Playable Ad Analysis for Mobile Games: A Practical Method
A practical method for playable ad analysis in mobile games: how to reverse-engineer a competitor's playable by the job it is built to do, decode its structure beat by beat, infer which concepts are likely working, turn observations into testable briefs, and stay honest about what a public playable proves (structure and intent) versus what it never can (spend, installs, retention, ROAS).

Updated June 21, 2026 — written and reviewed by the AdMapix Research team.
Playable Ad Analysis for Mobile Games: A Practical Method

If you run user acquisition (UA) for a mobile game, playable ads can feel like a black box. You can see that competitors are using them, you can sometimes test them yourself, and you can tell they require more production effort than a static or a standard video. But the hard part is knowing how to do playable ad analysis in a way that leads to better decisions — not just a swipe file full of screenshots. This guide is for UA managers, creative strategists, and growth teams who want a practical method: how to break down what a competitor is showing, how to infer which playable concepts are likely working, and how to turn those observations into testable briefs for your own team.
Playable ad analysis is worth doing well because playables are the most signal-rich and the most expensive-to-build format in mobile-game UA. A static can be approximated in a day; a playable requires design, animation, logic, quality assurance (QA), and platform-specific packaging, so most teams cannot afford to build many random versions. They need stronger hypotheses before production starts — and rigorous analysis of competitor playables is how you get them. For neighboring reading, start with the playable ads guide, the playable ad examples library, and the creative testing framework.

TL;DR — A Method for Playable Ad Analysis
- Start with the job, not the surface. Identify what the playable is built to do — demonstrate the loop, qualify users, create a competence moment, open a curiosity gap, or sell a fantasy — before judging any detail.
- Decode the structure beat by beat: time-to-interaction, whether the first action teaches the core loop, the guidance level, the difficulty curve, the win/fail moment, and where the call to action (CTA) appears relative to the player's sense of competence.
- Performance lives in the structure, not the skin. Teams that copy theme, art, and reward screens get weak results; the real drivers are how fast the user interacts, what the first action teaches, and when the CTA lands.
- Playables expose intent. A playable reveals what the advertiser believes is the fastest path from cold user to install consideration — making it the most valuable format to study, even though it is the hardest to copy.
- Mechanic-match is the highest-stakes read. Because the player actually does the demonstrated action, a playable that mismatches the real game produces especially visible day-1 churn.
- Turn analysis into briefs, not clones. Extract the structural hypothesis and rebuild it for your game with an honest mechanic decision; do not pixel-copy a competitor's playable.
- A public playable proves structure and intent, never results. You cannot see spend, installs, retention, or ROAS. Use the analysis to form strong hypotheses; let your own funnel decide.
Why Playables Demand a Different Kind of Analysis
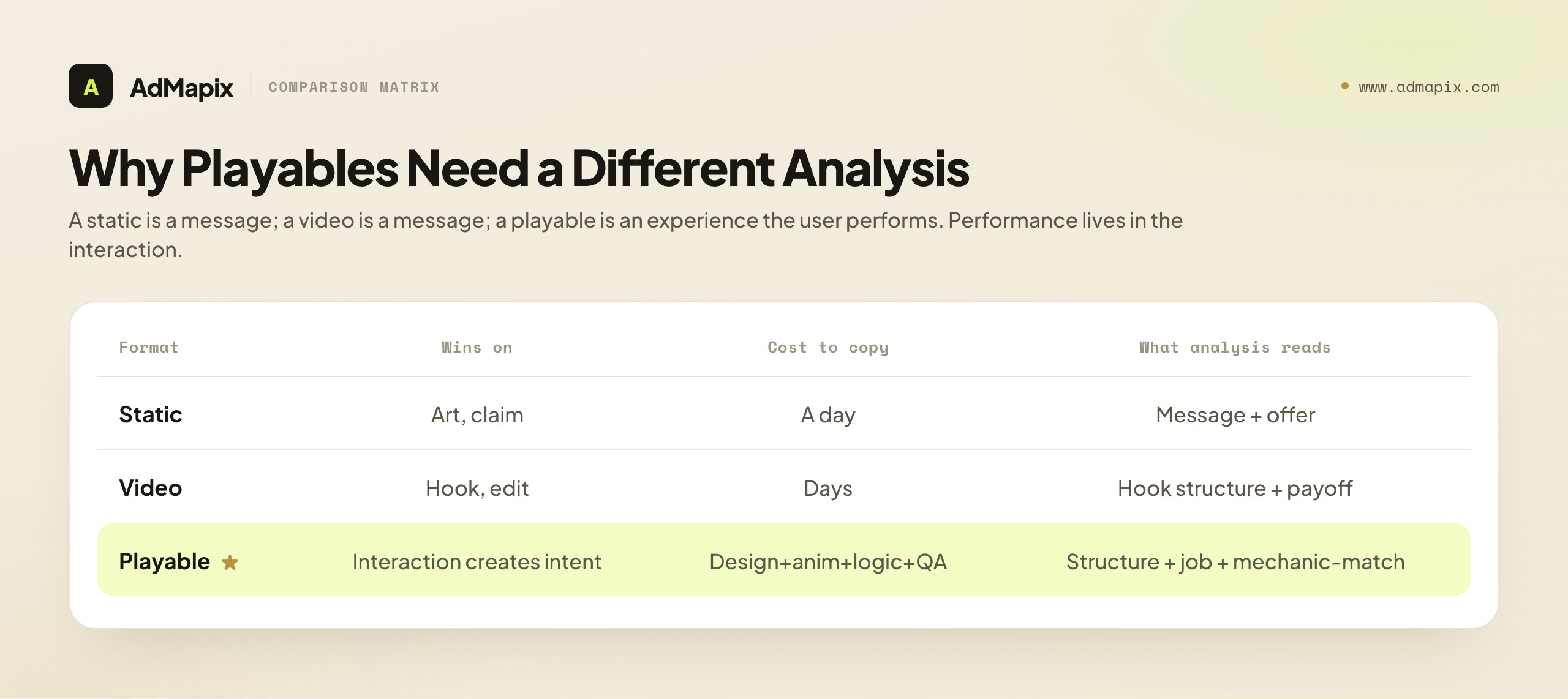
Playable ads are different from static and video creatives because they are not just messages — they are mini product experiences. A static ad can win because the art style is sharp or the claim is strong. A video can win because the hook is clear and the edit keeps attention. A playable wins or loses on those factors too, but it also depends on whether the interaction itself creates intent. The user does not just watch a promise; they perform a small version of the game and decide, from how that felt, whether to install.
That difference matters enormously for analysis. When teams treat playables like videos, they copy surface elements — the same theme, the same fail/win moment, the same reward screen, the same visual style — and usually produce weak results, because the real performance driver is deeper in the structure: how quickly the user reaches interaction, whether the first action teaches the core loop, whether the difficulty spikes at the right moment, and whether the CTA appears just after the player feels competent. Two playables with identical art and themes can perform completely differently because one nails the interaction structure and the other does not. Surface copying misses exactly the thing that drives performance.
Playables are also harder to copy well, which changes the economics of analysis. A competitor's static can be approximated in a day; a playable usually requires design, animation, logic, QA, and platform-specific packaging across networks. That means most teams cannot afford to build many random versions and learn by brute force — they need stronger hypotheses before production starts. Rigorous playable ad analysis is how you earn those hypotheses cheaply, by reading what competitors have already invested in building, rather than by paying to rediscover it yourself.
