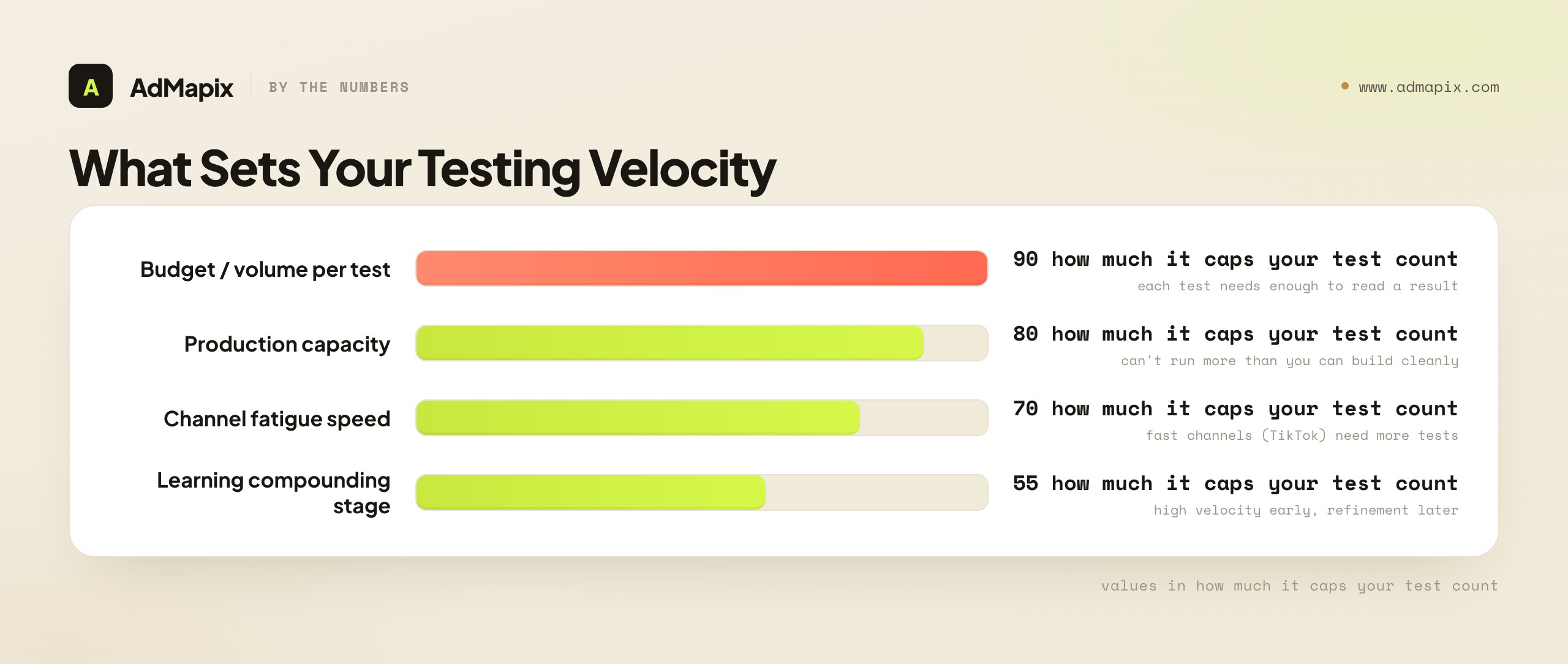
Testing Velocity: How Many Tests, How Often
How fast you test — your testing velocity — is one of the biggest determinants of how quickly you find and scale winners, so deciding the right cadence is a strategic choice, not just an operational one. More tests mean more learnings and more winners, but only if each test is clean and adequately fed, which is the tension velocity has to balance.
The factors that set the right testing velocity:
- Channel fatigue speed. A TikTok-heavy account fatigues fast (see the fatigue guide), so it needs a high testing velocity to keep a pipeline of fresh winners ready. A Google Search account fatigues slowly and needs less. Match velocity to how fast your channels burn creative.
