AI Creative Brief Template in 2026: Turn Competitor Evidence Into Testable Ads
A complete 2026 guide to the AI creative brief template — the nine fill-in fields that feed a model evidence instead of vibes, why the hook pattern is the highest-leverage input, how to gather example ads responsibly, the do-not-say list that keeps output honest, a prompt structure that uses the brief, how to rank output into a test backlog, a fully filled worked example, the limits of AI and public data, and where AdMapix fits.

AI Creative Brief Template in 2026: Turn Competitor Evidence Into Testable Ads
By the AdMapix Research Team — Updated June 21, 2026
An AI creative brief template works best when it feeds the model evidence and hard constraints instead of vague vibes: who the audience is, what the product does, the exact hook pattern you want it to borrow, the proof that backs the claim, the offer, the format, the landing path, two or three real example ads to learn from, and an explicit list of claims it must never make. The brief is the entire difference between an AI that invents generic "Unlock your potential" copy and one that writes a 9:16 script with a problem-first hook because you showed it three competitor ads that all opened that way. A model is only as good as the brief it is handed — and most "the AI writes bad ads" complaints are really "the brief was bad ads waiting to happen." This guide gives you a fill-in template, a prompt structure, a do-not-say discipline, and a way to rank the output into a test backlog you can actually ship.
This guide is for creative strategists, paid-social and growth marketers, founders, and agencies who use AI to draft ad creative and are tired of generic output. We will cover the nine fields a usable brief needs and why each removes ambiguity the model would otherwise guess at, why the hook pattern is the single highest-leverage input, how to gather example ads from public sources responsibly, the do-not-say list that keeps output honest and compliant, a prompt structure that actually uses the brief, how to turn the output into a ranked test backlog rather than one blind "final" ad, a fully filled worked example, and the honest limits of both AI and public data. The throughline, stated once and proven throughout: a great AI ad starts with a great brief, and a great brief is evidence plus constraints, never vibes.
TL;DR — The AI Creative Brief Template in One Screen
- Separate the hook, the proof, the offer, the format, and the landing path into distinct fields so the model can recombine them instead of copying one ad wholesale.
- The single highest-leverage input is 2-3 real example ads with their source URL and capture date attached, plus a short note on why each one works. This one input does the most to improve output.
- Describe the hook pattern to adapt, not the product to describe. "Open with a relatable failure state" beats "write an engaging intro" every time.
- Always include a do-not-say list: spend figures, ROAS, conversion rates, "#1" superlatives, and any health or earnings claim you cannot back from owned data. Repeat it at the end of the prompt.
- Public ad evidence proves an ad ran and what it said — never that it worked. Write performance in as a hypothesis to test, not a fact to replicate.
- Ask for ranked variants tied to measurable hypotheses, not one polished "final" ad. The AI is an ideation engine you rank, not a copywriter you trust blind.
- AdMapix fits the evidence-gathering step — searchable competitor creative across networks, saved with source context and broken down into the hook annotations the model learns from, to feed the brief when screenshots and bookmarks stop scaling.
What Goes in an AI Creative Brief Template
A usable brief has nine fields, and every field exists to remove ambiguity the model would otherwise fill with cliché. The fields are: objective, audience, product, hook pattern, proof, offer, format, landing path, and do-not-say claims. Skip any one of them and the model guesses — and a model's guess is always the most generic, training-data-average version of the answer.


| Field | What to write | Why the model needs it |
|---|---|---|
| Objective | The one decision this ad serves (cold prospecting, retargeting, app install) | Sets tone, length, and CTA aggressiveness |
| Audience | Specific segment, awareness stage, objection they hold | Stops generic "everyone" copy |
| Product | What it does in one sentence, the category | Anchors claims to reality |
| Hook pattern | The opening device to borrow (question, stat, pattern interrupt) | Hooks decide scroll-stop rate more than the body |
| Proof | The evidence behind the main claim (demo, before/after, third-party) | Prevents unsupported promises |
| Offer | Price, trial, guarantee, bonus | Drives the CTA |
| Format | 9:16 video, static, carousel, UGC | Shapes pacing and structure |
| Landing path | Where the click goes and what it must match | Keeps message-match intact |
| Do-not-say | Claims you cannot prove from owned data | Keeps the ad compliant and honest |
The non-obvious part is the hook pattern. Most weak briefs describe the product and let the AI write an opener; strong briefs describe the opening device and let the AI adapt it to the product. "Open with a relatable failure state the buyer recognizes" produces dramatically better hooks than "write an engaging intro," because the first instruction gives the model a structural device to execute while the second leaves it to invent — and invention defaults to cliché. The next section is entirely about why this field carries so much weight.
A note on field discipline that mirrors good database design: keep hook, proof, and offer in separate fields, never merged into one "make it compelling" instruction. The whole value of a structured brief is that the model can recombine the elements — take your hook pattern, your proof, and your offer and assemble fresh variants. If they are tangled into one blob, the model can only copy the blob; if they are separate, it can mix and match. Separation is what turns the AI from a copier into a combinatorial ideation engine, which is the entire point of briefing it well.
