Revcontent Ad Spy Tool in 2026: Native Ad Research Without Overclaiming the Data
How to research Revcontent native ads from public evidence in 2026 — what a Revcontent ad spy tool can and cannot prove, why content-arbitrage margins make honesty essential, how to attribute platform rules versus advertiser choices, capture creative and landing-path evidence, read compliance risk in native funnels, separate observed facts from spend guesswork, and turn repeating patterns into a tagged test backlog instead of a screenshot folder.
By the AdMapix Research Team — Updated June 21, 2026
Revcontent Ad Spy Tool in 2026: Native Ad Research Without Overclaiming the Data
A Revcontent ad spy tool is most useful for studying visible native creative: the headlines, thumbnails, content angles, and landing paths that run across publisher sites. It cannot reveal a competitor's private spend, targeting, or ROAS, because Revcontent does not publish a competitor library — and the single most valuable habit in this kind of research is refusing to overclaim what the data can prove. This 2026 guide is for native advertisers, affiliate and content-arbitrage buyers, media buyers, and agencies who want a repeatable way to collect that evidence, separate fact from guess, and turn examples into creative tests. By the end you will know exactly what public Revcontent evidence can prove, why content-arbitrage economics make the honesty discipline non-negotiable, how to attribute what you see to the platform versus the advertiser, how to capture creative and landing-path evidence that stays reusable, how to read compliance risk in native funnels, and how to build a research habit that compounds rather than a folder of screenshots nobody reopens.

TL;DR — Researching Revcontent Native Ads
- A Revcontent ad spy tool helps you study visible native ads — headline, thumbnail, content angle, and landing path — not hidden spend or targeting. That observable surface is genuinely useful.
- There is no public Revcontent competitor ad library, so any claim about exact spend, CPM, CTR, or ROAS is a guess, not evidence. Treat every private-metric figure as a modeled estimate at best.
- Content-arbitrage margins are thin, which makes the temptation to treat "visible everywhere" as "profitable" especially dangerous. Frequency is a hint, never a verdict.
- Attribute what you see to the right layer. Placement style, disclosure labels, and widget behavior are platform-defined; the headline, thumbnail, angle, offer, and landing page are the advertiser's choices.
- The reliable output is a tagged set of saved creatives plus a test backlog, not a screenshot folder. Capture creative, context, landing path, and your reason for saving.
- A creative-intelligence layer such as AdMapix fits teams that want native examples turned into searchable media, pattern tags, and recurring reports — across networks, not Revcontent alone.
What a Revcontent Ad Spy Tool Can Actually Tell You
Native ad research tells you what creative is being shown, not how well it performs — and on Revcontent specifically, where so much of the inventory is content-recommendation arbitrage, keeping that distinction sharp is the difference between useful research and expensive self-deception.

On a content-recommendation network like Revcontent, the ad lives inside a publisher page as a sponsored recommendation widget: a thumbnail, a curiosity-driven headline, a small disclosure label, and a click that leads to an advertorial, a quiz, or an offer page. Everything in that chain is observable. You can see the thumbnail, read the headline, follow the click, and study the landing page. The money behind it — the spend, the bid, the CPM, the click-through rate, the conversion rate, the return on ad spend — is not observable, because Revcontent does not publish it and no public tool can infer it reliably.
That distinction matters more on Revcontent than on almost any other surface, because native arbitrage runs on tiny margins. A content-arbitrage operator might buy traffic on a native network and monetize it through display ads or affiliate offers, with the entire business living in the thin gap between traffic cost and monetization. In that world, a creative that is visible everywhere is tempting to assume is profitable — but the assumption is exactly backwards as often as it is right, because thin-margin arbitrage means a creative can be running at scale while barely breaking even or quietly losing money. Frequency is a hint about where to look, not a verdict on profitability. A long-running headline formula is worth testing; it is not proof that the advertiser is winning. The researchers who do well on Revcontent are the ones who hold this line hardest, precisely because the economics make over-claiming so seductive and so costly.
It is worth being concrete about why visible scale is such a weak signal on this kind of network, because the intuition that "surely if they're running it everywhere it must work" is so strong. Three things break that intuition on native arbitrage. First, the margin is invisible and tiny: two operators running the identical creative at the same apparent volume can have opposite outcomes because one has a slightly cheaper traffic source or a slightly better monetization, and neither difference is visible from outside. Second, operators tolerate losses longer than you would expect, because arbitrage is a game of finding a winning configuration through volume, and they will run a creative at a loss while they tune the surrounding economics, hoping to flip it profitable. Third, what you can observe is a snapshot, not a ledger — you see the creative is running today, not whether it ran profitably yesterday or will tomorrow. Put together, these mean visible scale is roughly as consistent with "losing money while testing" as with "scaling a winner," and you genuinely cannot tell which from the outside. That is not a reason to ignore the signal; it is a reason to read it as "worth investigating" rather than "proven," which is the entire discipline this guide is built around.
The flip side is also worth stating, because the honesty discipline cuts both ways: a quiet creative is not necessarily a loser. An operator running something at modest volume might be in early testing on a genuine winner, or deliberately keeping a profitable angle low-profile to avoid attracting copycats. So just as you should not read loud as profitable, you should not read quiet as failing. The only thing visible scale reliably tells you is what is visible — and the strongest inference you can responsibly draw is from a structure repeating across many independent advertisers, because that pattern is hard to explain except by the structure genuinely working often enough that multiple operators independently converged on it. Even then it is a hypothesis about your own economics. But cross-advertiser repetition is a meaningfully stronger signal than any single advertiser's volume, and learning to weight it accordingly is one of the most useful calibrations a Revcontent researcher can make.
Start With Official Platform Context
Before collecting examples, understand what the format allows, so you do not mistake a platform rule for a competitor's creative choice. This step is skipped by most researchers and it quietly corrupts their conclusions, because they attribute to a clever competitor what is actually just how the platform works.

Revcontent describes its advertiser side as a native ads platform that connects advertisers to audiences across publisher sites, with targeting and reporting tools available to the account owner only — not to competitors. Its native-advertising framing treats the format as paid sponsored content designed to blend with the surrounding page, delivered primarily through content-recommendation placements. The practical consequence for a researcher is a clean division of labor between what the platform decides and what the advertiser decides.