- Budget and volume. Each test needs enough volume to read a result, so your total budget caps how many tests you can run simultaneously without underfeeding them. Running too many tests on too little budget produces a backlog of inconclusive results — fewer, well-fed tests beat many starved ones.
- Production capacity. Velocity is also limited by how fast you can produce clean variants. A team that can ship one hook variant a week can't run a ten-test-a-week program; the production pipeline (informed by the creative ads library) sets the ceiling.
- The learning compounding rate. Early on, when the big levers are unsettled, high velocity on high-impact tests compounds learnings fast. Later, as the levers settle, velocity shifts toward refinement and refresh. The right velocity changes as the account matures.
The strategic synthesis: testing velocity is the throttle on how fast your creative program improves, but it has to be balanced against test quality — a high velocity of confounded, underfed tests produces noise, while a steady velocity of clean, well-fed tests compounds into a creative advantage. The goal isn't maximum tests; it's the maximum clean, adequately-fed tests your budget and production can support. Size your velocity to that constraint, weight it toward the high-impact levers early, and the testing program becomes a machine that reliably produces winners faster than the competition.
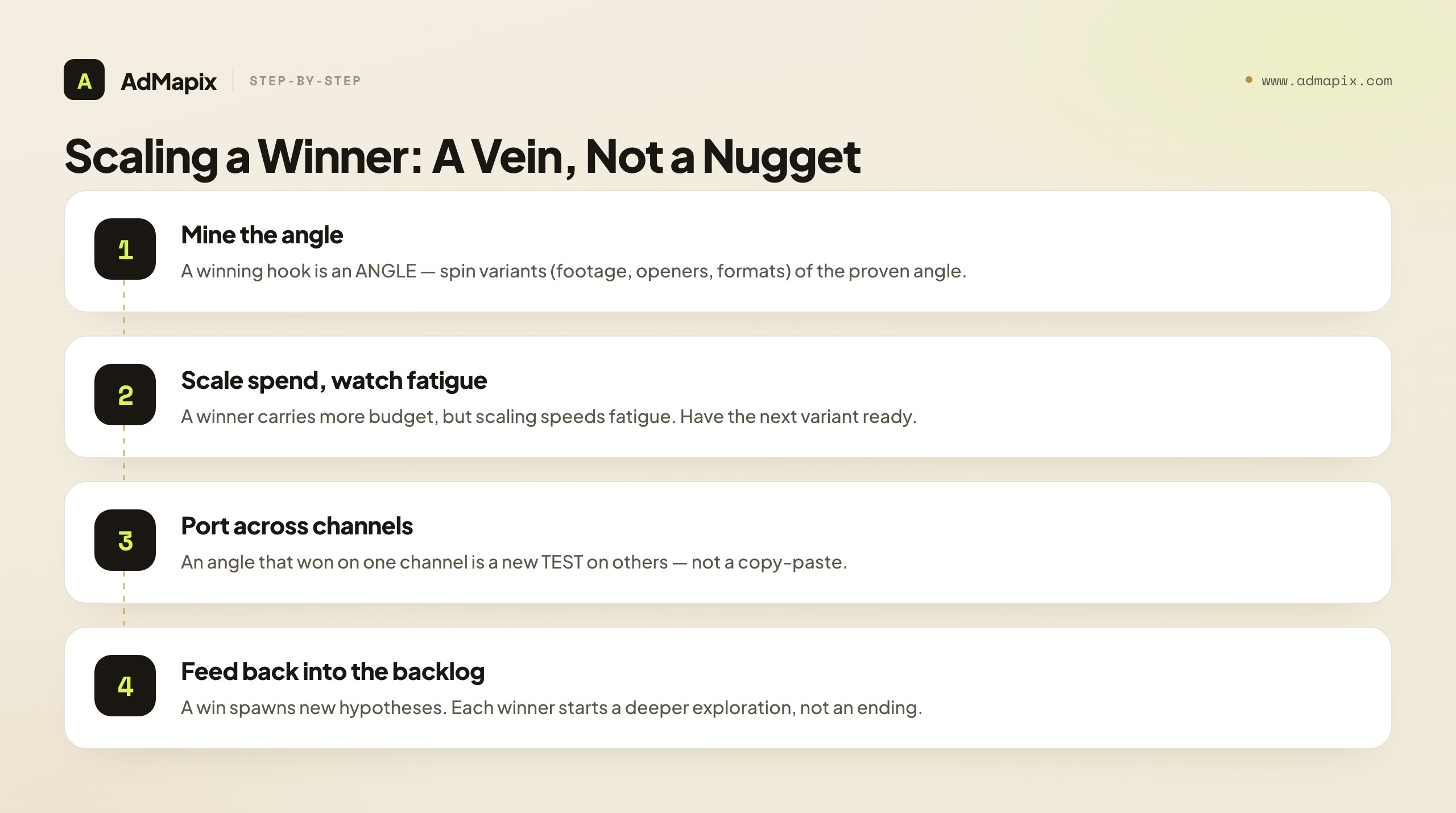
Scaling Winners: A Win Is a Vein, Not a Nugget
Finding a winning creative is only half the value — the other half is scaling and mining it, because a winner that's run once and left to fatigue captures a fraction of what a deliberately scaled and diversified winner does. The teams that win treat a winning concept as a vein to mine, not a single nugget to spend.
How to extract the full value of a winner:
- Mine the winning angle for variants. A winning hook isn't one ad — it's an angle that works, so spin multiple executions of it (different footage, different openers within the same angle, different formats). Each variant extends the winner's life and finds the strongest execution of the proven angle.
- Scale the spend deliberately, watching for fatigue. A winner can carry more budget, but scaling spend accelerates frequency and fatigue (see the fatigue guide). Scale into a winner while watching the fatigue signals, and have the next variant ready before it tires.
- Port the winning angle across channels. An angle that won on one channel is a hypothesis worth testing on others — but as a new test (channels behave differently), not a copy-paste. Cross-channel porting extends a winner's reach.