It is worth understanding why models reward structure so strongly, because it changes how you write every field. A language model generates by predicting what comes next from the context it has been given, and a vague context ("write a great ad") gives it nothing to anchor on but the statistical average of all ads it has seen — which is, definitionally, cliché. A specific, structured context ("here is the exact opening device, here is the proof, here are three ads that did this") narrows the model's prediction space to the small region you actually want, so its output is drawn from a far better neighborhood of possibilities. Every field you fill in is a constraint that prunes the cliché branches and keeps the good ones, which is why a fully-specified brief produces output that feels custom while an underspecified one produces output that feels generated. The model is not "more creative" with a good brief; it is more constrained toward your specifics, and in creative work, the right constraints are what produce the right output. Treat each field as a constraint you are deliberately imposing to keep the model out of the average, and the whole template makes more sense — it is not a form to fill, it is a set of guardrails that steer the model away from the generic.
A practical field-completeness rule: a half-filled brief is often worse than no brief, because the model confidently fills the blanks you left with its average guess and then writes the whole ad around those guesses. If you leave the audience vague, every other field gets written for "everyone." If you leave the proof blank, the model invents a plausible-sounding but unsubstantiated claim. So treat the nine fields as a checklist to complete, not a menu to sample — the fields are interdependent, and a gap in one propagates cliché through all the others. The five minutes it takes to fill every field honestly is the cheapest quality lever in the entire workflow.
Why the Hook Pattern Is the Highest-Leverage Field
The hook pattern deserves its own section because it is the field that most determines output quality, and the one most teams get wrong. The hook — the first one to three seconds of a video, or the headline of a static — decides whether anyone consumes the rest of the ad at all. A brilliant body under a weak hook is never seen; a strong hook buys attention for an average body. So the brief's instruction about the hook is, disproportionately, the brief's instruction about whether the ad works.

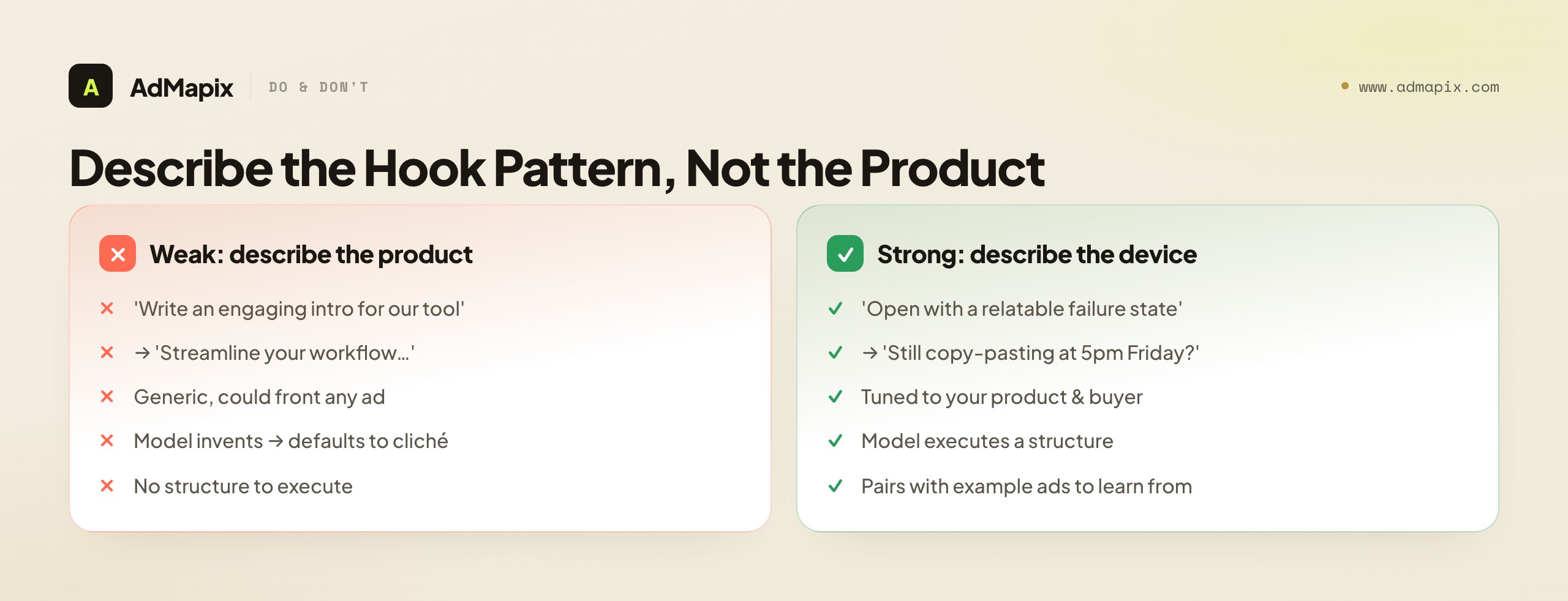
The mistake is to describe the product and hope the model produces a good hook. "Write an ad for our project-management tool" yields "Streamline your workflow with the all-in-one solution" — a hook so generic it could front any SaaS ad ever made. The fix is to describe the opening device, the structural pattern you want the hook to follow, and let the model adapt it to your product:
- Problem-callout: "Open by naming the specific frustration the buyer feels at 5pm on a Friday." → "Still copy-pasting tasks between four tools at end of day?"
