Meta Ads Library API 2026: Graph API v20.0, Impressions, Spend & Python
Developer guide to the Meta Ads Library API: Graph API v20.0 endpoints, free access limits, impressions/spend fields, Python and curl examples, CASD access, and why commercial ads differ from the UI.
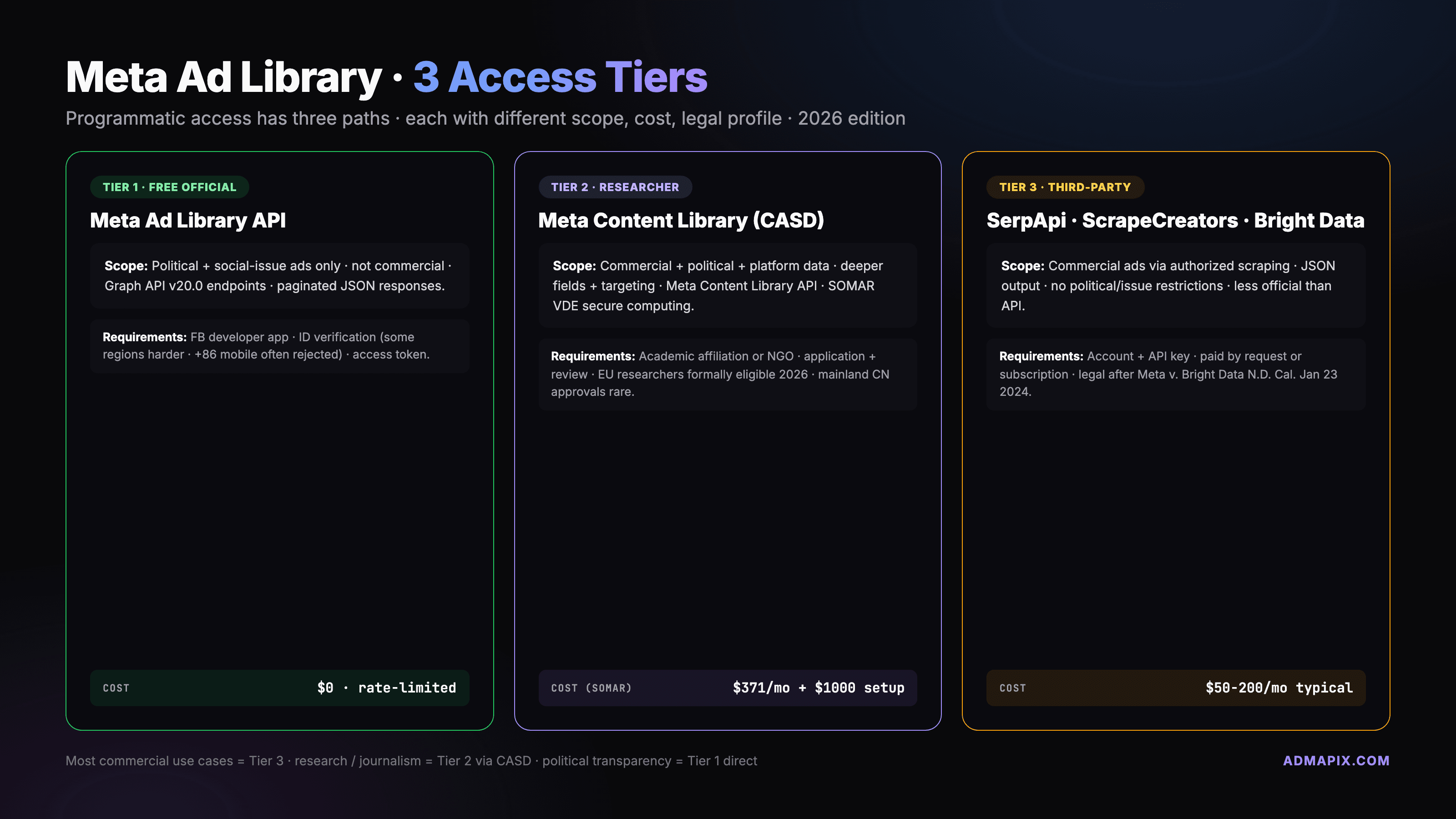
The Meta Ad Library API is Meta's official developer endpoint for programmatic access to the public ad archive — but it's scoped to political + social-issue ads only. For commercial-ads programmatic access you need either Meta Content Library (CASD, researcher-gated) or third-party services like SerpApi. Here's the full API guide with Python + curl samples tested against Graph API v20.0 in April 2026, access tiers, rate limits, and the legal landscape after Meta v. Bright Data.