The platform-defined layer includes the placement style (how and where the recommendation widget appears on a publisher page), the disclosure labels (the "sponsored" or "recommended" framing required around native units), and the widget's general behavior. None of that is a competitor's creative decision — it is how Revcontent's format works, and attributing it to a competitor's genius (or incompetence) is a category error. The advertiser-defined layer is where the real research lives: the headline, the thumbnail, the content angle, the offer, and the landing page are all choices the advertiser made, and they are the testable variables you should be studying. When you research, attribute the right things to the right layer — credit the advertiser for their creative choices and the platform for its format rules — or you will draw lessons from things that were never a competitor's decision in the first place.
This attribution discipline sounds pedantic until you see how it goes wrong in practice. A researcher new to native might notice that a competitor's ads all carry a particular "Sponsored Content" framing and conclude the competitor has discovered some clever trust-building technique — when in fact that framing is simply the disclosure the platform requires, present on every advertiser's units. Or they might attribute the recommendation-widget's grid layout to a competitor's design choice, when it is the network's standard format. Each of these mis-attributions wastes research effort on something that was never a variable, and worse, it can lead you to "copy" a platform default as if it were a strategy, which teaches you nothing. The fix is a simple mental checklist applied to every element you study: did the advertiser choose this, or did the platform impose it? Only the advertiser's genuine choices belong in your headline bank and your test backlog. Getting the attribution right is unglamorous, but it is the foundation that keeps the rest of your research pointed at things you can actually act on.
Understanding the platform context also helps you read what is normal versus what is distinctive on the network. Once you know the standard widget behavior, disclosure conventions, and placement patterns, an advertiser who does something genuinely unusual within those constraints stands out — and that distinctiveness is often where the interesting creative thinking lives. You cannot spot the advertiser doing something clever within the format's rules unless you know the rules well enough to recognize the deviation. So spending an hour up front understanding Revcontent's format from its own advertiser-facing materials is not wasted time; it is what calibrates your eye to tell platform-default from advertiser-innovation for the rest of your research. The researcher who skips this step is reading the network without knowing its grammar, and will repeatedly mistake the ordinary for the remarkable and the remarkable for the ordinary.
What to Capture From Each Example
Capture the creative, the context around it, and your reason for saving it — a screenshot alone is not reusable. Using a consistent structure is what lets a teammate, or you in three weeks, actually act on an example rather than squint at an image with no memory of why it mattered.

| Research area | What to capture | Why it matters |
|---|---|---|
| Placement context | Publisher category, page type, disclosure label, device, region when visible | Tells you where the angle works, not just that it exists |
| Creative evidence | Headline, thumbnail, content angle, curiosity gap, product claim, CTA | The actual testable variables |
| Landing path | Advertorial, quiz, ecommerce page, lead form, app/store, compliance risk | Where the conversion logic and risk live |
| Advertiser signal | Brand or advertiser where disclosed, how often it recurs | Repeat advertisers signal angles that survive |
| Your reasoning | One line on why you saved it and what to test | Turns a screenshot into a brief |