- Pattern interrupt: "Open with a counter-intuitive claim that contradicts category common sense." → "Your project tool is why your team misses deadlines."
- Stat/shock: "Open with a specific, surprising number." → "Teams waste 9 hours a week just updating status."
- Curiosity gap: "Open with a question whose answer requires watching." → "There's one setting that doubled our team's on-time rate."
Each of these is a device the model can execute well, because it is a structure rather than a vibe — a recipe the model can cook, rather than a flavor it has to imagine. And this is exactly where your example ads earn their keep: if you show the model three competitor ads that all opened with a problem-callout, and tell it "borrow this opening device," it will produce problem-callout hooks tuned to your product rather than generic SaaS-speak. The hook pattern field plus the example ads together are roughly 70% of what separates a usable AI ad from a throwaway one — so spend most of your briefing effort there, and treat the other fields as refinements on an ad people are already, thanks to the hook, watching.
There is a deeper reason to specify the device rather than let the model choose: the device encodes a strategy, and strategy is the thing you actually want to control. A problem-callout hook implies a strategy of meeting a problem-aware buyer at their pain; a curiosity-gap hook implies a strategy of pulling a less-aware buyer into the ad; a stat-shock hook implies a strategy of establishing authority fast. When you let the model pick the opening device, you are letting it pick your strategy — and it will pick the blandest, most-averaged one, because that is what its training data rewards. When you specify the device, you are making the strategic decision yourself and using the model only to execute it, which is the correct division of labor: humans decide strategy, models execute tactics at scale. This is also why the hook pattern should flow from your audience field — a problem-aware buyer wants a problem-callout, an unaware buyer needs curiosity, a skeptical buyer needs proof up front. Choose the device that matches your audience's awareness stage, and the hook is already strategically right before the model writes a word; let the model choose, and you have outsourced your most important creative decision to a statistical average.
How to Gather the Example Ads the Brief Depends On
The brief is only as good as the example ads you feed it, so collect them from public, transparent sources and tag what each one is doing. Pull from platform ad libraries and creative-intelligence search rather than your memory of "ads I liked" — memory is biased toward the clever and forgets the effective. For each example, save the source URL, the capture date, the format, and a one-line note separating its hook from its offer.


The fields you can responsibly capture from a public ad are the creative asset, the hook, the offer text, the visible CTA, the format, and the landing path. The fields you cannot capture are spend, audience targeting, ROAS, GMV, or conversion rate — those live in the advertiser's private account, where no public tool can reach them. Treat any "this ad is crushing it" claim with suspicion unless it comes from your own data, because a confident performance claim feeding the brief is a confident error feeding the model.
How to choose which examples to feed the brief matters as much as gathering them:
- Pick examples that share the structure you want but differ in surface detail. Three ads that all open with a problem-callout but for different products teach the pattern; three near-identical ads teach the model to copy one specific ad, which is exactly what you do not want.
- Annotate each one with what it is doing, separating hook from offer from proof. "Hook: problem-callout about wasted time. Offer: free trial. Proof: customer count." The annotation is what the model learns from — a raw screenshot teaches it far less than a screenshot plus your read of why it works.
- Keep two to three, not ten. One example overfits and the model copies it; more than four and the signal blurs into an average. Two or three sharp, annotated examples is the sweet spot.
The provenance discipline matters here too: a source URL and capture date make the example re-verifiable and keep any later brief or report defensible. An ad with no source is an opinion; an ad with a resolving URL is evidence — and you want your brief built on evidence, because the model will faithfully amplify whatever you feed it, sound or unsound.
The annotation is genuinely the load-bearing part, and it is worth being specific about how to write one well, because most people annotate too little. A weak annotation says "good hook." A strong annotation decomposes the ad the way the brief decomposes your own: "Hook: problem-callout naming the exact moment of pain (a breach notification email). Proof: a compliance badge shown in the first three seconds. Offer: free trial, stated at the end. Format: 9:16, fast cuts, captions. Why it works: it leads with the buyer's fear before pitching, and proves trustworthiness visually before asking for anything." That annotation teaches the model the structure and the reasoning, not just the surface — and a model that learns the reasoning can adapt the pattern to your product, while a model handed a bare screenshot can only mimic the pixels. The effort you put into annotating the three examples is repaid directly in output quality, because the annotation is the part of the example the model actually reasons from. Think of each example as a tiny case study you are writing for the model, not a clip you are pasting; the case study teaches, the clip merely shows.
Public Data: What It Can and Cannot Prove
This sub-point matters because briefs built on assumed performance produce confident, wrong instructions — and a confidently wrong brief produces a confidently wrong ad. Public creative evidence proves that an ad ran and what it said; it does not prove that the ad worked.