Quick answers for API searchers:
- Graph API version: examples below use
v20.0, verified in April 2026. - Free access: the developer-tier Ad Library API is free, but rate limited.
- Impressions / spend: available as bucketed transparency fields, not exact campaign metrics.
- Commercial ads: visible in the browser UI, but most commercial ads do not come back from
/ads_archive; use CASD or a third-party commercial ad dataset.
By the AdMapix Engineering Team — Updated April 16, 2026
The two questions every engineer asks when they first hit /ads_archive are: "why is my commercial competitor not returning results?" and "why does my token die after 60 days?" Both have the same answer — the Ad Library API is a compliance instrument Meta built to satisfy transparency legislation (Honest Ads Act, EU DSA, India ECI), not a marketing intelligence product. Understand that framing and the rest of this guide clicks into place.
This post covers scope, access flow, request patterns, response schema, and rate limits, then hands you drop-in Python and curl samples against Graph API v20.0 (current stable, April 2026). We also cover the CASD researcher tier for commercial ads, the third-party landscape after Meta v. Bright Data, and the friction points Chinese technical teams hit.
What the Meta Ad Library API Actually Is (vs the UI)
The Meta Ad Library is two distinct products sharing one name. The UI at facebook.com/ads/library shows every active ad Meta runs — commercial and political — with a 90-day window for commercial and seven years for political. The API (/ads_archive on the Graph API) is strictly a subset: political and social-issue ads, plus Housing/Employment/Credit special categories in the US, all with seven-year retention.
That mismatch trips up every first-time user. You can see a Nike commercial ad in the browser UI, query the same page_id through the API, and get an empty result set — not a bug, just that the API's ad_type=ALL means "all within the political+issue+special-categories scope." Commercial ads have no API path on this endpoint.
The second structural difference is the response format. The API returns JSON with text fields, bounded spend/impression ranges, and an ad_snapshot_url — a token-bearing URL back into the Ad Library's web preview. You do not get direct binary URLs to the creative video or image. If you need the media bytes, you have to follow the snapshot URL and extract client-side. (See our Meta Ads Library video download guide for extraction patterns.)
Third: the 200 calls / user / hour quota is per access token, not per app. Rotating tokens across a team does not bypass anything — it just gives Meta a cleaner picture of how many humans are behind the account.
API Scope — What You Can Query
The /ads_archive endpoint has four effective scopes encoded in the ad_type parameter:
ALL— union of the below, scoped to countries where the ad met the political/issue classifier thresholdPOLITICAL_AND_ISSUE_ADS— default and largest bucket; global since 2019 for declared political, with issue-ads classifier rollout dates varying by countryHOUSING_ADS/EMPLOYMENT_ADS/CREDIT_ADS— US-only special categories under the 2019 HUD/NFHA settlement; covers all housing/employment/credit ads in the US regardless of political content
Omissions: no ecommerce ads, no app-install ads, no brand campaigns, no Reels sponsored posts. "Can I pull every Shein ad in Germany last week through this API?" — no. Those are commercial ads; you need the Content Library path or a third-party source.
Retention: political/issue ads stay seven years from last delivery. Housing/employment/credit stay four years under settlement terms. The archive is append-only — nothing gets deleted once classified correctly at ingest.
Who Can Access — Developer Tier vs CASD Researcher Tier
The free developer tier is open to anyone with a Meta account who completes identity verification at facebook.com/ID. Upload a government ID (passport, national ID, driver's license), confirm country of residence, wait one to three business days. Once approved, create a Meta for Developers app, add the "Ad Library API" product, and start issuing access tokens.
The Content Library and Content Library API — the path for commercial ads and richer metadata — goes through a separate researcher approval pipeline managed by CASD (Centre d'Accès Sécurisé aux Données), the French secure data access center. As of 2026 Q1, CASD's EU researcher tier is formally open after the 2025 pilot wrapped. Eligibility: academic institution, NGO, or credentialed news organization affiliation, plus a specific research question in a data management plan.
CASD access is free for qualified researchers, but the commercial analytical environment — SOMAR VDE, the secure virtual desktop where you actually query Content Library data — costs $371 per team per month plus a one-time $1,000 project setup fee as of January 2026. That replaced 2024's flat academic pricing and reflects a shift toward sustainable cost recovery. Most newsroom work still happens on the free /ads_archive plus scraping hybrid.