The upside is that playables are more signal-rich than most ad formats. When you analyze one properly, you can extract clues about the advertiser's acquisition strategy, target audience, gameplay positioning, and likely performance intent. A playable exposes what the advertiser believes is the fastest path from cold user to install consideration — which makes it one of the most valuable creative formats to study, despite (and because of) the effort it takes to build.
Consider why a playable is so much more revealing than a static or a video. A static reveals a message and an offer. A video reveals a hook, an edit, and a payoff. But a playable, because it is a compressed product experience, reveals the advertiser's entire theory of conversion: what they think the first thing a user should do is, how much they trust the mechanic to sell itself, how much hand-holding they think the audience needs, where they believe install intent peaks, and whether they are willing to misrepresent the game to win a cheaper click. Each of those is a strategic decision, made deliberately and at real production cost, and each is legible in the structure. No other ad format encodes this many strategic decisions in a form you can directly observe. That is the deep reason playable analysis repays the effort: you are not reading a creative, you are reading a strategy.
There is one more reason the format rewards careful study: because playables are costly, advertisers do not make them casually. A studio that has invested in building and iterating a playable has, by that very act, told you the concept matters enough to fund — which makes the existence of a polished, iterated playable a stronger signal of intent than the existence of a cheap video. The effort barrier that makes playables hard to copy is the same barrier that makes them honest signals: you rarely waste a playable budget on a concept you do not believe in. Reading playables is therefore reading the concepts advertisers were willing to bet production money on.
Step 1: Start With the Job the Playable Is Trying to Do
Before looking at any detail, identify the playable's primary job. Not every playable tries to do the same thing, and judging a playable's details without knowing its job leads you to overvalue features that are not central to its performance. A rough-looking playable may still work brilliantly if its real job is to qualify users for a highly specific core mechanic — and you would dismiss it if you judged it on polish.
A mobile-game playable is usually optimized for one of five jobs:
- Demonstrate the core loop quickly — show, hands-on, what the game actually is, as fast as possible.
- Filter for qualified users by requiring an interaction similar to real gameplay, so only users who like the real mechanic engage.
- Create a competence moment where the player feels "I get this, I'm good at this" and wants to continue.
- Open a curiosity gap around progression, upgrades, or challenge — make the player want to see what comes next.
- Sell a fantasy or genre expectation more than exact gameplay accuracy — lean into the feeling the genre promises.
These jobs are not mutually exclusive — a strong playable often stacks two (a competence moment that also demonstrates the loop) — but one is usually primary. To find it, ask: what user action does the playable push me toward within the first few seconds? Is it showing the real game loop, a simplified version, or a fake-but-adjacent loop? Does it seem designed to maximize completion (heavy guidance, guaranteed success) or to qualify (lighter guidance, real difficulty)? The answers tell you the job, and the job tells you which details to weigh and which to ignore.
This first step is the one most analysts skip, and skipping it is why so much playable analysis produces noise. Once you name the job, every later observation has a frame: a feature either serves that job or it does not, and you can stop being distracted by polish that is irrelevant to the playable's actual purpose.

Step 2: Decode the Structure Beat by Beat
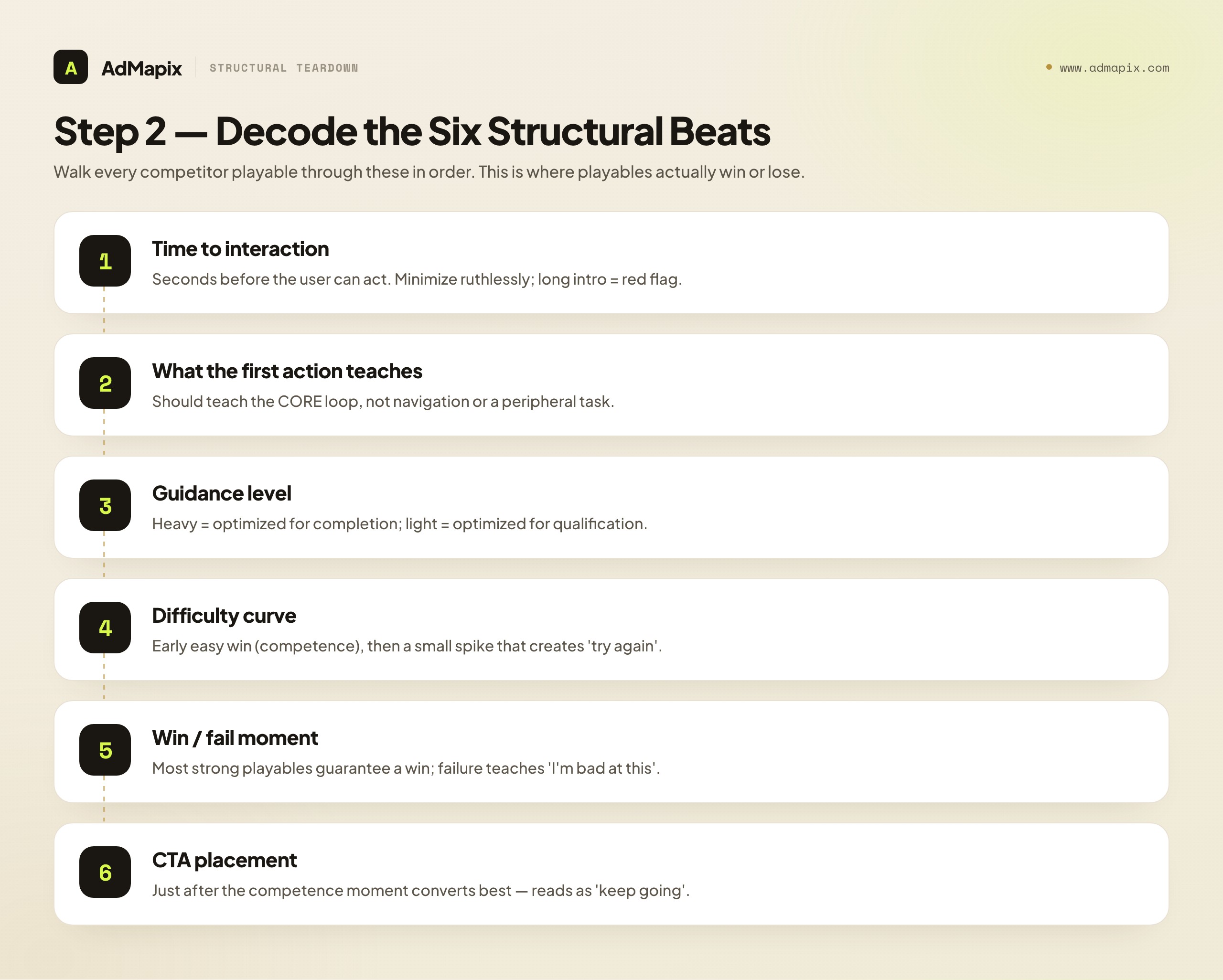
With the job identified, walk the playable's structure in order. These are the load-bearing beats — the places where playables actually win or lose — and each is a distinct thing to observe and, later, to test.