Use longevity — an ad that has been live for months across many variants — as a soft signal that the advertiser is investing in it, because advertisers rarely keep funding losers. But write that into the brief as a hypothesis to test, not a fact to replicate. The instruction to the model should be "generate variants on this pattern that we will measure," never "replicate this proven winner," because you do not know it is a winner — you know it ran. The distinction sounds pedantic until you have shipped a "proven" competitor angle that flopped because it was never actually proven, only persistent. Bake the humility into the brief: examples are evidence of what was tried, the model's job is to generate testable variants, and your own measurement is the only thing that decides what worked. A brief that respects this line produces a test backlog; one that ignores it produces a confident bet on a guess.
There is a second reason a competitor's "winner" may not transfer even if it genuinely worked for them: it worked for their product, audience, offer, and funnel, none of which are identical to yours. A hook that converts for an enterprise security tool aimed at CISOs may flop for an SMB tool aimed at office managers, even though both are "security ads," because the buyer, the fear, and the proof that lands are different. So even a truly proven competitor angle is, for you, still a hypothesis — it proves the pattern can work somewhere, not that it works for you. This is why the brief frames every example as a pattern to test rather than a result to copy: the transferability of an angle across products is itself an open question your test answers. Write the examples into the brief as "here is a pattern worth trying for our buyer," and you stay honest about the one thing public ads can never tell you — whether what worked for them will work for you. Only your test, on your audience, with your offer, settles that.
A Prompt Structure That Uses the Brief
A great brief feeds a great prompt, and prompt structure matters as much as content — models follow a labeled, ordered structure far better than they follow prose. Feed the model the brief as labeled sections, then end with the task and the constraints.


A reliable shape, in order:
- Role and objective first. "You are a direct-response creative strategist. Your job is to generate testable ad hooks for [product] aimed at [audience]." Setting the role and the job up front orients everything that follows.
- The nine brief fields as a labeled block. Each field on its own line, labeled, so the model can reference them precisely. Structure beats paragraphs here.
- The two or three example ads as quoted text with your notes. Quote the actual ad copy, then your one-line annotation of its hook/offer/proof. This is where the model learns your specific style.
- The explicit output format. "Return five hook variants, each with the proof it leans on and one measurable hypothesis." Telling the model the exact shape of the output is what turns rambling prose into a usable, rankable list.
- The do-not-say list, repeated at the end. Models weight recent context heavily, so repeating the constraints last keeps them salient through generation. The list at the top is easily forgotten by the time the model writes the fifth variant; the list at the bottom is not.
The single most common fix that improves output: ask for variants tied to hypotheses instead of one polished ad. "Give me five hooks, each testing a different angle (fear of loss, social proof, speed, price, status), and state what each one assumes about the buyer" turns the AI into an ideation engine you can rank, rather than a copywriter you have to trust. Five testable hypotheses are worth far more than one confident "final" ad, because the five become a test backlog and the one becomes a blind bet. The prompt structure exists to make the AI hand you the backlog.
Two refinements make the prompt structure noticeably more reliable. First, ask the model to state its reasoning per variant, not just the variant. "For each hook, state the buyer assumption it tests and why it might fail" forces the model to surface the logic, which both improves the hooks (a model that has to justify a hook writes a better one) and gives you the rationale you need to rank them. A hook with its assumption attached is a testable hypothesis; a hook alone is just copy. Second, constrain the format tightly and the creativity loosely. Tell the model exactly what shape the output must take (five variants, each with these three labeled parts) but leave the angles open within that shape. Over-constraining the angles ("write five fear-based hooks") narrows the exploration you wanted from the AI in the first place; under-constraining the format ("give me some ideas") produces an unrankable wall of prose. The sweet spot is a rigid output container holding loose creative content — structure where you need to compare, freedom where you need to explore. Get that balance right and the model returns a clean, rankable backlog of genuinely varied hypotheses rather than either a formless ramble or five rephrasings of the same idea.
Turn the Output Into a Ranked Test Backlog
The output of a well-briefed AI session should not be an ad you ship — it should be a ranked test backlog you ship from. This reframing is what separates teams who use AI to ideate well from teams who use it to generate plausible-looking copy they then trust too much — and the trust gap is exactly where money gets wasted on unvalidated "final" ads.