- Feed the winner back into the backlog. A winning angle generates new hypotheses ("if problem-first hooks win, which problems?"), so a win should spawn the next round of tests rather than ending the inquiry. The best testing programs treat each win as the start of a deeper exploration.
The strategic point: the value of a creative testing framework isn't just finding winners — it's extracting the full value from each one. A team that finds a winner and runs it once until it fatigues has captured maybe a third of its value; a team that mines the angle for variants, scales the spend while managing fatigue, ports it across channels, and feeds it back into the backlog captures the rest. Scaling winners is where testing connects to portfolio strategy: a few well-mined winning veins, scaled and diversified, beat a constant churn of one-off winners. The framework's payoff is a portfolio of scaled, proven angles — not a folder of ads that each won once and were forgotten.
A Worked Example: Testing a Hook Hypothesis End to End
Principles stick when applied, so here's how the framework runs on a single hypothesis from generation to scaled winner. Say you sell a sleep supplement and your best current creative leads with a feature ("our formula has 5 clinically-studied ingredients").
Generate the hypothesis (competitor evidence + your own data). Researching competitors, you notice several are running problem-first hooks ("still waking up at 3am exhausted?") rather than feature-first. That's a weak signal worth testing — not proof. You write the hypothesis: "A problem-first hook will out-hold our feature-first hook for cold traffic." It's falsifiable, names the variable (hook), and predicts a direction.
Prioritize it. You score it: impact high (the hook is the highest-leverage variable), falsifiability high (a clean one-variable test against your current best), effort low (a hook swap on existing footage), reach adequate (your prospecting audience has volume). High-impact, high-falsifiability, low-effort — it goes to the top of the backlog.
Design the test. One variable: the hook (first 3 seconds), everything else identical to the control (your feature-first creative). Primary metric: 3-second hold rate, tiebreaker CTR. Win condition, pre-committed: "Problem-first beats control on hold rate at the volume we can afford." Decision rule: win → mine the problem-first angle for variants; loss → archive, keep feature-first; flat → extend or rule inconclusive, don't ship. This is a concept-level test (does the problem-first angle work), not an execution test.