A third quasi-tier: the Ad Library Report, a weekly CSV dump by country that does not require an API key. As of 2026 it includes a new low-impression filter (excludes ads below 1,000 impressions) to reduce noise for bulk analysis. For aggregate reporting it's often faster than paginating the API.
Getting Access — Step-by-Step App Setup
The onboarding sequence trips up most developers on one of three gates. Clean path:
- Create a personal Facebook account, visit
developers.facebook.com, accept the platform policy. - Complete ID verification at
facebook.com/ID. Upload passport or equivalent. One to three days. Per person, not per app; must match the legal name on your developer account. - Create a new app at
developers.facebook.com/apps. App type "Other", use case "Business". Name it descriptively — it appears in audit logs. - From the app dashboard, Add Products → Ad Library API. Accept the "Authorized Access to Public Information" terms. This unlocks
/ads_archivefor tokens issued by your app. - Generate a user access token via the Graph API Explorer. Select your app, request
ads_readandpublic_profile, click "Generate Access Token." Short-lived is one hour; exchange for a long-lived (60-day) token via/oauth/access_token(sample below). - Add a System User in Business Manager for a non-expiring server-side token. Requires a verified Business Manager, which requires business documentation — the path most production integrations take.
Chinese-market note: ID verification specifically rejects mainland China (+86) mobile numbers for SMS confirmation. Your passport passes; the phone verification fails. The pragmatic workaround is registering under a Hong Kong or Singapore entity with a local SIM — also what you need for Business Manager in production. Mainland IPs on the developer console work fine; the friction is strictly identity verification.
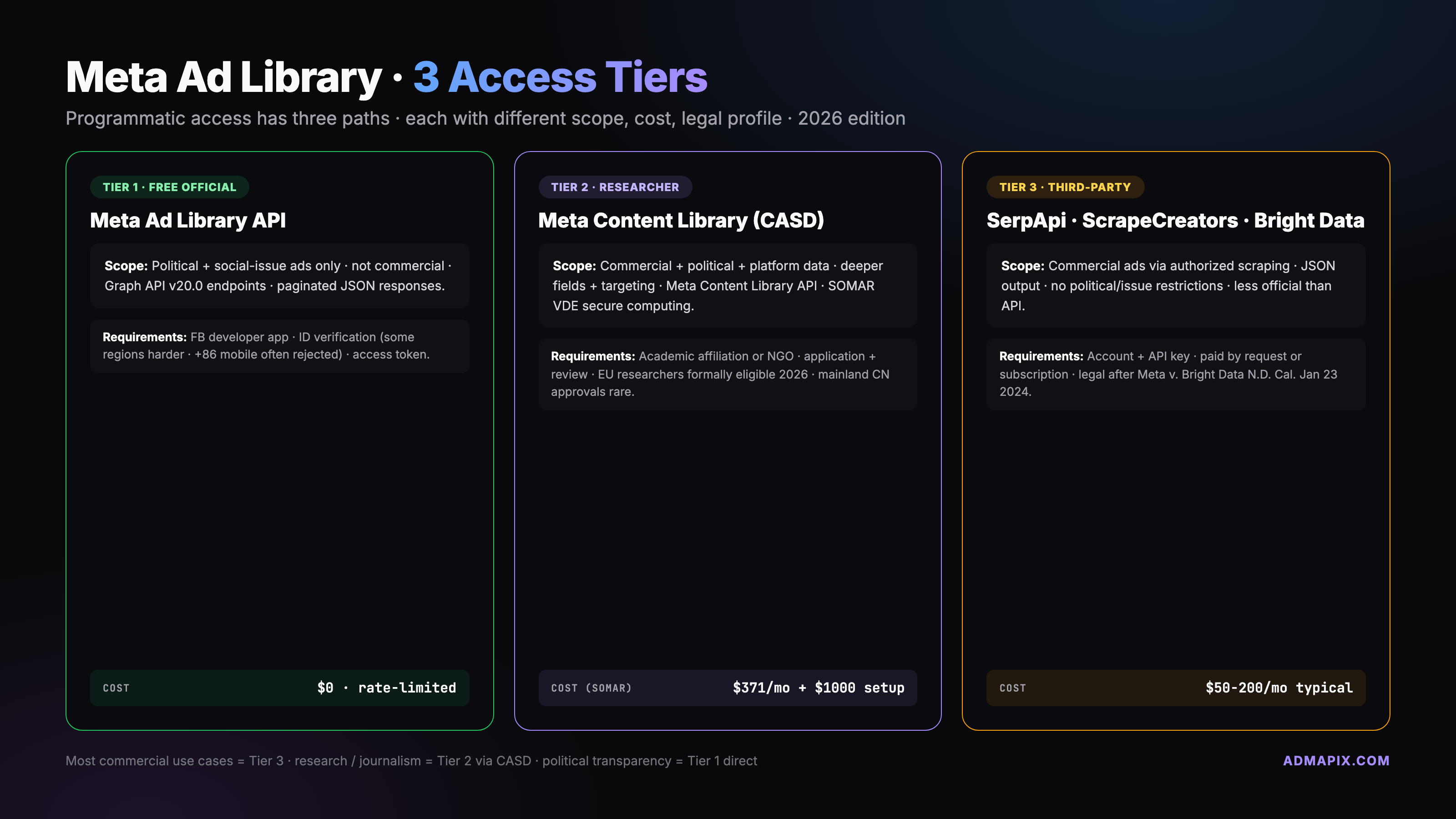
Core Endpoints and Query Parameters (v20.0, Verified April 2026)
There is effectively one endpoint: GET /ads_archive. The request surface is the parameter matrix, not multiple URLs. Parameters that matter, with current v20.0 behavior:
search_terms— free-text match against ad copy. Weak fuzzy matching; quote for exact phrase.search_page_ids— comma-separated page IDs. Authoritative when you know the advertiser.ad_reached_countries— required. Array of ISO-2 codes. Determines classifier scope.ad_type—ALL|POLITICAL_AND_ISSUE_ADS|HOUSING_ADS|EMPLOYMENT_ADS|CREDIT_ADS. Default isPOLITICAL_AND_ISSUE_ADS.ad_active_status—ACTIVE|INACTIVE|ALL. UseALLfor historical analysis.ad_delivery_date_min/ad_delivery_date_max— ISO date strings.publisher_platforms— array; valuesFACEBOOK,INSTAGRAM,AUDIENCE_NETWORK,MESSENGER,THREADS(added 2024-09).media_type—ALL|IMAGE|MEME|VIDEO|NONE.languages— ISO-639-1 codes.fields— comma-separated projection. Most important parameter — defaults return almost nothing useful.limit— page size. Max 5000, real-world stable ceiling 1000 for political/issue; API silently reduces beyond that on heavy fields.