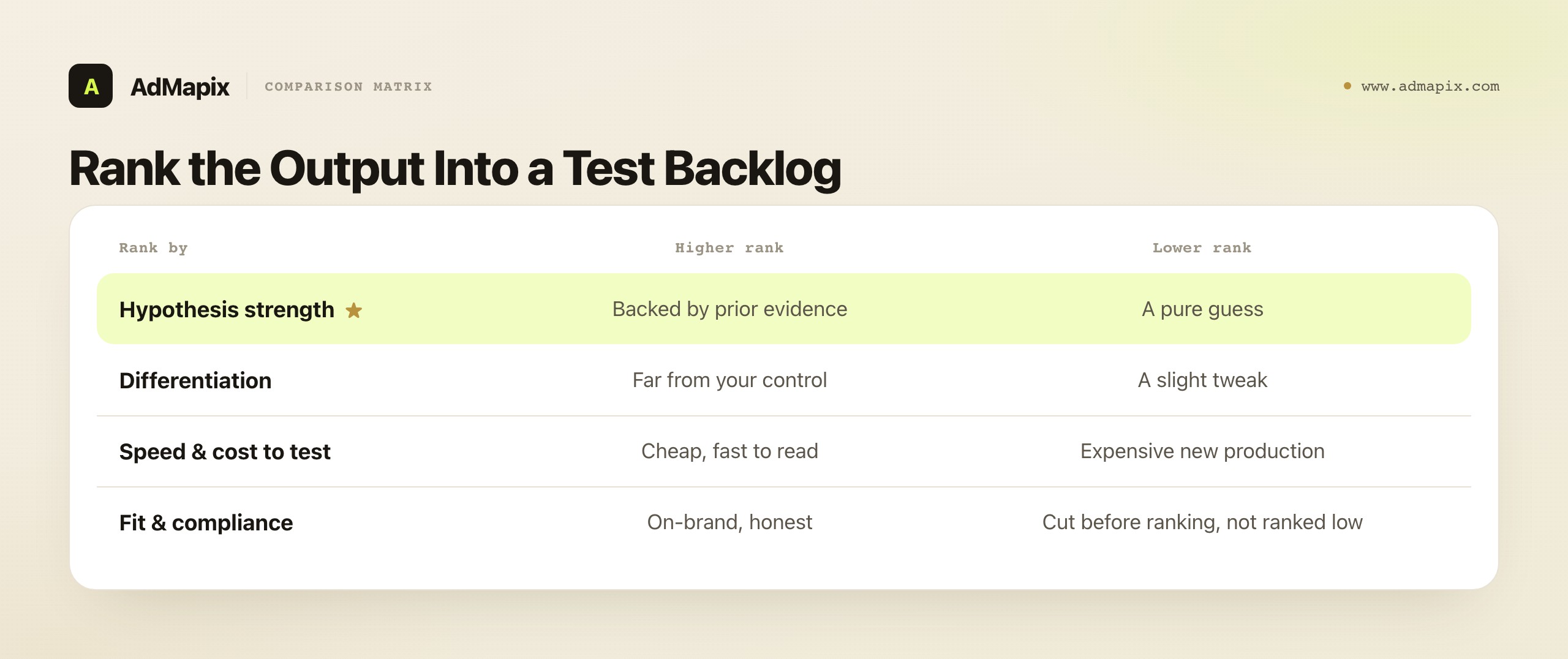
Once the model returns five hook variants, each tied to a hypothesis, you rank them — not by which sounds best, but by a deliberate logic:
- Strength of the underlying hypothesis. A variant testing an angle you have prior evidence for (your example ads, your own past tests) ranks above one testing a pure guess. The hook is a vehicle for the hypothesis; rank the hypothesis.
- Differentiation from your current control. A variant that is meaningfully different from what you already run teaches you more than one that is a slight tweak. Tests should explore, not nudge.
- Cost and speed to test. A hook you can test cheaply and read quickly ranks above one requiring expensive new production, all else equal — you want fast learning loops.
- Fit and compliance. Any variant that strays into a do-not-say claim or off-brand territory is cut before ranking, not ranked low. Honesty and brand fit are gates, not factors.
The ranked backlog then feeds your normal testing process: take the top one or two hooks, produce them, run them against your current control, and measure on the metric that matters to your account (cost per acquisition, hook-rate, whatever your objective defined). The winner becomes evidence that sharpens the next brief — a problem-callout hook that beat control is a stronger example to feed the AI next month than any competitor ad, because you have your own data behind it. That loop — brief, generate, rank, test, measure, feed the winner back — is what turns AI creative from a novelty into a compounding system. The AI never decides what works; your test data does. The AI's job is to generate enough good, differentiated, testable hypotheses that your testing has something worth measuring.
A word on why ranking by what sounds best is the trap to avoid. The most polished-sounding variant the AI produces is often the most generic, because fluency and originality are different things — a model can write a buttery-smooth hook that is also a cliché. If you rank by which copy reads nicest, you systematically select for the safe, average variant and discard the differentiated, riskier ones that would actually teach you something. The differentiated variant is the valuable one precisely because you do not already know whether it works; the smooth-but-familiar one tells you little even if it wins, because it confirms what everyone already does. So rank by hypothesis strength and differentiation, deliberately over-weighting the variants that test a genuinely new angle, and resist the pull toward the one that simply reads best. Your testing exists to learn, and you learn most from the variants that surprise you — which are rarely the smoothest ones. A good ranking session feels slightly uncomfortable, because it pushes the differentiated bets up and the safe-sounding copy down, against the instinct to pick the pretty one.
Common Mistakes With AI Creative Briefs
The failure modes are predictable, and nearly all of them come from treating the AI as a copywriter to trust rather than an ideation engine to direct.


- Describing the product instead of the hook pattern. The AI writes a brochure, not an ad. Tell it the opening device to adapt, not just what the product does.
- Feeding zero example ads. Without examples the model defaults to training-data cliché. Two or three good, annotated ones change everything.
- Letting performance claims leak into the brief. "Copy this winning ad" assumes private data you do not have. Frame examples as hypotheses, never as proven winners.