Time to interaction. How many seconds before the user can do something? The strongest playables minimize this ruthlessly, because every passive second before the first interaction is a second the format's advantage is wasted. A long logo, a cinematic intro, or a tutorial wall before the first tap is usually a red flag — note it, because it is often the single most copyable improvement.
What the first action teaches. Does the first interaction teach the core loop, or something peripheral? The best playables make the very first action the central mechanic, so the user learns the game by playing it. A first action that teaches navigation, or a non-core mini-task, wastes the most valuable moment of attention.
Guidance level. How heavily is the player guided — a finger hint, a glowing target, an on-rails path, or near-total freedom? Heavy guidance signals the advertiser is optimizing for completion (get everyone to the end and the CTA); light guidance signals they are optimizing for qualification (let the real mechanic filter). Neither is wrong; the guidance level tells you which job the playable is really serving.
The difficulty curve. Where does difficulty rise? A well-built playable usually delivers an early, easy win (the competence moment), then a small spike that creates "I want to try again" tension, timed so the CTA arrives when the player feels both competent and slightly challenged. A flat curve (too easy throughout) creates no intent; a wall (too hard early) loses the player.
The win/fail moment. Does the playable let the player succeed, fail, or both? Most strong playables guarantee a win, because failure in a demo teaches the user they are bad at your game. Some deliberately use a controlled near-fail to create tension before a guided recovery. Note which, because it reveals the emotional engineering.
CTA placement. Where does the install prompt appear relative to the player's sense of competence? The highest-converting placement is just after the competence moment, when the player feels good and wants to continue — the CTA reads as "keep going," not "stop and install." A CTA that arrives too early (before competence) or too late (after the feeling fades) leaks intent.
Walk every competitor playable through these six beats and log each. Within a handful of analyses you will have a structured, comparable record — the raw material for inference and, later, for briefs. This is the heart of playable ad analysis: the structure, read in order, is where the performance lives.
A practical tip on how to decode at this level of detail: you usually need to play the competitor's playable yourself, repeatedly, paying attention to one beat per pass. The first pass, just play it naturally and note your gut reaction — when did you feel competent, when did you want to install, when did you get bored? Subsequent passes isolate each beat: time the interaction with a stopwatch on one pass, watch only the guidance cues on another, watch only where the CTA appears on a third. Trying to observe all six beats in a single play is how analysts miss the subtle ones. The beats are simple to name and surprisingly easy to overlook in real time, so deliberate, single-focus passes are the discipline that separates a real decode from a vague impression.
It also helps to record each decode in a consistent template — one row per playable, one column per beat, plus job and mechanic-match. A consistent record is what makes the next two steps (inference and briefing) possible; an inconsistent pile of notes is not analyzable. The format is less important than the consistency: the same beats, captured the same way, every time, so that twenty decodes become a comparable dataset rather than twenty impressions.
What the Structure Reveals About Strategy and Audience
A well-decoded playable is a window into the advertiser's strategy, because every structural choice is a decision about who they want to acquire and how fast they want to convert them. Reading these inferences is where playable ad analysis becomes genuinely strategic, beyond a structural checklist.
Guidance level reveals the acquisition posture. Heavy guidance — finger hints, glowing targets, an on-rails path — signals the advertiser is optimizing for completion volume: get as many users as possible to the CTA, accepting that some are not a perfect fit. Light guidance signals optimization for qualification: let the real mechanic filter, accepting lower completion in exchange for users who genuinely like the loop. So the guidance level alone tells you whether a competitor is playing a volume game or a quality game on that creative — a meaningful read into their UA strategy.
Time-to-interaction reveals confidence in the mechanic. An advertiser who hands you control in under a second is confident the mechanic itself will sell the game. One who front-loads cinematic or narrative before the first tap is betting the fantasy or story matters more than the loop — common for narrative-heavy or RPG titles, where the world is part of the pitch. The interaction speed is a tell about what the advertiser believes is their game's strongest selling point.
Mechanic-match reveals the funnel trade-off. As covered below, an exact-match playable signals a quality-and-retention bet; an unrelated one signals a volume-and-completion bet with an accepted retention tax. Reading the match tells you which side of the CTR-versus-retention trade the advertiser has chosen for that creative.
Difficulty and win/fail reveal the target player. A playable tuned to guarantee an easy win for everyone targets a broad, casual audience. One that allows real challenge or a controlled near-fail targets users who want difficulty — a different, often more committed player. The difficulty design is a signal about which audience the advertiser is courting.
Put together, a single decoded playable lets you infer the advertiser's acquisition posture (volume vs quality), their belief about their game's strongest pitch (mechanic vs fantasy), their funnel trade-off (completion vs retention), and their target player (broad-casual vs challenge-seeking). None of this is certain — it is inference from structure — but it is far richer intelligence than a screenshot, and it is exactly the kind of read that turns analysis into a strategic advantage rather than a swipe file.
Step 3: Infer Which Concepts Are Likely Working
Analysis is not just description; it is inference. Once you have decoded structure across many playables, you can form hypotheses about which concepts are likely working — carefully, because inference from public signals is probabilistic, not certain.
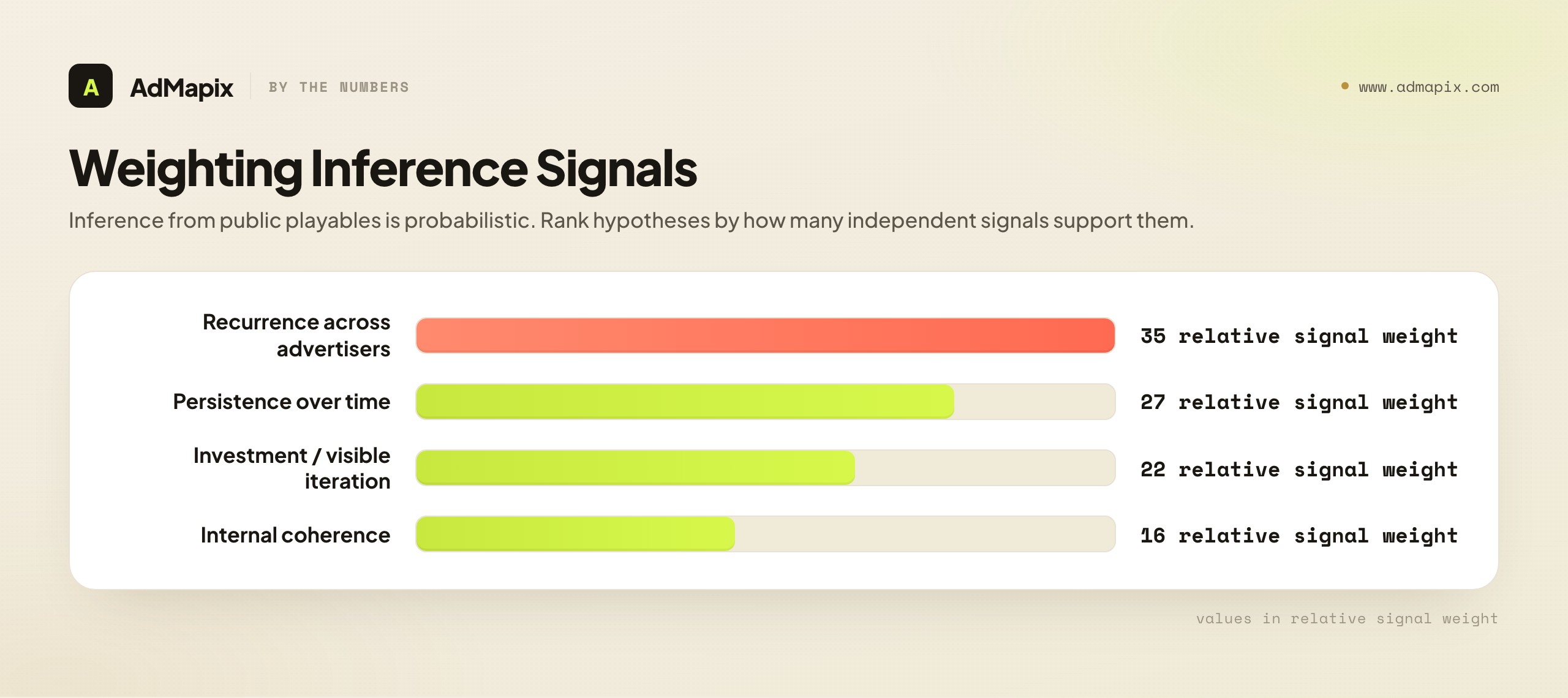
The strongest inference signal is recurrence and persistence across advertisers. When the same structural choice — say, a sub-two-second time-to-interaction with the first action teaching the core loop — appears across many distinct advertisers and persists over time, it is more likely to be a deliberate, validated pattern than a fluke. Independent convergence is the closest thing to a public signal that a structure works. A single clever playable seen once tells you little; the same structure under eight advertisers, running for months, tells you a great deal.