The structure matters because native research without provenance decays into noise faster than almost any other kind. A Revcontent thumbnail with no note on its headline, landing path, publisher context, and your reason for saving is a picture you will not be able to use. The same thumbnail captured with its full context — "curiosity health headline, ran on general-news publisher, led to advertorial → quiz → supplement offer, compliance looked borderline, saved June, want to test the structure not the claim" — is a data point you can sort, compare, and turn into a brief. The five-row structure above is deliberately more than just "creative," because on native the context (where it ran) and the landing path (where it converts) and your reasoning (what to do about it) are as much the evidence as the ad itself. Capture all of it, every time, and your collection becomes a research asset rather than a graveyard of images.
Why the Honesty Discipline Matters Most on Revcontent
Every native network rewards honest research, but Revcontent rewards it most, because the content-arbitrage and affiliate-heavy nature of much of its inventory makes the gap between "looks like it's working" and "is actually profitable" both wider and more dangerous than elsewhere. This deserves its own section because it is the through-line of the whole guide.
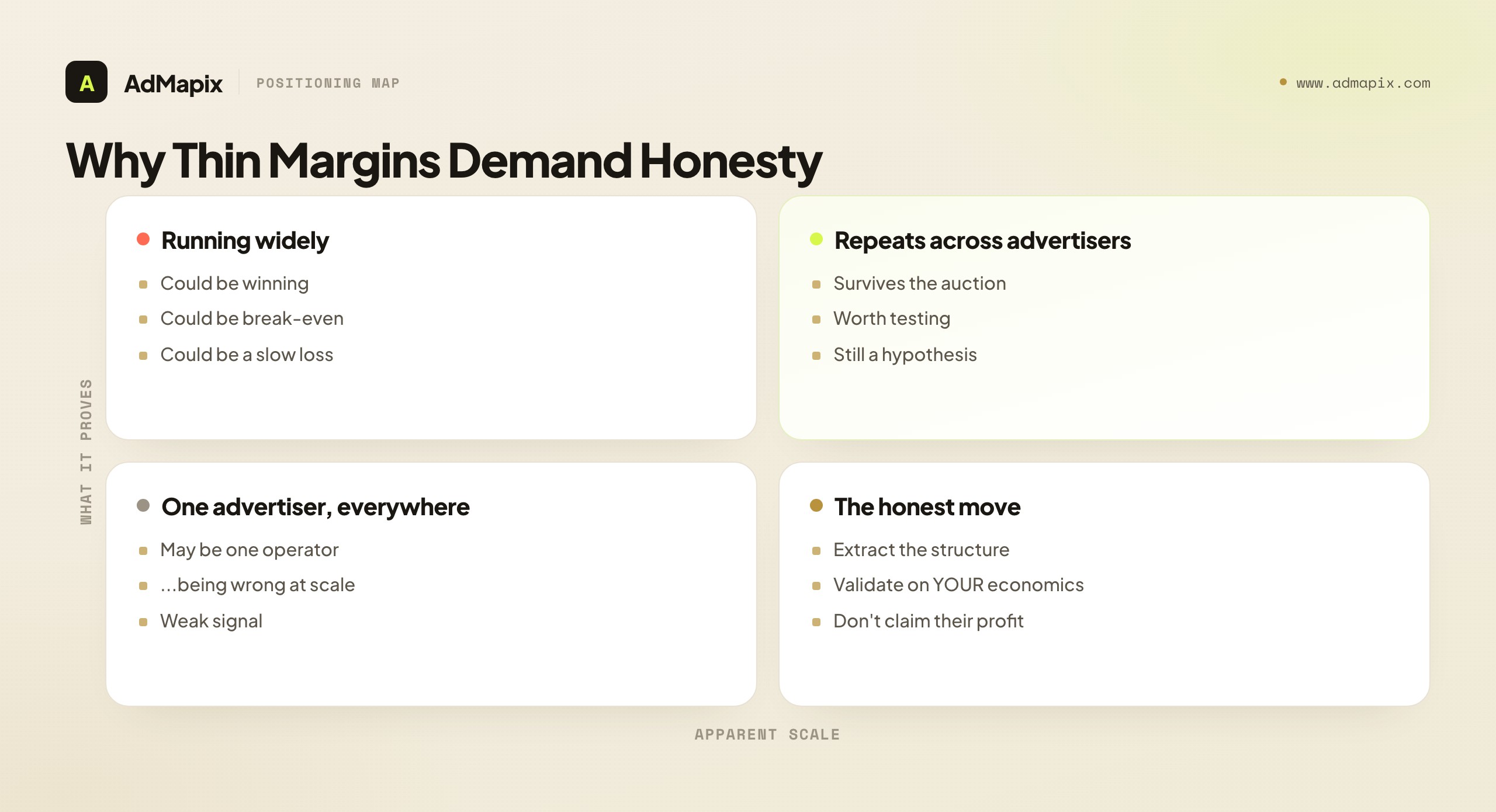
Consider the arbitrage operator's economics. They buy native traffic and monetize it, and their margin is the slim difference between the two. Because the margin is thin, the same creative can be profitable for one operator and a loss for another running it at the same apparent scale, depending entirely on differences in traffic cost, monetization efficiency, and offer economics that are completely invisible from the outside. So when you see a Revcontent creative running widely, you genuinely cannot tell whether you are looking at a winner, a break-even test, or a slow bleed — and the visible scale tells you almost nothing about which. On a high-margin brand-advertising surface, "running for a long time at scale" is at least weak evidence of success; on thin-margin native arbitrage, it is barely evidence at all, because operators will run things at a loss longer than you would expect while chasing a fix.
This is why the title of this guide is what it is. The most valuable thing a Revcontent researcher can do is not overclaim — to look at a widely-running creative and say "this structure appears to survive the auction, which is a signal worth testing" rather than "this is a proven winner I should copy." The first statement is true and useful; the second is a guess dressed as a fact, and on thin margins, copying a guessed winner is how you lose money fast. The discipline is to extract the testable hypothesis (the structure, the angle, the landing-path pattern) and validate it against your own economics, while explicitly refusing to claim knowledge of a competitor's profitability that the data cannot support. Researchers who internalize this outperform not because they see more, but because they fool themselves less — and on Revcontent, not fooling yourself is most of the edge.
The Landing Path and Compliance Risk Layer
The destination matters as much as the ad, and on Revcontent the landing path carries an extra dimension worth studying explicitly: compliance and content-quality risk. Following the click is not optional research — it is where the conversion logic and the risk both live.
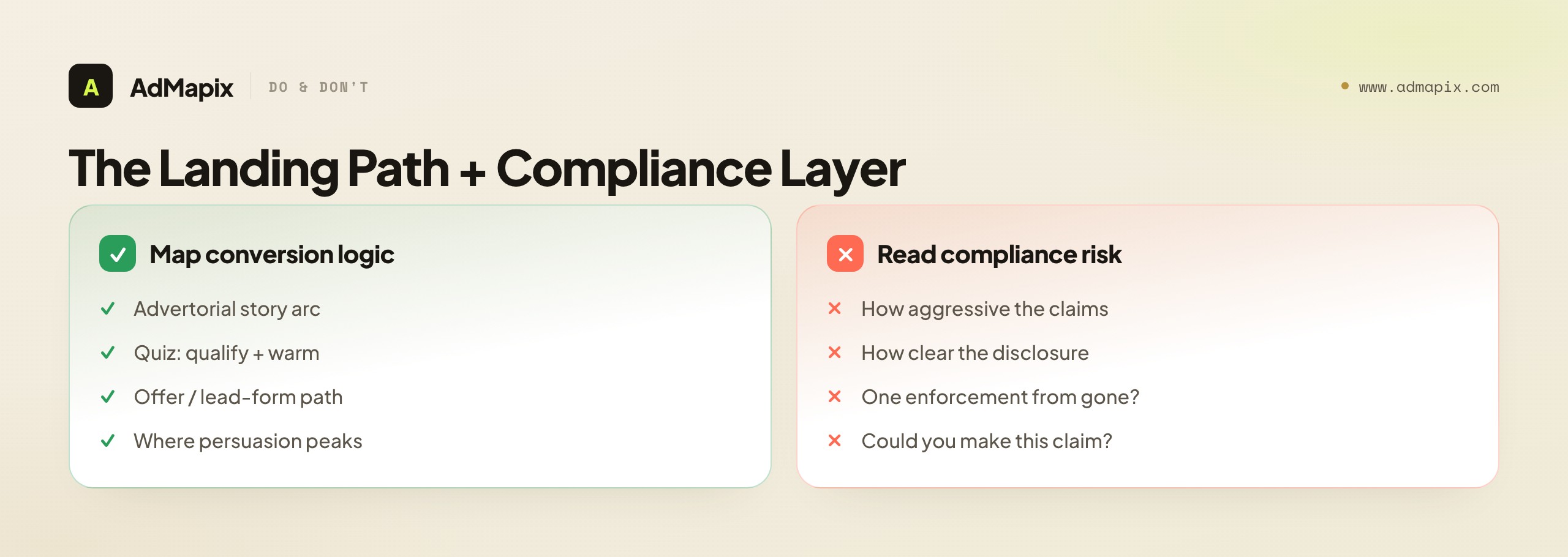
When you follow a Revcontent click, map where it lands and how it is built. An advertorial tells a long-form story from problem to solution before the offer; note its arc and where the persuasion peaks. A quiz funnel qualifies and warms the visitor before presenting an offer. An ecommerce or offer page is a more direct path to a purchase, and a lead form captures contact details for a slower sale. Each is a different conversion machine, and recognizing which one an advertiser uses tells you about their strategy. But on native arbitrage specifically, you should also read the compliance risk of the funnel: how aggressive are the claims, how clear is the disclosure, how close to the line of acceptable content does the advertorial run. This matters for two reasons. First, an aggressive-claims funnel that is winning today may be one policy enforcement away from being shut down, so copying it inherits its risk. Second, the compliance posture tells you something about the operator — a careful funnel with substantiated claims is a different competitor than one running borderline claims that may not survive scrutiny.