v20.0 behavior changes: search_terms is now rejected without ad_reached_countries, and requests missing ad_type on US surfaces default to POLITICAL_AND_ISSUE_ADS rather than ALL. Re-check these two if you're porting 2023-era code.
Response Schema — Fields That Actually Ship
The default response includes id and nothing else useful. Add a fields parameter. Active v20.0 schema:
id— opaque archive ID.ad_creation_time— submission timestamp.ad_delivery_start_time/ad_delivery_stop_time— first/last delivery.ad_creative_bodies— array of primary text strings (multivariate ads have more than one).ad_creative_link_titles/ad_creative_link_captions/ad_creative_link_descriptions— headline, display URL, description.ad_snapshot_url— permalink to the rendered ad (token-bearing, expires).page_id/page_name— advertiser.publisher_platforms— which surfaces delivered.impressions—lower_bound+upper_bound(buckets 0-999, 1K-5K, 5K-10K, up to 1M+).spend—lower_bound,upper_bound,currency.demographic_distribution—age,gender,percentageper segment.region_distribution/delivery_by_region— regional breakdowns.languages— detected ad languages.target_ages/target_gender/target_locations— declared targeting (sometimes null).beneficiary_payers— EU-only, added under DSA: who paid and benefits.eu_total_reach— EU DSA reporting field.
The impressions and spend ranges are the field every analyst trips on. Meta publishes only buckets — no exact spend. For modeling, take the geometric mean of bucket endpoints and acknowledge the residual error in methodology notes.
Rate Limits and Quota Management
Published limit: 200 calls per user access token per hour, enforced as a rolling window. In practice, pulls chaining many large-field pages hit HTTP 400 with code: 613 well below the nominal limit — Meta throttles on an internal cost estimate, not raw call count.
Three patterns that hold under load:
- Use
limit=500with full field projection over smaller pages with more pagination. Saves per-call overhead against the hourly budget. - Cursor pagination only. Offset pagination was deprecated on archive endpoints in 2023. Use
paging.nextfrom the response. - Back off on 613 for 60 seconds, then resume. Sliding window — full-hour sleeps waste time.
For bulk work — every political ad in the EU over 30 days — the Ad Library Report CSV is correct, not the API. Weekly dumps are precomputed and do not consume API quota. The 2026 low-impression filter lets you drop sub-1K-impression ads at download time, which used to make the German and French CSVs tens of gigabytes.