- Merging hook, offer, and proof into one blob. When they are tangled, the AI cannot recombine them; keep them as separate fields so the model can mix and match.
- Skipping the landing path. A great ad that mismatches the landing page wastes the click. Tell the model where the traffic goes and what the message must match.
- Skipping or front-loading-only the do-not-say list. Put it in, and repeat it at the end of the prompt where the model weights it most heavily.
- Accepting one "final" ad. Ask for ranked variants with hypotheses so you ship a test, not a guess — and let your own data, not the AI's confidence, decide the winner.
- Ranking by what sounds best. The smoothest variant is often the most generic; deliberately over-weight the differentiated bets that will actually teach you something.
- Never feeding winners back. A tested winner is your strongest possible example; skip the feed-back step and the brief loop stops compounding into a learning system.
A Worked Example: A Fully Filled Brief
Principles land harder filled in, so here is a complete brief for a composite product — a team password manager called "VaultFlow" — ready to drop into a prompt, with every field populated the way the sections above prescribe.


- Objective: Cold prospecting on Meta, 9:16 video, optimizing for trial starts.
- Audience: IT leads at 50-500-person companies, problem-aware (they know password sprawl is a risk) but not solution-aware about VaultFlow. Objection: "we already use a free browser password manager."
- Product: VaultFlow is a team password manager with shared vaults, audit logs, and SSO; category is security/IT tooling.
- Hook pattern: Open with a relatable failure state the IT lead recognizes — the moment a departing employee still has access to shared logins. Borrow the problem-callout device from the three example ads below.
- Proof: SOC 2 compliance, audit-log demo, and a "used by 4,000+ teams" count. Lead with the audit-log demo as visual proof.
- Offer: 14-day free trial, no card required.
- Format: 9:16 vertical video, sound-on, 15-20 seconds, fast cuts, on-screen captions.
- Landing path: /trial page that opens with the same departing-employee failure state, so message-match holds.
- Example ads (2-3): [three real competitor security-tool ads, each with source URL, capture date, and a one-line note: "Hook: problem-callout about a breach scenario. Offer: free trial. Proof: compliance badge." — annotated so the model learns the pattern, not the wording.]
- Do-not-say: No "100% unhackable," no specific breach-cost statistics we cannot cite, no "#1 password manager," no spend or customer-count claims beyond the verified 4,000+ figure.
The prompt that wraps it: role first ("You are a direct-response creative strategist for security tooling"), then the nine fields as a labeled block, then the three annotated example ads, then "Return five hook variants, each opening with a different failure-state angle, each stating the proof it leans on and one measurable hypothesis about the IT-lead buyer," then the do-not-say list repeated.
The output you want: five distinct problem-callout hooks — the departing-employee scenario, the shared-login-in-Slack scenario, the ex-contractor-still-has-access scenario, and so on — each tied to a hypothesis ("IT leads fear the departing-employee gap most, so it will out-hook the generic 'secure your team' angle"). You rank those five by hypothesis strength and differentiation, produce the top one or two, test against your current control, and measure trial-start cost in your own account. That is the whole system: evidence in, ranked testable hypotheses out, your data decides. Nothing in the brief claimed a competitor ad was "proven" — it claimed three ads tried a pattern, and asked the model to generate testable variants on it.
Notice how much of the brief's quality came from a few fields working together. The audience field (problem-aware IT leads who already use a free manager) determined that a problem-callout hook was the right device — a problem-aware buyer responds to having their problem named, not to a curiosity gap. The objection in the audience field ("we already use a free browser manager") told the model what the hook must implicitly overcome, which is why the failure-state scenarios all highlight gaps a free browser manager cannot close. The proof field (audit-log demo) gave the model something concrete to show rather than claim. And the do-not-say field kept the security claims honest, which matters doubly in a regulated-adjacent category where an overclaim is a real risk. No single field carried the brief; the fields interlocked, each one constraining the others toward a coherent, specific ad. That interlock is exactly why a half-filled brief fails — pull out the audience objection and the hooks lose their target; pull out the proof and the model invents one. A good brief is a system of mutually-reinforcing constraints, and the worked example shows the system clicking together: audience drives hook, hook drives examples, proof grounds the claim, do-not-say keeps it honest, and the output is a ranked test backlog rather than a single guess.
The Compounding Brief Loop
The reason to invest in a disciplined brief is not a single good ad — it is a loop that gets better every cycle. A one-off AI brief produces one batch of variants; a brief system produces a compounding asset, because each test feeds the next brief with evidence you own rather than evidence you borrowed.


The loop has five steps, and the magic is in the last one. You brief (nine fields, hook pattern, annotated examples, do-not-say). You generate five testable variants. You rank them by hypothesis strength. You test the top one or two against your control and measure in your own account. And then — the step most teams skip — you feed the winner back into the next brief as an example ad. A hook that beat your control is the single strongest example you can hand the AI, because unlike a competitor ad it comes with your own proof: you know it worked, for your buyer, on your metric. No borrowed competitor pattern can match that.