Reading compliance risk is a genuine research skill that pure social-ad spying rarely requires, and it is especially relevant on networks where content-arbitrage and health, finance, and supplement offers are common. The discipline is to note, for each funnel you study, where it sits on the risk spectrum — substantiated and clearly disclosed at one end, aggressive and borderline at the other — and to factor that into whether the pattern is one you would actually want to adopt. A structurally clever funnel built on claims you could not or would not make is a lesson in conversion architecture, not a template to copy. Studying the landing path for both its conversion logic and its risk posture is what separates research that informs sustainable campaigns from research that tempts you into copying something that will get you in trouble. The most useful patterns are the ones that are both effective and defensible, and you can only tell which those are by reading the full landing path with a compliance-aware eye.
A Repeatable Revcontent Research Workflow
The fastest path from a native ad to a decision is the same every time. Name the decision first, then collect evidence against it, then turn the evidence into a brief — never letting an observation become a claim it cannot support.

- Name the decision. Headline research, thumbnail research, offer teardown, landing-path mapping, compliance assessment, or a competitor monitor are different jobs. Write down which one you are doing before you start.
- Attribute to the right layer. As you collect, separate platform-defined elements (placement, disclosure, widget behavior) from advertiser choices (headline, thumbnail, angle, offer, landing page). Only the latter are testable variables.
- Capture the full context. For each example, record placement context, creative evidence, landing path (including compliance risk), advertiser signal, and your one-line reason for saving.
- Refuse to overclaim. Mark what is observed as fact and what is private — spend, CTR, ROAS, targeting — as not determinable. Never let "visible everywhere" become "proven winner" in your notes.
- Convert patterns to a brief, then validate. Turn repeating, defensible structures into a test backlog — and let your own traffic cost, conversion, and margin data, not the spy evidence, decide whether a pattern works for you.
The discipline is in steps 4 and 5, and they are the steps this whole guide is built around. Anyone can screenshot native ads; the operators who win on thin margins are the ones who refuse to overclaim, validate against their own economics, and only adopt patterns that are both effective and defensible. Do that and the research compounds into a real edge; skip it and you copy guessed winners into a loss.
Provenance and reasoning — captured in steps 3 and 4 — are what keep the research honest as it grows. A saved Revcontent creative with no note on its landing path, compliance posture, and your reason for saving is a picture; the same creative with its full context and an explicit "observed, not proven" tag is intelligence you can act on responsibly. And step 5 is the boundary that the thin margins make unforgiving: the evidence generates hypotheses, but only your own cost-and-conversion data confirms whether a pattern is profitable for you. On a high-margin channel you can afford to be a little loose; on native arbitrage, validating before you scale is the difference between a business and a slow leak.
What Public Data Can and Cannot Prove
This deserves its own section because over-claiming is the central failure mode of native research, and Revcontent's economics punish it hardest. Public Revcontent evidence proves what is running, not what is winning.

When you see a competitor's Revcontent ad, you are seeing that the creative exists and, sometimes, that it appears across multiple publisher contexts. You are not seeing the spend behind it, the bid, the CPM, the click-through rate, the conversion rate, the return on ad spend, or the targeting. None of that is published, and no public tool can infer it reliably — any figure you see for those is a modeled estimate (label it) or a guess (leave it out). The thin-margin caveat makes this sharper than on other channels: even "this has been running a long time at scale" is weak evidence on native arbitrage, because operators run things at a loss longer than intuition suggests, chasing a profitable configuration. Apparent longevity and frequency are faint hints about where to look, never proof of profit.
So treat every pattern as a hypothesis, and be especially disciplined about the strength of the signal. "This curiosity-driven content angle repeats across several independent advertisers in my vertical" is a genuinely useful signal — the repetition across independent operators suggests the structure survives the auction, which is more than any single ad tells you. But it is still a hypothesis about your own economics, not a guarantee. "This one advertiser runs this everywhere" is even weaker, because a single advertiser running something widely could simply be a single advertiser being wrong at scale. Weight cross-advertiser repetition over single-advertiser frequency, weight earlier and quieter signals over saturated ones, and validate everything against your own numbers before you scale. The native arbitrage graveyard is full of operators who copied a "proven winner" that was never proven — only visible — and discovered the margin had already been captured by the early movers they were imitating.
There is a constructive way to hold all of this, so the honesty discipline does not curdle into paralysis. The point is not that public Revcontent evidence is useless — it is genuinely valuable — but that its value lies in a specific place: generating well-grounded hypotheses about creative structure, not conclusions about competitor profitability. A researcher who internalizes this stops asking the question the data cannot answer ("is this competitor making money?") and starts asking the questions it can ("what structures recur across independent advertisers? what landing-path patterns keep appearing? what angles seem to survive in my vertical?"). Those questions have observable, defensible answers, and the answers feed directly into a test backlog you validate on your own economics. The honesty discipline, properly understood, is not a list of things you cannot know — it is a redirection toward the things you genuinely can, and those things are exactly what you need to build better creative. Frame your research around the answerable questions, hold the unanswerable ones as explicitly unknown, and you get all the value the network's public evidence actually offers while sidestepping the expensive mistakes that come from pretending it offers more.
Finally, a note on how to present this research to others, because the honesty discipline is most tested when you have to brief a client or a boss who wants certainty. The temptation in a presentation is to round "this structure appears across several advertisers and is worth testing" up to "competitors are winning with this," because the second sounds more decisive and authoritative. Resist it. A brief that says "here is a structure we observed recurring across independent advertisers, which is a strong signal worth testing — and here is what we deliberately cannot claim about its profitability" is more credible to a sophisticated audience, not less, because it demonstrates you understand the limits of the evidence. The people who get caught out are the ones who presented competitor spend or success as fact and then could not defend the number when challenged. Build the can't-prove boundary into how you communicate the research, not just how you conduct it, and your work earns the kind of trust that overclaimed research never can.
Common Mistakes in Revcontent Research
Most wasted effort in Revcontent research traces back to a few avoidable errors, and most of them are versions of over-claiming.