Working Code Samples (Python + curl, Graph API v20.0, Tested April 2026)
All samples below were tested against https://graph.facebook.com/v20.0/ads_archive on April 15, 2026. Export your long-lived access token as an environment variable before running.
1. Curl — basic request
export META_TOKEN="EAAxx..." # your long-lived access token
curl -G "https://graph.facebook.com/v20.0/ads_archive" \
--data-urlencode "access_token=${META_TOKEN}" \
--data-urlencode "ad_reached_countries=['US']" \
--data-urlencode "ad_type=POLITICAL_AND_ISSUE_ADS" \
--data-urlencode "ad_active_status=ALL" \
--data-urlencode "search_terms=climate" \
--data-urlencode "fields=id,page_name,ad_creative_bodies,impressions,spend,ad_delivery_start_time" \
--data-urlencode "limit=100"
2. Python — authenticated search with a clean client
# tested on Graph API v20.0, April 2026
# requires: pip install requests==2.32.*
import os
import requests
from typing import Any
META_TOKEN = os.environ["META_TOKEN"]
BASE = "https://graph.facebook.com/v20.0/ads_archive"
DEFAULT_FIELDS = ",".join([
"id", "page_id", "page_name",
"ad_creative_bodies", "ad_creative_link_titles",
"ad_delivery_start_time", "ad_delivery_stop_time",
"publisher_platforms", "impressions", "spend",
"demographic_distribution", "region_distribution",
"ad_snapshot_url", "languages",
])
def search_ads(
countries: list[str],
search_terms: str | None = None,
page_ids: list[str] | None = None,
ad_type: str = "POLITICAL_AND_ISSUE_ADS",
limit: int = 500,
fields: str = DEFAULT_FIELDS,
) -> dict[str, Any]:
params: dict[str, Any] = {
"access_token": META_TOKEN,
"ad_reached_countries": str(countries).replace("'", '"'),
"ad_type": ad_type,
"ad_active_status": "ALL",
"fields": fields,
"limit": limit,
}
if search_terms:
params["search_terms"] = search_terms
if page_ids:
params["search_page_ids"] = ",".join(page_ids)
response = requests.get(BASE, params=params, timeout=30)
response.raise_for_status()
return response.json()
3. Python — pagination loop with back-off
import time
from collections.abc import Iterator
def paginate_ads(
countries: list[str],
**kwargs,
) -> Iterator[dict[str, Any]]:
"""Yield every ad matching the query, following cursor pagination."""
payload = search_ads(countries, **kwargs)
while True:
for ad in payload.get("data", []):
yield ad
next_url = payload.get("paging", {}).get("next")
if not next_url:
return
# Follow the signed next URL directly — params are already encoded
resp = requests.get(next_url, timeout=30)
if resp.status_code == 400 and "rate limit" in resp.text.lower():
time.sleep(60)
resp = requests.get(next_url, timeout=30)
resp.raise_for_status()
payload = resp.json()
# usage
for ad in paginate_ads(countries=["DE", "FR"], search_terms="climat"):
print(ad["page_name"], ad.get("spend"))
4. Response parsing — turn bucket ranges into a midpoint estimate
import math
def bucket_midpoint(bucket: dict[str, str] | None) -> float | None:
"""Geometric mean of lower/upper bounds; handles the 1M+ open-ended bucket."""
if not bucket:
return None
lo = float(bucket.get("lower_bound", 0) or 0)
hi_raw = bucket.get("upper_bound")
if hi_raw is None:
return lo * 1.5 # open-ended bucket heuristic
hi = float(hi_raw)
if lo == 0:
return hi / 2
return math.sqrt(lo * hi)
def enrich(ad: dict[str, Any]) -> dict[str, Any]:
return {
"id": ad["id"],
"advertiser": ad.get("page_name"),
"impressions_est": bucket_midpoint(ad.get("impressions")),
"spend_est": bucket_midpoint(ad.get("spend")),
"currency": (ad.get("spend") or {}).get("currency"),
"body": (ad.get("ad_creative_bodies") or [None])[0],
"start": ad.get("ad_delivery_start_time"),
}
5. Error-handling stub — expired tokens, throttling, retries
from requests.exceptions import HTTPError
class MetaAdLibraryError(Exception):
pass
def safe_request(url: str, params: dict | None = None, max_retries: int = 3):
for attempt in range(max_retries):
try:
r = requests.get(url, params=params, timeout=30)
if r.status_code == 401:
raise MetaAdLibraryError("token expired — run /oauth/access_token refresh")
if r.status_code == 400:
body = r.json().get("error", {})
code = body.get("code")
if code == 613:
time.sleep(60 * (attempt + 1))
continue
raise MetaAdLibraryError(f"bad request: {body.get('message')}")
r.raise_for_status()
return r.json()
except HTTPError as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt)
raise MetaAdLibraryError("max retries exceeded")
For the token refresh dance (short-lived → long-lived), hit /oauth/access_token with grant_type=fb_exchange_token and your app's client_id + client_secret + the short-lived token. The long-lived token is valid 60 days; schedule a refresh job at day 55 to be safe.