Watch what this does over time. In month one, your example ads are all borrowed competitor creative — useful hypotheses, but unproven for your product. By month three, your best examples are your own tested winners, and the AI's output is tuned to angles you have measured rather than angles you have guessed. By month six, you have a private library of proven hooks that no competitor can see and no public tool can replicate, because it is built from your account's results. The brief loop has quietly turned the AI from a generic copy generator into a bespoke ideation engine trained on your own winning patterns. That is the real return on brief discipline: not one good ad, but a system that compounds your creative learning into an asset that gets more valuable and more proprietary with every test cycle.
The discipline that powers the compounding is the same one that runs through the whole guide: never let the AI decide what works, and always feed the loop with what your data proved. The AI generates; your tests judge; the winners teach the next generation. Skip the "feed the winner back" step and the loop stops compounding — you get a competent generator that never learns your specifics. Run it religiously, and the brief becomes the on-ramp to a creative learning system that outpaces any team still treating each AI session as a fresh, evidence-free start.
When to Use AdMapix
Use AdMapix when the example-gathering step in this workflow has outgrown screenshots and bookmarks. The brief depends on two to three sharp, annotated, sourced example ads, and finding those reliably — across networks, with provenance, week after week — is exactly where a searchable creative library beats memory and a chaotic bookmarks folder. AdMapix is built for marketers and agencies who write briefs regularly and need that library to feed them.


Start with Search AdMapix to find ads across networks by keyword or competitor — the example-sourcing a brief depends on. Use Media to save the assets and source context behind each brief, Video Analysis to break a video ad into its hook, pacing, and structure (which is exactly the annotation the model learns from), and Reports to package a set of examples into something a client or team can review. Pricing covers solo, team, and agency tiers, and you can Login to start saving evidence into a workspace.
It is not the right tool if you only run one or two campaigns a year, if you need verified spend or ROAS numbers (no public tool can prove those, and AdMapix does not claim to), or if you just want a one-off AI rewrite of existing copy. The honest framing: AdMapix helps you collect and organize the evidence a brief needs and break down the video ads that teach the model best; it does not write the brief, run the AI, or decide which patterns transfer to your product. The judgment — which examples to feed, which hypotheses to rank, what your own data says worked — stays with you. AdMapix removes the friction in the evidence step so the rest of the loop runs on better inputs.
Putting It Together: Evidence In, Testable Ads Out
The whole method reduces to one principle: an AI creative brief is evidence plus constraints, never vibes. The model will faithfully amplify whatever you hand it — feed it a vague "make a great ad" and it returns great-sounding cliché; feed it nine structured fields, a sharp hook pattern, three annotated example ads, and a do-not-say list, and it returns testable variants tuned to your product and your buyer. The brief is the lever, and the highest-leverage part of the lever is the hook pattern plus the examples.
Build the brief around the nine fields, keep hook, proof, and offer separate so the model can recombine them, describe the opening device rather than the product, gather two to three annotated example ads with provenance, frame their performance as hypothesis rather than fact, structure the prompt so the constraints land last, and ask for ranked variants tied to measurable hypotheses. Then rank, test, measure in your own account, and feed the winner back into the next brief. Do that, and AI creative stops being a generator of plausible copy you over-trust and becomes a compounding ideation engine you direct — one that hands you a test backlog every session, gets sharper as your own winners accumulate, and never once asks you to ship a guess. Evidence in, testable ads out, your data decides: that is the entire discipline, and the brief is where it starts.
The deeper shift this represents is in how you relate to the AI at all. The teams that get the least from AI creative treat it as a writer to delegate to — hand it a vague ask, accept what comes back, hope it is good. The teams that get the most treat it as an executor to direct — make the strategic decisions yourself (the device, the audience, the proof, the constraints), use the model only to generate at scale within those decisions, and let your own data judge the results. The brief is the instrument of that second relationship: it is how you encode your strategic decisions into something the model can execute, and how you keep the judgment where it belongs — with you and your test data, never with the model's confidence. Master the brief and you do not just get better ads; you get a durable way of working with AI that scales your creative thinking instead of replacing it, which is the only version of AI creative worth building a process around.
FAQ
What is the most important field in an AI creative brief?
The hook pattern, paired with two or three real example ads. The hook decides whether anyone watches past the first second, and the examples teach the model your specific style instead of letting it guess. Everything else — offer, proof, format — refines an ad people are already, because of the hook, watching. If you only get two fields right, make them the hook pattern and the examples.
How many example ads should I include in the brief?
Two to three is the practical range. One example overfits and the model copies it wholesale; more than four and the signal blurs into an average. Pick examples that share the structure you want but differ in surface details, so the model learns the pattern rather than the wording, and annotate each with its hook, offer, and proof so the model learns from your read, not just the raw asset.
Can AI write a finished ad I can ship without review?
No. Treat AI output as ranked ideation, not final creative. The brief should ask for variants with hypotheses, then a human checks each for brand fit, factual accuracy, and compliance before it runs. The do-not-say list reduces risk but does not remove the review step — and your own test data, not the AI's confidence, decides which variant actually works.
How do I describe a hook pattern instead of just the product?