- Treating "visible everywhere" as "profitable." On thin-margin native arbitrage, visible scale is barely evidence of profit. Frequency is a hint; only your own economics prove a pattern works.
- Attributing platform rules to competitor genius. Placement, disclosure labels, and widget behavior are Revcontent's format, not an advertiser's clever choice. Credit the advertiser only for headline, thumbnail, angle, offer, and landing page.
- Skipping the landing path and its compliance risk. The advertorial or quiz does the real selling, and its compliance posture tells you whether a pattern is even safe to adopt. Researching the ad without the funnel misses both.
- Quoting spend, CPM, or ROAS from public data. None of those is public on Revcontent. Any such number is an estimate or a guess and must be labeled as one, never presented as fact.
- Copying one creative instead of learning the structure. The value is the repeating, defensible structure across advertisers, not any single line or image. Copy a structure to adapt, not a creative to clone.
- Copying a funnel whose claims you can't make. A structurally clever funnel built on aggressive or borderline claims is a conversion lesson, not a template — copying it inherits its compliance risk.
- Letting findings die in a browser tab. A native example with no provenance, no reasoning, and no next action is decoration. Save with full context and convert it into a brief, or the research evaporates.
The costliest error is the first, and it is the one this guide is named against: treating visible as proven. It is so tempting on a network where you can see a competitor's creative in detail, and so dangerous on margins where a guessed winner can drain a budget before you notice. The discipline that prevents it is the same one that prevents all the others: separate observed fact from private inference, attribute correctly, read the full funnel including its risk, and validate against your own economics before you scale. Hold that line and Revcontent research sharpens you; drop it and it becomes a confident way to copy other people's losses.
Is There a Public Revcontent Ad Library? The Honest State of Native Transparency
Given how much social-ad research now relies on official libraries, it is reasonable to ask whether there is a Revcontent ad library you can search. The honest answer is no, not in the way the Meta Ad Library exists for social — and understanding why shapes how you have to research the network.
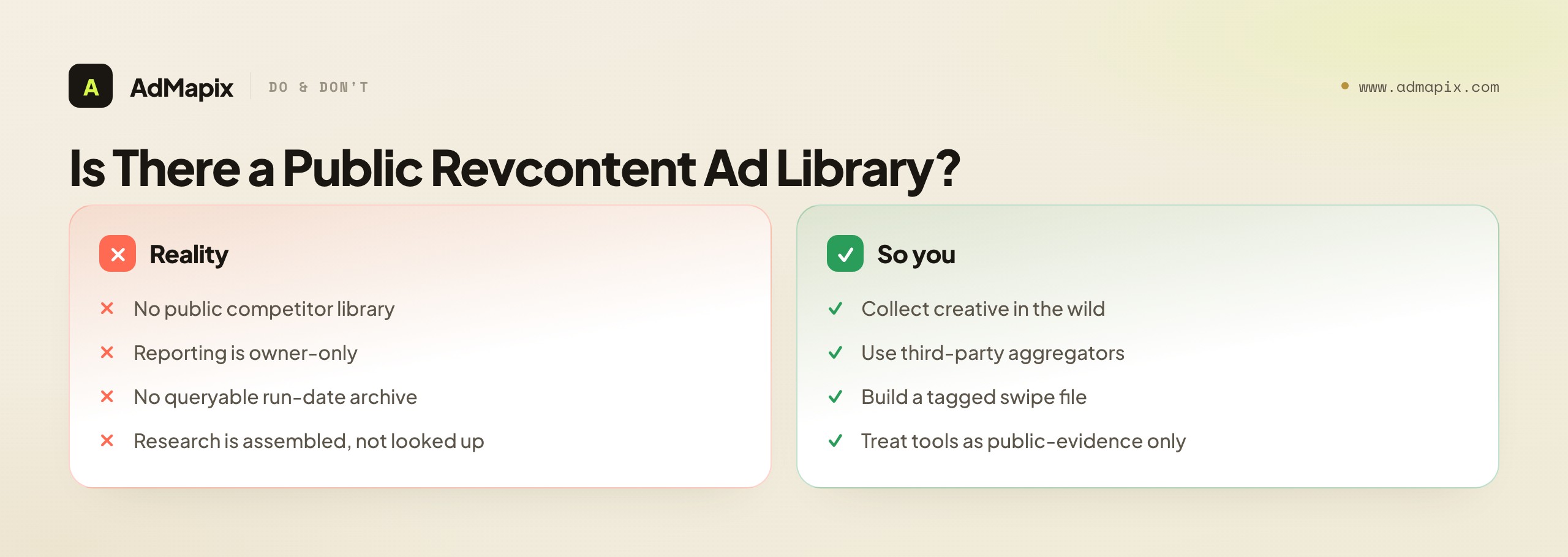
Native content-recommendation networks were not built under the political-ad transparency mandates that forced social platforms to publish public ad libraries, and Revcontent in particular does not offer a public competitor library where you can look up another advertiser's creatives, run dates, and placement detail. Its reporting and targeting tools serve the account owner, not the public or competitors. The practical consequence is that Revcontent research is assembled, not looked up: you gather creative evidence from the network in the wild as you browse publisher sites, from third-party native-research tools that index native ads across publishers, and from your own disciplined collection. There is no single authoritative source to query, which is exactly why the workflow above emphasizes capturing full context and building your own well-organized, well-tagged collection — in the absence of an official library, your own swipe file is the closest thing you have to a searchable archive of your vertical.
This is also where third-party native ad spy tools earn a real but bounded place. Because there is no official Revcontent library, tools that crawl and index native creative across publishers do genuine work — they aggregate what is otherwise scattered and let you search and filter faster than browsing by hand. The honest framing is that they are aggregators of public creative evidence, not windows into private metrics. They can show you more native creatives, faster, and help you spot cross-advertiser patterns; they cannot show you spend, CPM, or ROAS, because that data is not theirs to have. Use them for the breadth and speed they genuinely add, and hold their output to the same observed-versus-inferred standard you hold your own collection. A tool that claims to show competitor spend on a network with no public spend data is overclaiming exactly the way this guide warns against — treat such claims with the skepticism the thin margins demand.
Reading the Retargeting Trail and Creative Rotation
Two of the more advanced things you can read from public Revcontent evidence are the retargeting trail and the creative rotation pattern — both observed entirely from ads served to you over time, and both rich sources of strategy hypotheses when read with the right humility.