A second signal is investment intensity. Because playables are expensive to build, an advertiser running many variants of a structure, or clearly iterating on it over time (the same core with refined difficulty curves or CTA timing), is signaling that the structure is worth their production budget. Iteration is a tell: nobody pays to refine a loser.
A third, softer signal is internal coherence. A playable whose structure tightly serves a clear job — fast interaction, core-loop-first, competence moment, well-timed CTA — is more likely to be a considered, performing asset than one whose beats fight each other. Coherence does not prove performance, but incoherence is a reason for doubt.
Be explicit about the limits. None of these signals tell you how well a playable performs, only that it is likely a considered, possibly-validated pattern. You cannot see the install rate, the retention, or the return on ad spend (ROAS) behind it. So treat your inferences as prioritized hypotheses — ranked by how many independent signals support them — not as conclusions. The discipline is to say "this structure is well-supported as a hypothesis worth testing," never "this structure works."
A useful way to keep inference honest is to attach a confidence tier to each hypothesis rather than a binary works/doesn't. A high-confidence hypothesis is one supported by all four signals — it recurs across many advertisers, persists over time, shows visible investment and iteration, and is internally coherent. A medium-confidence hypothesis has two or three signals. A low-confidence one rests on a single observation or one advertiser's behavior. This tiering does two things: it forces you to articulate why you believe a structure is worth testing, and it lets you allocate scarce playable production budget to the highest-confidence hypotheses first. Because playables are expensive, the difference between testing a high-confidence and a low-confidence hypothesis is real money — the confidence tier is not academic, it is how you decide what to build.
It is also worth distinguishing inference about structure from inference about outcome. You can infer with reasonable confidence that a structure is deliberate and validated by the advertiser — that is what recurrence and investment tell you. You cannot infer that it will be validated for your game, because your genre, audience, art, and real mechanic differ. So even a high-confidence structural hypothesis is only a hypothesis about what to test, never a prediction of your result. The advertiser's validation transfers as a prior; it does not transfer as an outcome. Keeping these two kinds of inference separate is the difference between a disciplined analyst and one who quietly assumes a competitor's success will be theirs.
The Mechanic-Match Question in Playables
Mechanic-match — whether the playable's demonstrated mechanic matches the real game — is a general issue in mobile-game creative, but it bites hardest in playables, and any serious playable ad analysis has to read it explicitly. The reason is participation: in a video, the user watches a mechanic; in a playable, the user performs it. A mismatch a viewer might shrug off becomes a betrayal a player feels physically — they did the thing, installed expecting it, and found a different game.
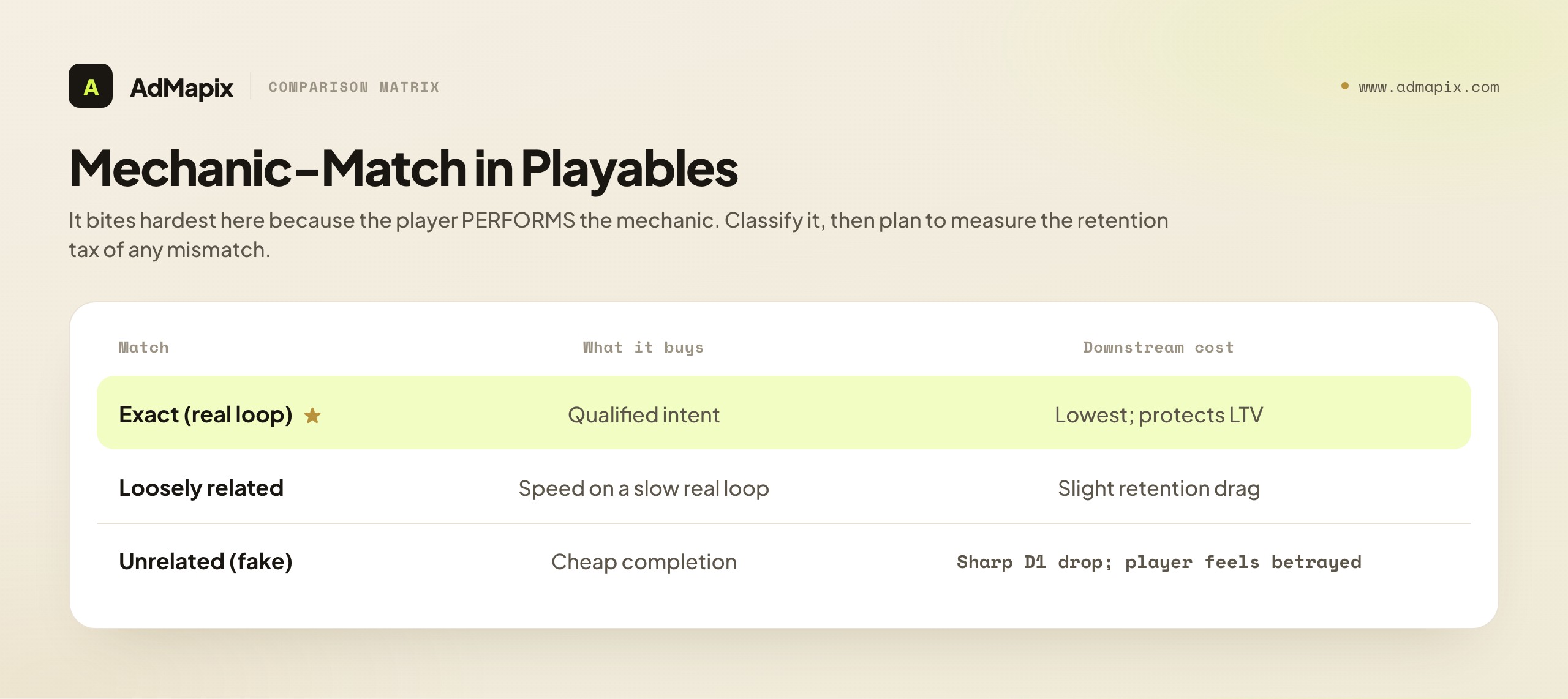
When you analyze a competitor playable, classify the mechanic-match on the same spectrum used across the genre: exact (the playable demonstrates the real core loop), loosely related (a stylized or idealized version of the real loop), or unrelated (a fake-but-adjacent loop — the famous pin-pull demo for a match-3 game). Each implies a different strategy and a different downstream cost. An exact-match playable is buying qualified intent; an unrelated playable is buying cheap completion at the expense of day-1 retention, because the players it converts arrive expecting something the game does not deliver.