Run and read it honestly. You launch the A/B split and resist calling it on day one — the early lead is noisy. By day four the sample is adequate and the result has stabilized: the problem-first hook holds at a meaningfully higher rate. You hit your pre-committed volume and the result is stable, so it's a real concept-level win, not an early-lead artifact.
Decide and scale. Per your decision rule, you don't just promote the one winning creative — you mine the angle. The problem-first concept won, so you spin execution variants: different 3am-wakeup framings, different problem moments, the same concept rendered several ways. You scale spend into the winner while watching frequency for fatigue (per the fatigue guide), and you feed the win back into the backlog as new hypotheses ("if problem-first wins, which specific problems hold best?"). One clean test produced a reusable concept-level learning, a scaled winner, a set of execution variants, and the next round of tests — which is the framework working as a compounding system, not a one-off, and which no amount of ad-hoc creative churn could replicate.
Building the Testing Operating System
A creative testing framework only delivers its full value when it's run as a standing operating system — a regular cadence, a maintained backlog, clear ownership, and a learnings log — rather than an occasional burst of tests. The framework is the method; the operating system is the habit that applies it consistently, and consistency is where the compounding happens.
The components of a testing operating system:
- A maintained, scored backlog. A living list of test hypotheses (fed by competitor research, your own wins, and platform guidance), each scored on impact and falsifiability, always sorted so the next test is the highest-scoring runnable one. The backlog removes the "what do we test next?" debate and ensures you're always testing the highest-leverage open question.
- A regular testing cadence. A standing rhythm — weekly or per sprint — for launching new tests, reading results, and making decisions, sized to your testing velocity. The cadence is what turns testing from a sporadic reaction into a reliable engine.
- Clear ownership. Someone owns the backlog (prioritization), someone owns test design and execution, someone owns reading results and making the decision. Unowned testing drifts; assigned ownership keeps the loop closing.
- A learnings log. A durable record of what every test proved — which concepts won, which lost, which executions were strongest — so the team builds institutional knowledge rather than re-testing settled questions. The learnings log is the compounding asset: over a year, it becomes a map of what works for your audience that no competitor has.
The strategic synthesis: the difference between a team that has a testing framework and a team that has a testing operating system is the difference between knowing the method and reliably applying it. A framework on a slide changes nothing; an operating system — backlog, cadence, ownership, learnings log, run consistently — compounds every test into a durable creative advantage. Over months, the operating system produces a team that knows what works for its audience with evidence behind every claim, a portfolio of scaled proven winners, and a backlog that's always pointing at the next highest-leverage question. That compounding knowledge is the real payoff of creative testing — not any single winner, but a system that reliably produces winners faster than the competition can. For the swipe-to-test backlog that feeds this system, see our creative ads library guide. The teams that build this operating system stop being at the mercy of whether their next creative happens to work, because they've turned creative success from a gamble into a process — and a process that compounds, test by logged test, into a durable, evidence-backed advantage no competitor can shortcut.
What Competitor Evidence Can and Cannot Prove
Competitor ad libraries and public creative are excellent for generating hypotheses and terrible for proving they work. You can see that a competitor is running a particular hook, format, or offer, and that they keep running it — which is a weak signal it earns its spend. You cannot see their CTR, conversion rate, CPA, audience, or whether the creative is profitable or just stuck in an unoptimized campaign.
So competitor evidence feeds the hypothesis column, never the result. Seeing a competitor run a problem-first hook repeatedly is a reason to test a problem-first hook, not proof that it'll win for you — your audience, offer, and product are different, so the only proof is your own controlled test. This is the correct division of labor: competitor research (covered in our how to spy on competitors' ads guide) generates a rich, market-informed backlog of hypotheses, and your own one-variable tests confirm which ones work for you. Official platform guidance reinforces structured iteration over random changes: Google's ad variations feature is built to test specific changes like a headline or call-to-action across campaigns, and Google's responsive search ads guidance frames Ad Strength as forward-looking feedback on assets rather than a performance guarantee. For short-form video, TikTok's creative best practices recommend native vertical 9:16 assets with sound and visible content in safe zones — itself a format hypothesis worth testing, not a proven outcome. Treat every external signal, platform guidance included, as a hypothesis your own test confirms.