The retargeting trail is what you observe after you click a competitor's native ad and genuinely engage with their funnel. Because retargeting is served based on your behavior, you can deliberately trigger a competitor's retargeting and watch the sequence of creatives they use to bring a visitor back over the following days — whether they lead with a discount, a testimonial, an urgency message, or a fresh angle, and how that sequence is paced. On thin-margin arbitrage, the retargeting sequence is especially telling, because operators who retarget at all are usually the more sophisticated ones managing the full funnel economics rather than buying clicks and hoping. The honest caveats hold: you observe the creative sequence, not the targeting rules or the spend behind it, and a single trip through a funnel is a sample, not a complete map. Trigger it more than once before treating the sequence as their settled approach, and read it as a source of strategy hypotheses ("they seem to lead with social proof, then discount"), never as a measured fact.
Creative rotation is the pace at which an advertiser refreshes headlines and thumbnails, and it hints at how they manage creative fatigue — a real constraint in native, where a winning pair sees declining click-through as the audience grows numb. By observing an advertiser over weeks, you can read their rotation from public evidence alone: do they run the same few pairs for a long time, or constantly introduce new variations on the same structure? An advertiser who rotates frequently while keeping the underlying structure constant is telling you the structure works and they are refreshing the surface to fight fatigue — a sign of a disciplined operator. One who changes structure entirely is either still testing or responding to something that stopped working. The caveats are the same as always: you observe that creatives rotated, not the performance data that drove it, so you are inferring fatigue management from behavior, not measuring it, and your observation is a sample. Read rotation as a lens on a competitor's sophistication rather than a precise metric, and it becomes a genuinely useful signal — a disciplined rotator is usually a more serious competitor than one running the same stale pair for months, and knowing which kind you are studying shapes how much weight to give their patterns.
Reading Revcontent Ads by Content Vertical
Native creative does not behave the same across verticals, and on a content-arbitrage-heavy network like Revcontent the vertical shapes both the creative and the compliance picture. Reading native ads well means knowing the conventions — and the risks — of the space you research.
In health and supplements, one of native arbitrage's largest categories, the creative leans on curiosity gaps and authority transfer, with long advertorials building a problem-agitation-solution narrative before a supplement offer or subscription. This is also the vertical with the highest compliance sensitivity, because health claims attract scrutiny, so reading the claim aggressiveness of each funnel matters most here. In personal finance, hooks lean on specific numbers, localized eligibility angles, and an insider tone, with landing paths often running through quizzes that qualify before an offer — and again, claims around money carry regulatory weight worth noting. In ecommerce and direct-response, native increasingly runs clearer product shots and benefit-led headlines with shorter paths to a product page, and the compliance picture is usually lighter. In content-arbitrage entertainment — the "you won't believe what happened next" category — the creative is pure curiosity and the landing path is often a multi-page slideshow monetized by display ads rather than a product sale, which is the purest form of arbitrage and the one where margins are thinnest and "is this profitable" is hardest to read from outside.
The lesson is to research within your vertical's conventions and be cautious transplanting patterns across them. A curiosity-gap health structure that converts cold traffic may fall flat in direct-response ecommerce, and a claim that is borderline-acceptable in entertainment arbitrage may be a serious compliance problem in health or finance. Organize your collection by vertical, note the compliance posture per vertical, and treat any cross-vertical pattern as an experiment rather than a proven play. Knowing the grammar — and the risk profile — of your specific native vertical is what separates research that informs sustainable tests from research that produces briefs that either do not convert or invite trouble.
The vertical lens also changes how much weight to give the visible-scale signal, which ties back to the honesty discipline. In a thin-margin entertainment-arbitrage vertical, visible scale is the weakest possible signal — operators churn through creatives at volume and tolerate losses while hunting for a configuration, so "running everywhere" tells you almost nothing. In a more direct-response ecommerce vertical with clearer offer economics, visible persistence is a slightly stronger (though still imperfect) signal, because the margins are usually less razor-thin and an advertiser is less likely to sustain a clear loss for as long. Calibrating your skepticism to the vertical's economics is a subtle but real skill: the same observed pattern deserves more caution in pure arbitrage and a little less in cleaner direct-response, and a researcher who applies one flat level of skepticism across all verticals will be both too credulous in the thin-margin spaces and needlessly dismissive in the cleaner ones. Read the signal through the lens of the vertical's economics, and your hypotheses get sharper.
A Worked Walkthrough: Researching One Revcontent Advertiser End to End
To make the discipline concrete, here is how a careful session researching a single Revcontent advertiser runs, from first sighting to a defensible brief. Suppose you spot a supplement advertiser's native widget in your vertical and want to understand their whole approach without overclaiming what you can see.
You start by attributing correctly: you note that the widget placement and the "sponsored" disclosure are platform-defined, and you focus your study on the advertiser's actual choices — the headline (say, an authority-transfer curiosity gap), the thumbnail (an everyday editorial-style image), and the angle. You record both with provenance: the publisher context, the date, the disclosure framing, and the advertiser where disclosed. Then you follow the click. It lands on an advertorial, so you map its arc — the problem it opens on, where it agitates, where proof lands, how it transitions to the offer — and you read its compliance posture, noting that the health claims run moderately aggressive and the disclosure is present but easy to miss. You record that risk read explicitly, because it determines whether this is a pattern you would actually adopt.
Next you broaden, and this is where the honesty discipline does its work. You look for the same advertiser's other native widgets across publishers and find three more, all variations on the same authority-transfer structure leading to similar advertorials. That cross-placement repetition is a real signal — the structure appears to survive the auction. But you deliberately stop short of concluding it is profitable: on thin arbitrage margins, you cannot know whether this operator is winning, breaking even, or chasing a loss, and you write your notes to say exactly that. Finally, you convert it into a brief that respects the boundary: "test an authority-transfer curiosity-gap structure leading to an advertorial with this arc — but built on claims we can substantiate — for our offer, and validate against our own traffic cost and conversion before scaling." That brief is the product of the research: a defensible, testable hypothesis grounded in an observed, repeated pattern, with every private-metric assumption and every borderline claim explicitly excluded. That end-to-end discipline — attribute, capture, read the risk, refuse to overclaim, brief defensibly — is what separates research that drives sustainable tests from a folder of screenshots and guesses.