The strategic read is not "fake playables are bad" but "what is the advertiser trading?" An unrelated playable may be a deliberate bet on cheap top-of-funnel volume, accepting a retention tax the advertiser has presumably measured. A loosely related one may be honestly speeding up a real-but-slow loop. An exact one is the sustainable default for protecting lifetime value. When you build your own brief from the analysis, the mechanic-match decision must be explicit and eyes-open — and you must plan to measure the retention tax of any mismatch against an exact-match control, because the CTR lift of a mismatch routinely hides a worse cost per retained player. For the broader dynamic, see fake mobile game ads; for hook-level examples, see puzzle game ad examples.
There is also a policy dimension to mechanic-match that belongs in any honest analysis. App stores have tightened their stance on creatives that misrepresent the product. Apple's App Store Review Guidelines and Google's Play developer policies both address misleading marketing, and a playable that lets a user perform a mechanic the game does not contain is a particularly clear case of misrepresentation. So when you read a competitor's unrelated-match playable, note that it is not only a retention bet but a policy exposure — and when you decide your own mechanic-match, the calculus includes brand and compliance risk, not just CTR and retention. The fact that a competitor runs a mismatched playable is not evidence it is safe; it may simply mean they have not been caught yet.
Step 4: Turn Analysis Into Testable Briefs
The whole point of playable ad analysis is to produce stronger hypotheses before you spend production budget. Here is the SOP for converting a folder of decoded competitor playables into a prioritized, testable brief queue.
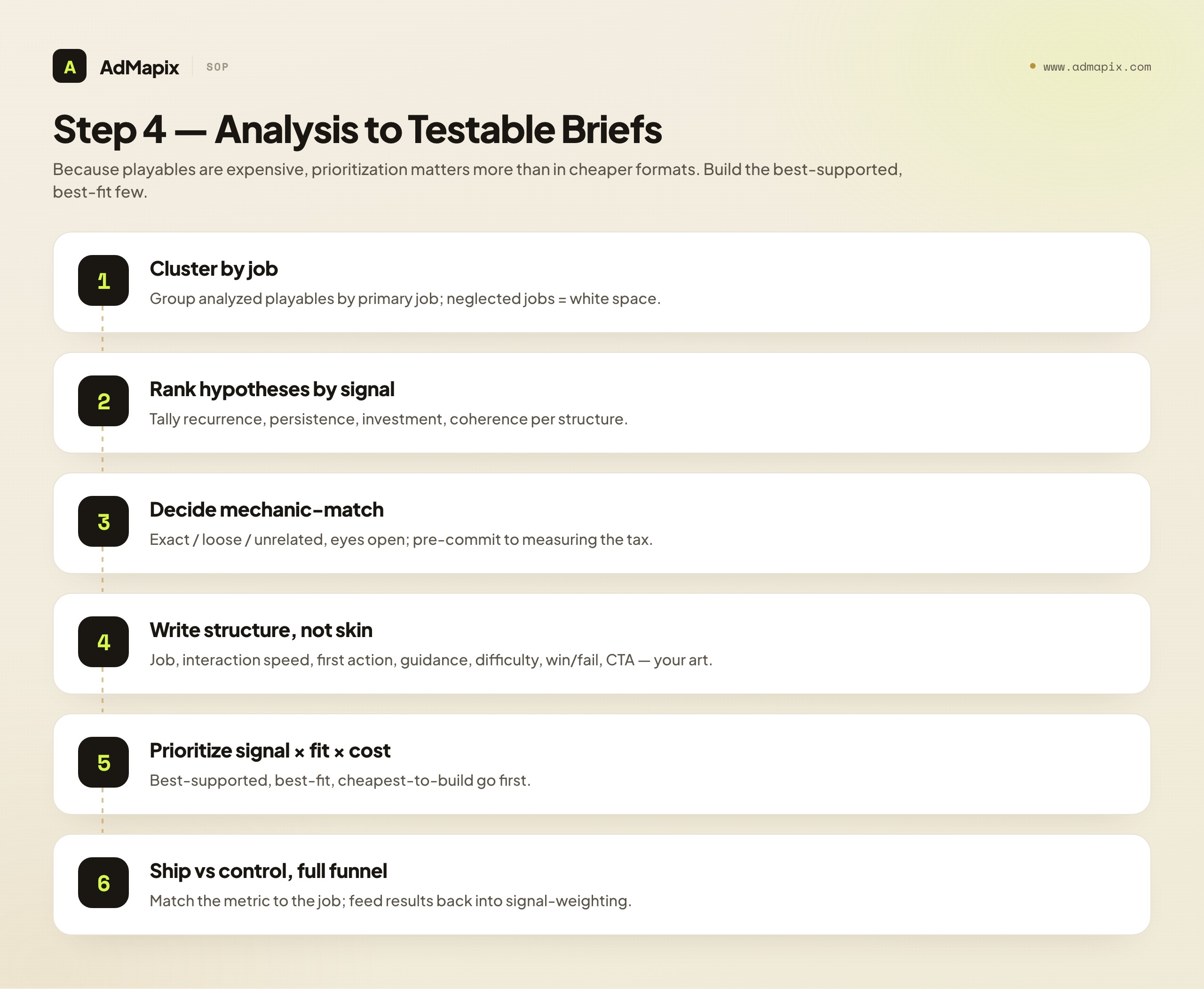
Step 1 — Cluster by job. Group your analyzed playables by their primary job (loop demo, qualification, competence, curiosity, fantasy). This shows you which jobs the category invests in and which it neglects — the neglected jobs are often white space for your game.
Step 2 — Rank structural hypotheses by signal. For each recurring structural choice (fast time-to-interaction, core-loop-first, post-competence CTA, etc.), tally the supporting signals — recurrence, persistence, investment, coherence. The best-supported hypotheses go to the front of the queue.
Step 3 — Decide mechanic-match explicitly. For each brief, make the exact/loose/unrelated decision deliberately, and pre-commit to measuring the retention tax of any mismatch against a control. Never let mechanic-match be an accident.
Step 4 — Write the brief as a structure, not a skin. Specify the job, the time-to-interaction target, what the first action teaches, the guidance level, the difficulty curve, the win/fail design, and the CTA placement — rebuilt for your game with your art. Do not pixel-copy a competitor; you would get a worse version of their playable and a possible legal headache.