The Testing Roadmap: Sequencing the Whole Program
Beyond prioritizing individual tests, a mature program sequences the whole testing roadmap — moving deliberately from the big strategic levers to the fine refinements — because testing in the wrong order wastes budget optimizing tactics before the strategy is settled. The sequence matters as much as the individual scores.
The right sequence for a testing program:
- First, settle the big levers (concept-level). Test hooks and offers at the concept level — which angle, which offer structure works for your audience. These are the highest-leverage questions, and until they're settled, everything downstream is built on an unproven foundation. A program that optimizes button colors before settling its hook strategy is polishing a frame nobody stays to see.
- Second, optimize within the winning concepts (execution-level). Once you've established which concepts win, test executions within them — which problem-first framing holds best, which bundle presentation converts. This is refinement of a proven foundation, valuable but secondary to the concept questions.
- Third, refine the supporting elements. Proof types, CTAs, landing-page message-match — the lower-leverage variables that matter once the high-leverage ones are settled. These produce smaller gains, so they come after the big levers are won.
- Continuously, refresh against fatigue. Throughout, the fatigue guide's diagnosis triggers refreshes, which the testing pipeline supplies from pre-tested variants. The roadmap isn't linear — refresh runs continuously alongside the staged optimization.
The strategic point: a testing program has a natural order — concept before execution, big levers before refinements — and following it means your budget always goes to the highest-leverage open question rather than to a minor optimization on an unproven foundation. Teams that sequence wrong (refining executions of a concept they never validated, optimizing CTAs on a hook that doesn't hold) waste their testing budget on the margins. Teams that sequence right settle the strategy first, then optimize the tactics, then refine the details — and they reach a far stronger creative position with the same budget. The roadmap is the meta-prioritization on top of the per-test scoring: it ensures the whole program moves in the right order, not just that each individual test is well-chosen.
Statistical Traps That Quietly Ruin Tests
Even a well-designed, adequately-fed test can produce a wrong conclusion if you fall into one of a handful of common statistical traps — so recognizing them is the last layer of discipline that keeps your learnings real. These traps are subtle because they produce confident-looking results that happen to be wrong.
The traps to watch for:
- Peeking and early stopping. Checking the test repeatedly and stopping the moment it looks significant inflates your false-positive rate — if you check often enough, random noise will eventually look significant by chance. The fix: decide the volume upfront and read the result once it's reached, rather than peeking and stopping at the first favorable wobble.
- The multiple-comparisons problem. If you test many variants at once and pick the best, some will look like winners by pure chance — test twenty creatives and one will "win" on noise alone. The fix: be skeptical of a winner pulled from a large pool, and confirm it in a follow-up test rather than scaling it on the first result.
- Ignoring the base rate / regression to the mean. A creative that performed exceptionally in a small early sample tends to regress toward average as the sample grows — the extreme early result was partly luck. The fix: distrust extreme early results and wait for them to stabilize, because the apparent superstar often regresses to merely fine.
- Survivorship in the learnings log. If you only remember the tests that won, your learnings log overstates what works. The fix: log losses and flats too, so the record reflects the true hit rate (which is usually a minority of tests — most tests don't produce a clear winner, and that's normal).
- Confusing statistical significance with practical significance. A result can be statistically significant but too small to matter — a 0.1% CTR improvement that's "significant" on huge volume isn't worth acting on. The fix: decide upfront what effect size would actually change a decision, and ignore significant-but-trivial results.
The unifying discipline: these traps all stem from wanting a result more than wanting the truth, and the antidote is committing to the test parameters (volume, effect size, single read) before launch and respecting them after. A team that decides upfront how much volume it needs, reads the result once, logs every outcome including losses, and ignores trivially-small wins produces learnings it can trust. A team that peeks, cherry-picks, over-reacts to early extremes, and only remembers wins produces a learnings log full of false positives that lead to confident, wrong creative bets. The statistics aren't hard; the discipline of not fooling yourself is — which is the same lesson the analytics data-trust hierarchy teaches, applied to test results. Wanting the truth more than wanting a win is, in the end, the whole discipline of creative testing.