Building a Native Swipe File That Compounds
A swipe file is only valuable if it is organized to answer future questions, and on a network where honesty is the core skill, the most valuable thing your file can record is not just the creative but your assessment of it — what you observed, what you could not prove, and what the compliance risk was. Most swipe files are a chronological dump of screenshots that gets less useful as it grows; a Revcontent swipe file built to compound is structured to preserve judgment, not just images.
File each example by what it teaches and tag it consistently: the headline structure, the thumbnail archetype, the offer type, the landing-path structure, the vertical, the compliance-risk read, the date, and an explicit "observed, not proven" note on what you could and could not determine. With those tags, the file becomes queryable in the ways that matter on this network — you can pull every health-vertical example with a moderate-risk advertorial path, or every structure that repeated across multiple advertisers (your strongest signals), and study the pattern across them rather than scrolling a feed. The compliance-risk tag in particular is a Revcontent-specific addition worth the discipline: it lets you later filter for patterns that are both effective-looking and defensible, which are the only ones you actually want to adopt.
The compounding comes from this queryability plus a periodic review loop. A file of fifty well-tagged, honestly-assessed examples is more useful than five hundred raw screenshots, because the fifty can answer a specific question — and a defensible one — in seconds. Every month, read back through what you saved and fold in your own results: which patterns you tested, how they performed against your real economics, and which observed-but-unproven competitor signals turned out to be real winners for you versus mirages. That loop is what turns the swipe file from a one-way archive into a learning system, and on thin margins it is the most valuable asset you can build, because a pattern you observed and then validated for your own offer is worth infinitely more than a competitor sighting you only assumed was working. The file that records both the observed pattern and your verified result is the closest thing to a private edge that native research can give you.
When You Don't Need a Paid Revcontent Spy Tool
It is worth being honest that not everyone needs a paid Revcontent ad spy tool, because for some teams a disciplined manual process covers the job at no cost — and on a network where the core skill is judgment rather than data access, the manual path is more viable than on data-heavy channels.
If you research native occasionally, work in a single vertical, and watch a small competitor set, you can get a long way by browsing publisher sites in your vertical, collecting the recommendation widgets you see, following the clicks, reading the funnels for both conversion logic and compliance risk, and maintaining a well-tagged, honestly-assessed swipe file by hand. The honest limit of the free path is breadth and speed — you only see what you happen to browse, you cannot search across the whole network, and the collection is slow. For light, focused, judgment-driven research, that is often an acceptable trade, especially because the most valuable Revcontent skill — refusing to overclaim and reading risk — is a discipline you apply manually regardless of tooling.
You start to need a paid tool, or a creative-intelligence layer, when the manual process stops scaling: when you need to research many advertisers across the whole network rather than the slice you stumble onto, when you need to search and filter native creatives quickly, when findings have to be saved, tagged, and turned into reports for a team, or when your research has to span native plus other channels in one place. The signal that you have outgrown the free path is the manual stitching tax — re-finding ads you know you saw, rebuilding context, assembling scattered screenshots into a report for the third time this month. Until you feel that tax, the free path is genuinely fine and paying would be premature; once you feel it weekly, a tool that aggregates native creative and supports a real research-and-reporting workflow pays for itself. Match the spend to the actual scale of your research, and remember that no tool substitutes for the honesty discipline — a paid aggregator gives you more creatives faster, but it is still on you to refuse to overclaim what they prove.
When a Creative-Intelligence Layer Helps
Once the missing piece is reusable, cross-network creative research — saving native examples, analyzing landing and video structure, tagging patterns, and turning them into reports — a gap opens that browsing publishers and screenshotting cannot close, and that a single-network tool cannot fully close either.

A creative-intelligence layer like AdMapix fits here. It is built for teams that need to search ad creatives across networks with Search, save the media in Media, break down video and landing structure with Video Analysis — the hook, the proof, the CTA that a static thumbnail cannot show — tag what they find, and turn it into a Report. The reason this is a genuinely separate layer rather than a feature a native tool should bolt on is that the job is different in kind: a native spy tool is organized around finding native creatives, while a creative-intelligence layer is organized around the creative as a reusable research artifact you can search, dissect, tag, and report across networks. For a team whose competitors run native on Revcontent and on other recommendation networks and video on social, following an advertiser across all of them in one workbench is the difference between a partial and a complete read. Crucially, a creative layer is bound by the same honesty boundary as everything else — it is built on public creative evidence and does not invent private metrics — which is exactly the discipline a Revcontent researcher should demand. Compare access on Pricing once the workflow repeats, or log in to run your first cross-network search.
It is honestly not the right tool if all you need is to browse Revcontent's native recommendations occasionally in one vertical — a disciplined manual process covers that, and a creative-intelligence layer would be capacity you do not use. A creative layer earns its place specifically when observed native creatives have to become structured, searchable, shareable evidence with landing and video analysis, across more networks than Revcontent alone, for a recurring team workflow. Name the gap first: occasional single-vertical native browsing stays manual, network-wide native aggregation points to a native spy tool, and cross-network reusable research-and-reporting points to a layer like AdMapix — which complements, never replaces, your own validation against real cost-and-conversion data.
For the broader native and ad-spy landscape, our Outbrain ad spy tool and Taboola ad spy tool guides apply the same research discipline to the two largest native networks, the native ad spy tool guide covers the category across networks, and the best ad spy tools of 2026 compares the whole field by price, coverage, and use case. For the honest limits on inferring competitor spend, tracking competitor ad spend goes deeper on what is and is not knowable.
FAQ
What is a Revcontent ad spy tool?
A Revcontent ad spy tool is any tool or disciplined process for researching the native ads running across Revcontent's content-recommendation network — the headlines, thumbnails, content angles, and landing paths that are publicly observable. It reveals creative evidence you can study and learn from, not private performance data. The best ones aggregate native creatives across publishers so you can search and filter them, but all of them are bound by the same limit: they show what is running, not how well it is doing.
Can a Revcontent ad spy tool show competitor spend?
No. Revcontent does not publish a competitor library, and advertiser spend, bids, CPM, click-through rate, conversion rate, ROAS, and targeting are not public. No public tool can infer them reliably, so any such figure is a modeled estimate or a guess and should be treated as such, never as fact. A tool claiming to show competitor spend on a network with no public spend data is overclaiming — exactly the failure mode disciplined Revcontent research is built to avoid.