Step 5 — Prioritize by signal × fit × cost. Rank briefs by how well-supported the hypothesis is, how well the structure fits your real game, and how expensive the playable is to build. Because playables are costly, the prioritization here matters more than in cheaper formats — you can only afford to build a few, so build the best-supported, best-fit ones first.
Step 6 — Ship against a control and measure the full funnel. Run each new playable against a stable control, and judge it on the metric that matches its job — completion and CTR for a completion-optimized playable, but D1/D7 retention and downstream events for a qualification playable. A playable that loses on completion but lifts retention may be the better asset. Feed every result back into your analysis so your signal-weighting improves over time. The mechanics of running these fights are in the creative testing framework.
A note on isolating variables, which is harder with playables than with videos. A playable has six structural beats, and changing several at once teaches you nothing about which change mattered. The disciplined approach is to hold a structural baseline and vary one beat at a time across tests — for example, run the same playable with an earlier CTA versus a later one, or with heavier versus lighter guidance, keeping everything else fixed. This is expensive because each variant is a real build, which is exactly why the upfront analysis and prioritization matter so much: you cannot afford to test every beat on every concept, so you test the beat your analysis flagged as the highest-leverage open question. The result is a slow but compounding body of knowledge about which structural choices move your funnel, which is the real asset the method produces.
It is also worth keeping a living "structure library" — your own accumulating record of which structural hypotheses you have tested, what won, and what lost, tagged by job and genre. Over time this library becomes more valuable than any competitor analysis, because it is grounded in your funnel rather than inferred from public signals. Competitor analysis seeds the library with hypotheses; your tests fill it with answers. A team a year into this discipline is no longer guessing from screenshots — it is building from a validated structural playbook that competitors cannot see and cannot copy.
What a Public Playable Proves — and What It Never Can
This is the honesty section, and it is essential in any analysis method, because the inferential nature of playable analysis makes overreach especially tempting. Be precise about the boundary.
What analyzing a public playable genuinely proves: the playable's structure (time-to-interaction, what the first action teaches, guidance level, difficulty curve, win/fail design, CTA placement), its apparent job, its mechanic-match to the real game, and — observed over time across an ad library — rough longevity and recurrence across advertisers. Counting recurrence and noting iteration adds soft signals of what the category believes works and what an advertiser has invested in.
What analyzing a public playable never proves: how much the advertiser spent behind it, its completion rate, its install rate, the retention or lifetime value of the users it brought in, its ROAS, or its targeting and bids. None of that is visible from outside, for anyone, using any tool. A playable that runs for months might be a quiet winner — or a sunk-cost asset nobody bothered to retire. Your inferences are probabilistic hypotheses, never measurements.
This is exactly where a creative-evidence layer like AdMapix fits, described honestly. AdMapix is searchable, cross-network ad-creative evidence — saved examples, video breakdowns, and recurring reports — so you can find and study competitor playables across networks without opening multiple ad libraries by hand. It is fast for discovery and for packaging examples into a shareable report. It cannot show you competitor spend, completion or install rates, retention, ROAS, or targeting, because that data is not public — and any tool that claims a precise performance figure for a competitor's playable is selling a model dressed as a fact. Use the structural evidence to form strong, prioritized hypotheses; use your own analytics to decide which one wins for your game. For the wider toolkit and where each tool's data ends, see the advertising intelligence guide, the ad creative database, and the mobile game ad spy tool overview.

Placement Context Changes the Read
A playable does not exist in a vacuum — it runs in a placement, and the placement changes what the structure means. Reading a playable without its context is like judging a line of dialogue without the scene. The two contexts that matter most are rewarded in-app placements (AppLovin, Unity, and the broader in-app ecosystem) and social/discovery placements.
In a rewarded in-app placement, the user is mid-session in another game, has agreed to watch for a reward, and is impatient to return to their play. This context explains a lot of structure: the relentless minimization of time-to-interaction, the front-loaded competence moment, and the early CTA are all responses to short, borrowed patience. So when you analyze a rewarded-placement playable, read its compression as appropriate to the context, not as a universal rule — the same structure on a different surface might be too rushed. The in-app context also means the audience is already gamers, which raises the stakes of mechanic-match (they will notice a mismatch immediately) and explains why exact-match qualification playables are so common here.
In a social or discovery placement, the playable competes with organic content and a colder, less primed audience. Here the playable may carry more of a hook burden — it has to win attention before it can convert it — so you might see a stronger opening tension or a more video-like lead-in before the interaction. Reading the placement tells you whether the advertiser is converting primed attention (in-app) or winning attention first (social), which changes how you weigh the opening beats.
The practical implication for your analysis is to always log the placement alongside the structure, and to compare like with like — rewarded playables against rewarded playables, social against social. A structural choice that looks aggressive in one context is standard in another, and conflating them muddies your inferences. When you later build briefs, match the structure to the placement you will run it in, not to a generic ideal.
This also means a single competitor's playable strategy is best read as a set keyed to placements, not a single artifact. A sophisticated advertiser may run a compressed, exact-match playable in rewarded in-app slots to qualify gamers, and a more hook-forward variant in social to win colder attention — the same game, two structures, two placements, two jobs. Spotting that an advertiser tailors structure to placement is itself a strategic read: it tells you they understand the format deeply and are unlikely to be making naive choices, which raises your confidence that their recurring structures are deliberate. Conversely, an advertiser running one identical playable everywhere may simply not have invested in placement-specific optimization, which lowers the weight you give their choices. Reading the spread of an advertiser's playables across placements is a layer of analysis above reading any one of them, and it is one of the clearest tells of a competitor who treats the playable as a serious, optimized format rather than a checkbox.
Where and How to Find Competitor Playables
A method is only useful if you can feed it inputs, and finding competitor playables is harder than finding videos or statics, because playables are interactive assets that live inside placements rather than in a tidy gallery. There are a few honest ways to source them.
The most direct is to encounter them in the wild — play games in your genre that show rewarded ads, and you will be served competitor playables in their native context. This has the advantage of showing the playable in its placement, which (per the section above) is part of the read; the disadvantage is that it is unsystematic and slow, and you cannot control which playables you see. The official ad-transparency libraries — Meta's Ad Library, the Google Ads Transparency Center, and TikTok's Commercial Content Library — surface many creatives, though interactive playables are not always fully reproducible there, and you must open each library separately with no shared search.
This sourcing friction is exactly the gap a cross-network creative-evidence layer addresses: instead of playing dozens of games hoping to be served a rival's playable, or opening several ad libraries one at a time, you can search across networks for the creatives a competitor is running and study saved examples and video breakdowns in one place. That collapses the slow, scattered sourcing step into a search, so your team's time goes to decoding and inference — the high-value parts of the method — rather than to hunting. What no sourcing method changes is the honesty boundary that runs through this whole guide: you can find and study the playable's structure, but you cannot see how it performed. Sourcing makes the inputs cheap; it does not turn inference into measurement.