Common Creative Testing Mistakes
- Changing more than one variable per test. A multi-change winner teaches you nothing reusable. Isolate the hook, the offer, or the format — never all three at once.
- Deciding the win condition after seeing the data. Write the metric and threshold before launch, or you'll talk yourself into shipping a flat result.
- Calling winners too early on too little volume. Early leads are noisy and often reverse; wait for the test to hit adequate volume and stabilize before deciding.
- Treating a competitor's running ad as proof. Longevity hints at spend, not at profitability or conversion rate — it's a hypothesis, not a result.
- Underfeeding tests. If the audience is too small to read a result, the test stays inconclusive and you've burned budget for no learning. Fewer, well-fed tests beat many starved ones.
- No decision rule for losses or ties. A test only matters if win, loss, and flat each lead to a specific next action and an owner.
- Shipping flat results. A variant that didn't beat the control just churns creative for no gain. Flat does not ship.
- Finding a winner and not mining it. A win is a vein to explore, not a nugget to spend once. A winner run once and left to fatigue captures a fraction of its value.
When to Use AdMapix
AdMapix fits the discovery and evidence half of this framework — after you've decided what variables matter and before you spend money testing them. Use Search to find competitor ads by network and angle, Media to save the examples that become hypotheses, Video Analysis to break down hook timing, pacing, and motion in winning videos, and Reports to turn a recurring set of saved examples into a shareable backlog of test hypotheses. Compare workflows on Pricing or jump straight to Login once spreadsheets and screenshots stop scaling.
It's built for teams who run frequent creative tests across networks and need searchable, taggable evidence and recurring reports to feed the hypothesis stage. It's not a campaign manager, an analytics platform, or a substitute for your own test results: it won't tell you a competitor's CPA or predict your ROAS, and it doesn't run the A/B test for you. AdMapix sits at the hypothesis-generation end of the framework — it makes your backlog richer and more market-informed, so the tests you prioritize and run are better bets. The testing, the significance read, and the decision stay yours. If you only ship one or two creatives a quarter, a folder of screenshots is probably enough.
FAQ
What is a creative testing framework?
It's a repeatable system for choosing which ad ideas to test first, isolating one variable per test, deciding in advance what a win, loss, or inconclusive result means, and scaling the winners. The goal is attributable, reusable learnings — knowing exactly what won so you can reuse it — not a single lucky winner you can't explain or replicate.
How many variables should I test at once?
One. If you change the hook, offer, and format together, a winner is unattributable and the components aren't reusable — you've learned the bundle worked once, not which part carried it. Isolate a single variable, hold everything else constant against a clear control, and only then move to the next test. The one-variable discipline is what makes every result reusable knowledge.
How do I decide which test to run first?
Score each candidate by expected impact (how much it could move the primary metric) and falsifiability (how cleanly a result would prove or kill the hypothesis), then factor in production effort and audience reach as feasibility checks. Run high-impact, easy-to-falsify, low-effort tests first; park micro-tweaks like button color until the big levers — hook and offer — are settled. The next test is always the highest-scoring runnable one.
How do I know when a test result is real?
Wait for enough volume to distinguish the result from noise, and don't call a winner on an early lead — early leads are noisy and often reverse as the sample grows. Match your patience to the metric: hold-rate and CTR read faster, while CVR and CPA need far more volume. And treat a single significant result as evidence to confirm, not proof to bet on — the strongest learnings replicate across several tests.
What should I do when a test result is flat?
A flat result does not ship. Either extend the test to gather more volume if the hypothesis is high-value and was underfed, or rule it inconclusive and move on if it ran enough and genuinely tied. The most common testing mistake is rationalizing a flat result into a "win" and shipping a variant that didn't actually beat the control, which just churns creative for no gain.