Why is the honesty discipline so important on Revcontent specifically?
Because much of Revcontent's inventory is content-arbitrage and affiliate traffic, which runs on thin margins. On thin margins, the same creative can be profitable for one operator and a loss for another at the same apparent scale, so "visible everywhere" tells you almost nothing about profitability. Over-claiming — treating visible as proven — is therefore both more tempting and more costly here than on high-margin brand surfaces, which is why refusing to overclaim is the core skill.
How do I tell platform rules from a competitor's creative choices?
Attribute carefully. Placement style, disclosure labels, and widget behavior are defined by Revcontent's format — they are how the network works, not a competitor's decision. The headline, thumbnail, content angle, offer, and landing page are the advertiser's choices, and those are the testable variables worth studying. Crediting an advertiser for a platform rule, or studying a platform behavior as if it were a creative strategy, leads you to draw lessons from things that were never anyone's creative decision.
What should I capture from each Revcontent ad example?
Capture placement context (publisher category, page type, disclosure label, device, region), creative evidence (headline, thumbnail, angle, claim, CTA), the landing path (advertorial, quiz, ecommerce, lead form, plus its compliance risk), the advertiser signal where disclosed, and your one-line reason for saving. That full context is what turns a screenshot into a reusable, actionable data point. A creative saved with only the image is something you will not be able to use; the same creative with its context and your reasoning is intelligence.
Why does compliance risk matter in Revcontent research?
Because native arbitrage often involves health, finance, and supplement offers where claims can run aggressive, and a funnel winning today can be one enforcement action from being shut down. Reading the compliance posture of each landing path — how aggressive the claims, how clear the disclosure — tells you both whether a pattern is safe to adopt and what kind of competitor you are studying. A structurally clever funnel built on claims you could not make is a conversion lesson, not a template; the patterns worth copying are the ones that are both effective and defensible.
How do I know if a native ad is actually working?
You do not, from public evidence alone, and on Revcontent's thin margins you should be especially humble about it. Frequency and longevity are weak proxies — operators run things at a loss longer than you would expect. The strongest public signal is a structure repeating across many independent advertisers, which suggests it survives the auction, but even that is a hypothesis about your own economics. The only way to know whether a pattern works is to test a version of it against your own traffic cost, conversion, and margin data.
Is there a public Revcontent ad library I can search?
No, not the way the Meta Ad Library works for social and political ads. Native networks were not built under the same transparency mandates, and Revcontent does not offer a public competitor library with run dates and placement detail. Research is assembled — from creative seen in the wild, from third-party native-research tools that index native ads across publishers, and from your own organized collection — rather than looked up in one official source. In that absence, your own well-tagged swipe file is the closest thing to a searchable archive of your vertical.
How is researching Revcontent different from Taboola or Outbrain?
The research discipline is the same across native networks — read the headline-and-thumbnail pair, follow the click, separate observed facts from private metrics — but Revcontent's inventory skews more toward content-arbitrage and affiliate traffic, which makes the thin-margin honesty discipline and compliance-risk reading especially central. The Taboola and Outbrain networks are larger and include more premium-publisher placements, so the same patterns may appear in different contexts. Research each within its own network's conventions rather than assuming they are interchangeable.
Can I research Revcontent ads for free?
Yes, for light, focused research. If you work in one vertical and watch a small competitor set, you can browse publisher sites, collect the recommendation widgets you see, follow the clicks, read the funnels, and maintain a tagged swipe file by hand at no cost. The limits are breadth and speed — you only see what you browse and cannot search the whole network. You start to need a paid native tool or a creative-intelligence layer when you need network-wide search, fast filtering, team reporting, or cross-network research the manual process cannot scale to.
Key Takeaways
- A Revcontent ad spy tool reveals public creative evidence — headlines, thumbnails, angles, landing paths — and proves what is running, never what is winning. There is no public competitor library, so treat every spend or ROAS figure as a guess.
- Refuse to overclaim — it is the core skill on Revcontent. Thin content-arbitrage margins make "visible everywhere" a weak signal, so extract testable structures and validate against your own economics rather than copying guessed winners.
- Attribute correctly and read the full funnel. Separate platform rules from advertiser choices, and study the landing path for both its conversion logic and its compliance risk before adopting any pattern.
- The win is the repeating, defensible pattern, not the single ad. A structure recurring across many independent advertisers is the strongest public signal; convert it into a tagged test backlog with full provenance.
- Match the tool to the job. Light single-vertical research can stay manual; network-wide aggregation needs a native spy tool; cross-network reusable research-and-reporting points to a creative-intelligence layer like AdMapix — bound by the same honesty boundary, and complementing your own validation rather than replacing it.
Sources
- Revcontent — native advertising and content-recommendation platform connecting advertisers to audiences across publisher sites (as checked June 2026).
- Revcontent for advertisers — native ad formats, targeting, and reporting tools from the platform's own perspective; advertiser-facing and owner-only, not a public competitor library.
- Revcontent native advertising overview — the platform's framing of native as paid sponsored content designed to blend with the surrounding page through content-recommendation placements.
- Meta Ad Library — referenced as the contrast case for what a regulatory-driven public ad library looks like, which native networks do not provide (as checked June 2026).
Platform features, formats, and public surfaces change often, so confirm current details on Revcontent's official pages before relying on them. All links checked as of June 21, 2026. Disclosure: AdMapix is our own product, and its data scope covers cross-network ad creative search, saved media, video and landing analysis, tagging, and reports built on public evidence — separated from claims about Revcontent's own platform.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Ad Hook Examples in 2026: 7 First-3-Second Patterns (with UGC Breakdowns)
A complete 2026 library of ad hook examples organized into seven repeatable patterns — problem, proof, objection, comparison, curiosity, offer, and transformation — with UGC hook breakdowns, platform-by-platform differences for TikTok, Meta, and YouTube, an industry-by-industry hook map, a hook-testing workflow that ships variants, the metrics that actually grade a hook, and a worked teardown that turns a competitor opener into a running test.

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.
Outbrain Ad Spy Tool in 2026: Native Ad Research for the Open Web
How to research Outbrain native ads from public evidence in 2026 — what a spy tool can and cannot prove, how to decode headline-and-thumbnail hooks, advertorial landing paths, retargeting trails, and how to turn patterns into testable native campaigns.