Meta Content Library via CASD — The Researcher Tier
For commercial ads, the only first-party programmatic path is the Meta Content Library API, accessed through CASD (Centre d'Accès Sécurisé aux Données). The workflow is slower and more formal than the developer tier by design — Meta's bargain with regulators was that commercial ad data is available for public-interest research but not for marketing intelligence.
2026 application flow:
- Submit a research proposal to CASD (affiliation, research question, data management plan).
- CASD's committee evaluates eligibility — four to eight weeks turnaround.
- On approval, researchers access the Content Library via the SOMAR Virtual Data Environment (VDE), a secure remote desktop with pre-installed Python, R, and STATA. As of January 2026, $371 per team per month plus a one-time $1,000 project setup fee.
- Data export is restricted — you run queries and publish aggregated results, but you cannot bulk-download creative media or raw per-ad exports. Each output is reviewed before release.
The Content Library is far richer than /ads_archive: full commercial corpus, creative media pointers, advertiser hierarchies, campaign-level grouping. Right tool for academic work on platform advertising economics. Wrong tool (and against access terms) for brands reverse-engineering competitors.
CASD from mainland China is effectively unavailable — eligibility requires an EU/EEA academic affiliation or credentialed news organization with an EU entity. Mainland-affiliated researchers have been approved on rare collaborations with European universities, but it's not a realistic path.
Third-Party Alternatives — After Meta v. Bright Data
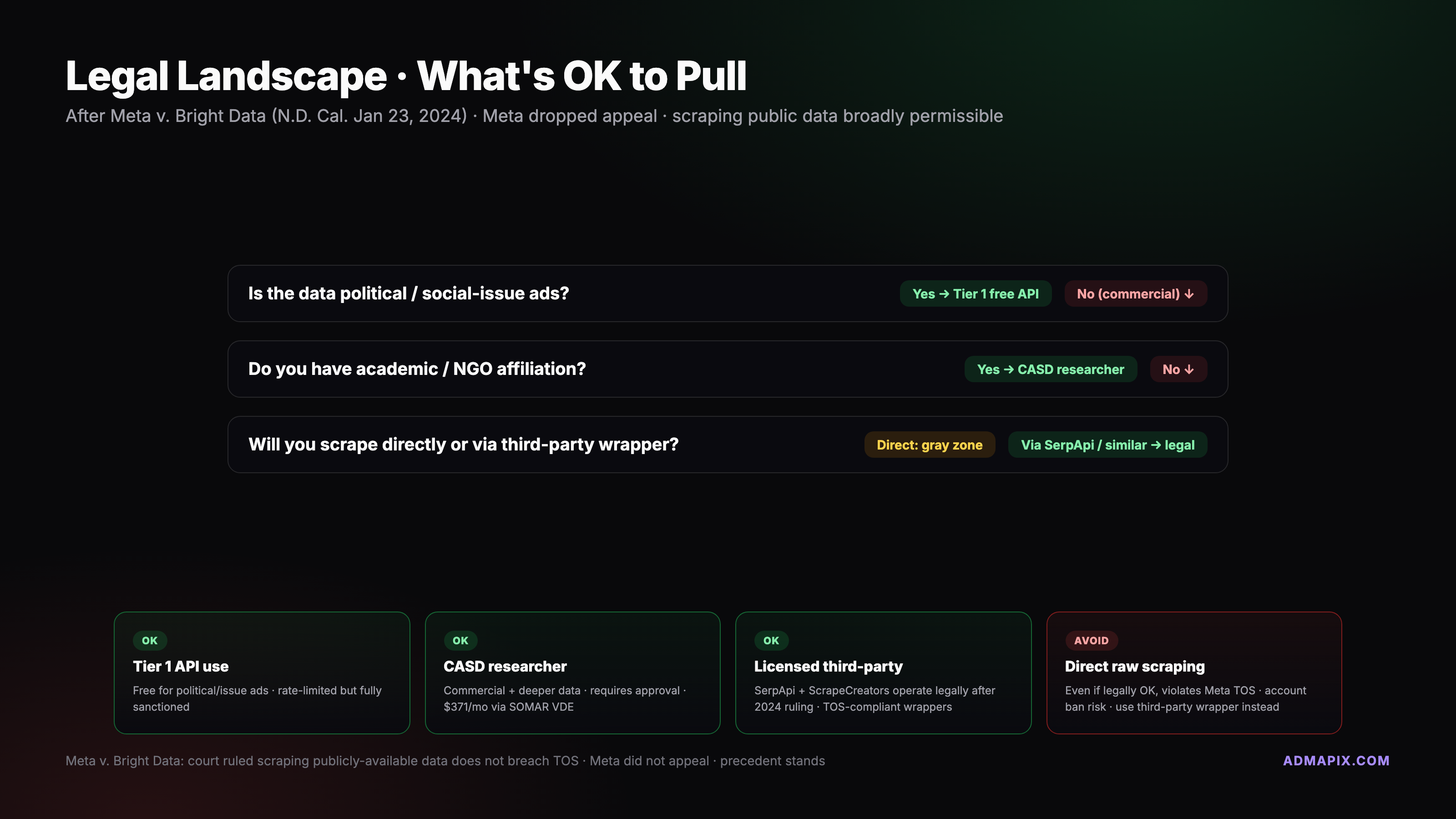
If you need commercial ads programmatically and CASD isn't a fit, the third-party market is where most production systems end up. The legal environment shifted materially in 2024.
The Bright Data ruling. On January 23, 2024, Judge Edward M. Chen of the Northern District of California (N.D. Cal., case 3:23-cv-00077) granted summary judgment for Bright Data against Meta. The finding: scraping publicly accessible, logged-out Meta pages does not violate Meta's Terms of Service because the terms bind logged-in users, not anonymous visitors. Meta filed notice of appeal then dropped the appeal on February 26, 2024, letting the district-court judgment stand. This is a district court ruling, not a Ninth Circuit precedent — persuasive but not binding elsewhere, and Meta retains other tools (technical blocks, state-law claims, targeted litigation). The operating assumption in the scraping market since early 2024: logged-out public-data scraping is defensible in the US.