Describe the opening device — the structural move the hook should make — not the product's features. "Open with a relatable failure state the buyer recognizes" or "open with a counter-intuitive claim that contradicts category common sense" gives the model a device to execute, while "write an engaging intro for our tool" leaves it to invent, and invention defaults to cliché. Pair the device with example ads that use it, and the model adapts the pattern to your product.
How do I stop the AI from making claims I cannot prove?
Put a do-not-say list in the brief and repeat it at the end of the prompt, where the model weights recent context most. List the specific claims to avoid: spend figures, ROAS, conversion rates, "#1" superlatives, and any health or earnings promise you cannot substantiate. Then review the output against owned data, not against competitor ads — a competitor's claim is not your evidence.
Where do competitor example ads come from?
From public, transparent sources: platform ad libraries and creative-search tools. Save the source URL and capture date with each one so it is re-verifiable. Remember that a public ad proves what was said and that it ran, not that it performed — so write any performance read into the brief as a hypothesis to test, never as a proven winner to replicate.
Why should the output be a test backlog instead of one ad?
Because one "final" ad is a blind bet, while five ranked variants tied to hypotheses are a test backlog you can ship from and learn from. The AI cannot know which angle works for your buyer — only your test data can — so the right output is enough good, differentiated, testable hypotheses that your testing has something worth measuring. Rank them by hypothesis strength and differentiation, test the top one or two, and let your account's metrics decide.
How does this brief loop get better over time?
Each test produces a winner backed by your own data, and that winner becomes the strongest possible example to feed the next brief — better than any competitor ad, because you have measured it. So the loop compounds: brief, generate, rank, test, measure, feed the winner back. Over months, your example set shifts from borrowed competitor patterns to your own proven angles, and the AI's output gets sharper because its inputs are evidence you own rather than hypotheses you borrowed.
Do I need a tool to gather the example ads?
Not at first — a spreadsheet of sourced, annotated ads works to start, and it teaches the discipline. You outgrow it when you write briefs regularly and gathering fresh, sourced, cross-network examples each time becomes the bottleneck. At that point a searchable creative library like AdMapix removes the friction in the evidence step, with video breakdowns that produce exactly the hook annotations the model learns from.
Where does AdMapix fit in this workflow?
AdMapix fits the evidence-gathering step the brief depends on: searching competitor creative across networks, saving it with source context, and breaking down video ads into the hook-and-structure annotations the model learns best from. It does not write the brief, run the AI, or decide which patterns transfer to your product — the judgment stays with you. It removes the friction in sourcing so the rest of the loop runs on better, more reliable inputs.
Key Takeaways
- Build the brief around nine fields and keep hook, proof, and offer separate so the model can recombine them into fresh variants.
- Feed two or three real example ads with source URLs, capture dates, and annotations; this single input does the most to improve output quality.
- Describe the hook pattern — the opening device — to adapt, not just the product to describe; it is the highest-leverage field.
- Add a do-not-say list and repeat it at the end of the prompt, and frame example-ad performance as a hypothesis to test, never a proven fact.
- Ask for ranked variants tied to measurable hypotheses, test the top ones in your own account, and feed each winner back into the next brief so the loop compounds.
Related Reading
- Ad Creative Database in 2026: How to Build a Searchable Library for Hooks, Offers, and Proof — the library that stores and sources the example ads this brief depends on.
- Competitor Ad Analysis in 2026: The 5-Dimension Framework, Templates & SOP — the analysis that surfaces the patterns worth briefing.
- Ad Creative AI — the broader picture of AI in creative production.
- Ad Spy Tools by Channel: Meta, TikTok, Google, YouTube, Native — where the example ads come from across networks.
- How to Spy on Competitors' Ads in 2026 (30-Min/Week Workflow) — the research loop that keeps the brief's evidence fresh.
Sources
Sources verified as of June 21, 2026. Platform docs, ad formats, and APIs change, so confirm each URL before building an automated workflow or client report.
- Google Ads ad variations — Google documents how ad variations let you test and iterate creative messages, including headline and call-to-action changes, across campaigns.
- TikTok creative best practices — TikTok recommends TikTok-first creative: vertical 9:16 assets, sound on, safe-zone-aware content, and featuring creators, employees, or customers.
- LinkedIn Ads Guide — LinkedIn's Ads Guide lists supported formats including Single Image, Video, Carousel, Document Ads, Lead Gen Forms, Sponsored Messaging, Text, and Dynamic Ads.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles
Ad Creative Intelligence Workflow for Mobile UA Teams in 2026: Find, Analyze, Brief & Build
A complete 2026 ad creative intelligence workflow for mobile UA teams — the four-stage loop to find winning competitor creatives, analyze why they work, brief production from them, and build a sustainable competitive-intelligence system, with the data inputs, a fixed taxonomy, tiered competitor monitoring, an observation-to-hypothesis method, a structured brief format, a weekly operating cadence, team-size tool choices, and the learning log that makes each cycle compound.

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.

Ad Intelligence API: What Developers Need Beyond a Raw Ads-Library Endpoint in 2026
A developer-focused guide to ad intelligence APIs: what fields make a creative record queryable, why official ads-library endpoints stop short, the buy-vs-build tradeoff for a cross-network layer, and how to design a pipeline that survives schema and rate-limit changes.