A Worked Playable Teardown
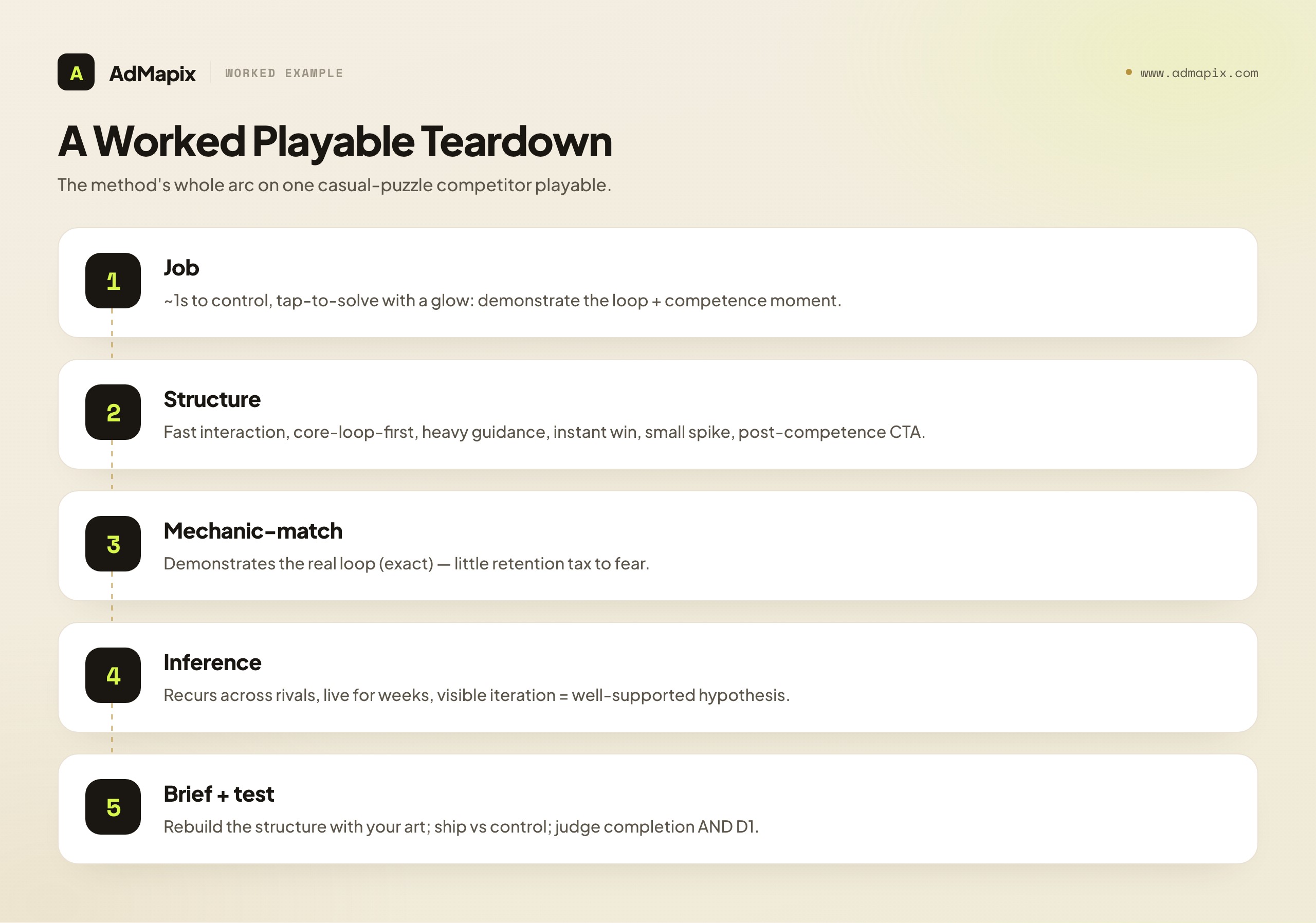
To make the method concrete, here is how a single competitor playable might read end to end. Suppose you are analyzing a casual puzzle competitor's playable pulled from a rewarded-video placement.
Job. Within two seconds the playable hands you control and pushes a single tap-to-solve action with a glowing target. The job is clearly demonstrate the core loop quickly with a strong competence moment — it wants you to feel "I solved that" almost immediately.
Structure. Time-to-interaction is roughly one second (excellent). The first action teaches the actual core mechanic (a match/clear), not navigation (excellent). Guidance is heavy — a finger hint and a glow point to the right move — which signals optimization for completion. The difficulty curve gives an instant easy win, then a slightly harder second solve that creates a small "try again" pull. The win moment fires with a satisfying clear and a reward animation. The CTA appears immediately after the second solve — right at the peak of the competence feeling, reading as "keep solving."
Mechanic-match. The demonstrated mechanic appears to be the real game's loop (exact match), so there is little retention tax to fear — the players it converts arrive expecting what the game delivers.
Inference. This structure — sub-two-second interaction, core-loop-first, heavy guidance, instant competence, post-competence CTA, exact match — recurs across several casual competitors and has been live for weeks, with visible iteration on the difficulty of the second solve. That cluster of signals makes it a well-supported hypothesis: a structure worth testing for your own casual title.
Brief. Rebuild the structure for your game with your art: sub-two-second interaction, first action = your real core mechanic, heavy guidance, instant easy win, one small spike, exact mechanic-match, CTA immediately after the competence moment. Ship against your best current playable control and judge on completion and D1 retention. Note what you cannot know — the competitor's actual completion rate, retention, or ROAS — and let your own funnel render the verdict.
This teardown shows the method's whole arc: job first, structure decoded in order, mechanic-match classified, inference weighted by signals, and a brief that rebuilds the structure rather than copying the skin — ending, as all honest analysis must, in a test rather than a conclusion.
Notice what the teardown deliberately does not claim. It never asserts the competitor's playable "works" or quotes a completion or install rate, because those numbers are not visible and inventing them would corrupt the whole exercise. It says the structure is a well-supported hypothesis and stops there. That restraint is not timidity — it is the discipline that keeps the method useful. An analyst who fills the unknowns with confident-sounding guesses produces a deck that feels authoritative and leads the team astray; an analyst who marks the boundary clearly produces a hypothesis the team can test and trust. The teardown is a model of saying exactly as much as the evidence supports, and no more — which, in a field full of tools that over-claim, is itself a competitive advantage.
Common Mistakes in Playable Ad Analysis
A handful of errors recur, almost all rooted in treating analysis as description rather than weighted inference.

Copying the skin, not the structure. Cloning theme, art, and reward screens while ignoring time-to-interaction, what the first action teaches, and CTA placement reproduces the look without the performance driver.
Skipping the job. Judging a playable's details without first naming its job leads you to overvalue polish and undervalue a rough-but-effective qualifier.
Treating inference as fact. "This structure works" overreaches; "this structure is a well-supported hypothesis" is honest. Recurrence is a prior, not proof.
Ignoring mechanic-match. Failing to classify the match — and to plan for the retention tax of a mismatch — is how a high-completion playable becomes a low-retention disaster.
Building before prioritizing. Because playables are expensive, building random variants without ranking hypotheses by signal × fit × cost wastes production budget. Prioritize, then build.
Judging every playable on completion. A qualification playable that loses on completion may win on retention. Match the metric to the playable's job.
Mistaking longevity for success. A long-running playable might be unmanaged. Independent recurrence is a stronger (still soft) signal than one advertiser's persistence.
How AdMapix Fits a Playable Analysis Workflow
To be concrete about the role of a creative-evidence layer: AdMapix helps with the discovery and packaging half of the analysis loop, not the measurement half. You can search cross-network for competitor playables, study saved examples and video breakdowns without juggling separate ad libraries, and assemble the strongest examples into a shareable report that justifies a playable roadmap to a producer or client. That collapses the most tedious part of the method — finding competitor playables across networks by hand — into a search, so your team spends its time on decoding and inference rather than on hunting.