What the ruling does not cover: logged-in scraping, circumventing authentication, or ignoring robots.txt-equivalent signals. It also doesn't pre-empt GDPR, UK-DP, or other national regimes. Teams scraping at scale pair the 2024 ruling with an EU legal opinion and jurisdictional routing.
Current third-party landscape:
- SerpApi — Meta Ad Library is community issue #2789 with partial coverage; their Google Ads Library wrapper is first-class. See our Google Ads Transparency Center guide for that side.
- ScrapeCreators — pay-as-you-go API with Meta Ad Library, TikTok Top Ads, and other surfaces. $5 starting credits, no monthly minimum — pragmatic for small teams and one-off research.
- Bright Data — post-ruling incumbent. Residential proxy network plus managed Meta Ad Library dataset. Enterprise pricing, strong compliance posture after the 2024 win.
- Swipekit — higher-level SaaS with ad library integration aimed at creative teams, not raw data.
For Chinese technical teams, the hybrid that actually ships is usually SerpApi for Google Ads Transparency Center + ScrapeCreators for Meta Ad Library, fronted by a residential proxy pool and dumped to S3 or R2. This avoids direct outbound requests to Meta from your own infrastructure, which its anti-scraping systems flag aggressively.
When to Fall Back to Paid Spy Tools
The Ad Library API is the right answer for a narrow set of problems: political transparency research, compliance monitoring in housing/employment/credit, academic work on platform advertising. It is the wrong answer if you need:
- Commercial competitor creatives with full video, image, and text for analysis
- Ad performance signals beyond impression buckets — CTR proxies, engagement, scroll-depth
- Campaign structure — same-campaign grouping, budget hierarchy, targeting inference
- Landing page mapping — which ads route to which funnels, offers, price points
- Vertical coverage beyond Meta — TikTok, Reels Ads, Shopping Ads, DV360, AppLovin
For any of those, you're looking at a dedicated ad intelligence platform. We maintain a full comparison in the best ad spy tools of 2026 — at the API-friendly end, AdMapix, Adspower, and BigSpy all offer programmatic access over commercial ad inventories that the Meta Ad Library API does not touch. If you need commercial-ads programmatic access without the CASD friction, our OpenClaw API covers that.