Can a creative testing framework predict performance?
No. It improves prioritization and the quality of what you learn, but it can't predict spend, ROAS, or conversion rate without your own live test data. Public competitor evidence generates hypotheses; platform guidance suggests formats to test; but only your own controlled results prove what works for your audience, offer, and product.
How do I scale a winning creative?
Treat the win as a vein, not a nugget. Mine the winning angle for variants (different executions of the same proven hook or offer), scale the spend deliberately while watching for fatigue, port the winning angle to other channels as new tests, and feed it back into the backlog as a source of new hypotheses. A winner run once and left to fatigue captures a fraction of the value a deliberately scaled and diversified winner does.
How fast should I run creative tests?
Match your testing velocity to your channel fatigue speed (fast-fatiguing channels like TikTok need more tests), your budget and volume (each test needs enough to read a result, so budget caps simultaneous tests), and your production capacity (you can't run more tests than you can produce clean variants for). The goal isn't maximum tests — it's the maximum clean, adequately-fed tests your constraints allow, weighted toward high-impact levers early.
How does competitor ad research fit the framework?
It feeds the hypothesis stage. Seeing which hooks, offers, and formats competitors run repeatedly is a weak signal worth testing, but it's never proof — you can't see their performance. Use saved competitor examples to write better, more market-informed hypotheses, then validate them with your own controlled tests. Competitor research makes your backlog richer; your own tests make it true.
What's the difference between creative testing and fatigue analysis?
Fatigue analysis diagnoses when a creative's performance has dropped because the audience tired of it (covered in our fatigue analysis guide) — it's a diagnostic. Creative testing is the system that produces and validates the next creative, including the refreshes fatigue analysis calls for. They connect: fatigue analysis flags the need for a refresh, and the testing framework supplies the proven, pre-tested variant to refresh with. One diagnoses; the other produces.
Related Reading
- Ad Creative Fatigue Analysis: Signals, Thresholds & Refresh Decisions — diagnosing when a creative needs the refresh this framework produces.
- Paid Ads Analytics Tools: Metrics, Stack & Data Trust — the metrics and data-trust grading that read a test's result.
- Ad Hook Examples: 7 First-3-Second Patterns — the hook variants to populate your highest-leverage tests.
- Creative Ads Library: Build a Swipe-to-Test System — the backlog of hypotheses that feeds the testing pipeline.
- How to Spy on Competitors' Ads in 2026 — generating the market-informed hypotheses you test.
- Ad Budget Optimization Framework — allocating budget to the winners testing identifies.
Sources
- Google Ads ad variations — ad variations let you test specific changes such as headlines or calls-to-action across campaigns.
- Google responsive search ads best practices — Ad Strength is described as forward-looking feedback on assets, not a performance guarantee.
- TikTok creative best practices — recommends native vertical 9:16 assets, sound on, and content inside safe zones.
- Meta Ads Library — the public archive for sourcing competitor creative that becomes test hypotheses.
Official source links checked as of June 21, 2026. Platform features and recommendations change, so verify each URL before relying on it in an operating playbook. AdMapix surfaces cross-network ad creatives to feed test hypotheses; it doesn't expose competitor CPA or spend, and it doesn't predict your own performance outcomes — only your controlled tests do.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Ad Hook Examples in 2026: 7 First-3-Second Patterns (with UGC Breakdowns)
A complete 2026 library of ad hook examples organized into seven repeatable patterns — problem, proof, objection, comparison, curiosity, offer, and transformation — with UGC hook breakdowns, platform-by-platform differences for TikTok, Meta, and YouTube, an industry-by-industry hook map, a hook-testing workflow that ships variants, the metrics that actually grade a hook, and a worked teardown that turns a competitor opener into a running test.

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.
Outbrain Ad Spy Tool in 2026: Native Ad Research for the Open Web
How to research Outbrain native ads from public evidence in 2026 — what a spy tool can and cannot prove, how to decode headline-and-thumbnail hooks, advertorial landing paths, retargeting trails, and how to turn patterns into testable native campaigns.