What it does not do, and what no external tool can, is tell you how a competitor's playable actually performed or which structure will win for you. The job classification, the structural decode, the signal-weighted inference, the mechanic-match decision, and the final pick all still depend on your own analysis and your own funnel. The honest mental model is: AdMapix (and tools like it) make playable discovery fast and cross-network; your team owns the decoding, the inference, and the briefs; your test program and funnel own the verdict. Keep that division clear and you get the speed of a creative-intelligence layer without mistaking its evidence for outcomes. The natural next reads are the ad creative intelligence workflow for mobile UA teams and the in-game advertising overview.
The reporting value is worth one more line, because it is often where the analysis pays for itself in a studio. Decoding a competitor playable into job, structure, mechanic-match, and a signal-weighted hypothesis produces a document a producer or stakeholder can actually act on — far more than "here are some screenshots of competitor ads." When you have to argue for the production budget to build a playable, a packaged analysis that says "this structure recurs across these advertisers, has these signals, fits our game this way, and is the hypothesis we want to test" is a fundamentally stronger case than an assertion. A creative-evidence layer helps assemble that package quickly by putting the examples and breakdowns in one place; your analysis turns the package into a decision. The combination — fast evidence plus disciplined decoding — is what lets a team move from admiring competitor playables to systematically out-testing them, which is the entire point of doing playable ad analysis at all.
FAQ
What is playable ad analysis?
Playable ad analysis is the practice of systematically reverse-engineering competitor playable ads to form strong hypotheses before you build your own. Instead of collecting screenshots, you identify the job each playable is built to do, decode its structure beat by beat (time-to-interaction, what the first action teaches, guidance, difficulty, win/fail, CTA placement), infer which concepts are likely working from recurrence and investment signals, and turn the best-supported hypotheses into testable briefs. It is the cheapest way to earn good playable hypotheses without paying to rediscover them.
Why can't I just copy a competitor's playable?
Two reasons. First, surface copying reproduces the skin (theme, art, reward screen) but misses the real performance driver, which lives in the structure — how fast the user interacts, what the first action teaches, and when the CTA lands. Second, playables are expensive to build, so cloning a competitor wastes production budget on a worse version of their asset and risks a legal and brand problem. The method instead extracts the structural hypothesis and rebuilds it for your game.
How do I tell what job a playable is doing?
Ask what action the playable pushes you toward in the first few seconds, whether it shows the real loop or a fake-adjacent one, and whether it seems built for completion (heavy guidance, guaranteed success) or qualification (lighter guidance, real difficulty). Most playables primarily do one of five jobs: demonstrate the core loop quickly, qualify users, create a competence moment, open a curiosity gap, or sell a fantasy. Naming the job first frames every later observation.
What structural beats matter most in a playable?
Six: time to interaction (minimize it), what the first action teaches (it should teach the core loop), guidance level (heavy = completion-optimized, light = qualification-optimized), the difficulty curve (early easy win, then a small spike), the win/fail moment (most strong playables guarantee a win), and CTA placement (just after the competence moment converts best). Decode these in order for every competitor playable and you have a comparable, inference-ready record.
How does mechanic-match apply to playables?
More sharply than to any other format, because the player actually performs the demonstrated mechanic. Classify each playable as exact (real loop), loosely related (idealized loop), or unrelated (fake-adjacent loop). A mismatch can lift completion and click-through while sharply dragging day-1 retention, because the converted players arrive expecting a game they will not find. If you copy a mismatched structure, pre-commit to measuring the retention tax against an exact-match control.
Can I tell how well a competitor's playable performs?
No. Completion rate, install rate, retention, lifetime value, ROAS, and targeting are not public for any advertiser, and no external tool can show them. What analysis genuinely yields is structure, apparent job, mechanic-match, and — over time — recurrence and investment signals. Those let you form prioritized hypotheses about what is likely working, not conclusions about what does. Treat every inference as a hypothesis to test, never as a measured fact.
How do I turn analysis into something I can build?
Cluster your analyzed playables by job, rank structural hypotheses by their supporting signals (recurrence, persistence, investment, coherence), decide mechanic-match explicitly, write each brief as a structure (job, time-to-interaction, first action, guidance, difficulty, win/fail, CTA) rebuilt for your game, prioritize by signal × fit × cost, and ship against a control measuring the full funnel. Because playables are expensive, the prioritization step matters more here than in cheaper formats.
What metric should I judge my own playables on?
Match the metric to the playable's job. A completion-optimized playable is fairly judged on completion and click-through; a qualification playable must be judged further down the funnel on day-1 and day-7 retention and downstream events. Judging every playable on completion alone systematically undervalues qualifiers — a playable that converts fewer but stickier users can be the better asset even though its completion looks worse.
How is analyzing a playable different from analyzing a video?
A video is a message you read; a playable is an experience you perform, so its performance depends on the interaction itself, not just the hook and edit. Analysis therefore shifts from "is the hook clear?" to "how fast can the user act, what does the first action teach, and when does the CTA land relative to competence?" The structural, interaction-centric read is what makes playable analysis distinct — and why video-style surface copying fails on playables.
Where does AdMapix fit in playable analysis?
AdMapix is a cross-network creative-evidence layer: it makes the discovery-and-packaging half of the method fast — finding competitor playables across networks, studying saved examples and video breakdowns, and packaging them into a shareable report — without opening multiple ad libraries by hand. It does not (and cannot) show competitor spend, completion or install rates, retention, or ROAS. Use it to find playables and form hypotheses; use your own funnel to decide which structure wins. See the ad creative database for more.
Related reading: Pair this with the playable ads guide and playable ad examples, the puzzle game ad examples library, the creative testing framework, the honest take in fake mobile game ads, the best mobile game ad formats playbook, and the broader advertising intelligence guide, ad creative database, and mobile game ad spy tool overviews.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Best Mobile Game Ad Formats Across Platforms: A 2026 UA Playbook
A platform-by-platform guide to the best mobile game ad formats in 2026: which formats do the heavy lifting on Meta, Google, TikTok, AppLovin, and Unity; why the right format depends on platform, genre, and funnel stage; a format-selection framework; a creative-testing cadence; and the honest limits of what competitor ads can and cannot tell you about which format wins.

Meta Ads Library vs Ad Intelligence Tools for Game UA (2026): Which to Use, When, and Why
A definitive 2026 comparison of the Meta Ads Library vs dedicated ad intelligence tools for mobile game user acquisition — where the free transparency library genuinely helps, the structural limits that create blind spots for game UA creative research, a side-by-side capability matrix, the exact decision criteria for when to add a paid intelligence layer, and an honest account of what neither can show.
Ad Creative Intelligence Workflow for Mobile UA Teams in 2026: Find, Analyze, Brief & Build
A complete 2026 ad creative intelligence workflow for mobile UA teams — the four-stage loop to find winning competitor creatives, analyze why they work, brief production from them, and build a sustainable competitive-intelligence system, with the data inputs, a fixed taxonomy, tiered competitor monitoring, an observation-to-hypothesis method, a structured brief format, a weekly operating cadence, team-size tool choices, and the learning log that makes each cycle compound.