Either path — free API for political + issue coverage, or paid platform for commercial intelligence — it helps to first be fluent in the UI. Our complete Facebook Ads Library guide and the shorter where is Facebook Ads Library walk through the browser workflow that most API users still fall back to for spot checks. When you're ready to pull the trigger, the AdMapix pricing page has the programmatic-access tiers side by side.
FAQ
Is the Meta Ad Library API free? Yes. The developer tier is free — no usage fee, only the 200 calls per user access token per hour rate-limit ceiling. Ad Library Report CSV downloads are also free and require no API key. Costs appear only for the Meta Content Library researcher tier via CASD (SOMAR VDE is $371 per team per month plus a one-time $1,000 project setup fee as of January 2026) or paid third-party wrappers like ScrapeCreators or Bright Data.
Can I access commercial ads via the API?
No, not through /ads_archive. The developer-tier API is scoped to political/issue ads plus US special categories (housing, employment, credit). Commercial ads are visible in the browser UI but are not returned by the API even with ad_type=ALL. For commercial-ads programmatic access, use the Meta Content Library via CASD (researcher-gated) or third-party services scraping the public Ad Library.
What's the rate limit? 200 calls per user access token per hour, rolling window. Expect to hit the limit earlier with large field projections — Meta throttles on an internal cost estimate, not raw call count. Error code 613 is the rate-limit signal. Back off 60 seconds and retry. For bulk analysis, use the weekly Ad Library Report CSV, which does not consume API quota.
Is scraping the Ad Library legal after Meta v. Bright Data? Scraping publicly accessible, logged-out pages was upheld as permissible by the Northern District of California in Meta v. Bright Data on January 23, 2024. Meta dropped its appeal February 26, 2024, letting the ruling stand. This is persuasive US district-court authority, not a Ninth Circuit precedent, and it does not authorize logged-in scraping, authentication circumvention, or override GDPR/UK-DP obligations. Teams scraping at scale treat it as a green light for US-originated logged-out requests while maintaining jurisdictional review elsewhere.
Can non-US developers access the API? Yes. The API is globally available wherever Meta operates — no country restriction on registration, only on ID verification. Your passport must be recognized by Meta's ID service and your mobile must accept SMS. Mainland China +86 numbers are currently rejected in SMS verification, so Chinese developers typically register under a Hong Kong or Singapore entity with a local SIM. CASD researcher access is de facto EU-only.
How is the API different from Meta Content Library?
The Ad Library API (/ads_archive) is the public developer endpoint: free, self-serve, political/issue plus US special categories, bucketed impressions and spend, no direct creative media URLs. The Meta Content Library is the researcher tier: covers commercial ads, richer creative metadata and campaign hierarchies, requires CASD approval and SOMAR VDE, and restricts data export to aggregated analytical outputs. Ad Library API serves transparency and compliance; Content Library serves academic research.
References and further reading:
- Meta Ad Library API — official documentation
- Meta Ad Library API product page and access request
- Meta Content Library via CASD (researcher access)
- SOMAR VDE pricing and environment documentation
- SerpApi — Meta and Google Ads Library wrappers
- ScrapeCreators — pay-as-you-go Meta Ad Library API
- Meta v. Bright Data — N.D. Cal. January 2024 ruling analysis
- Graph API reference — v20.0 endpoints and versioning
See what competitors are really running
Search 91M+ creative combinations across 170+ market labels. New accounts include 30 lifetime Free credits.
Related Articles

Playable Ad Analysis for Mobile Games: A Practical Method
A practical method for playable ad analysis in mobile games: how to reverse-engineer a competitor's playable by the job it is built to do, decode its structure beat by beat, infer which concepts are likely working, turn observations into testable briefs, and stay honest about what a public playable proves (structure and intent) versus what it never can (spend, installs, retention, ROAS).

Best Mobile Game Ad Formats Across Platforms: A 2026 UA Playbook
A platform-by-platform guide to the best mobile game ad formats in 2026: which formats do the heavy lifting on Meta, Google, TikTok, AppLovin, and Unity; why the right format depends on platform, genre, and funnel stage; a format-selection framework; a creative-testing cadence; and the honest limits of what competitor ads can and cannot tell you about which format wins.

Meta Ads Library vs Ad Intelligence Tools for Game UA (2026): Which to Use, When, and Why
A definitive 2026 comparison of the Meta Ads Library vs dedicated ad intelligence tools for mobile game user acquisition — where the free transparency library genuinely helps, the structural limits that create blind spots for game UA creative research, a side-by-side capability matrix, the exact decision criteria for when to add a paid intelligence layer, and an honest account of what neither can show.