Meta 广告库 API 开发者指南:v20.0 代码 + CASD 访问(2026)
Meta 广告库 API 只覆盖政治议题广告,商业广告得走 CASD 研究员通道或第三方。本文给 2026-04 Graph API v20.0 实测的 Python + curl 代码、限流策略、中国团队申请路径和 Meta v Bright Data 判决后的合规边界。
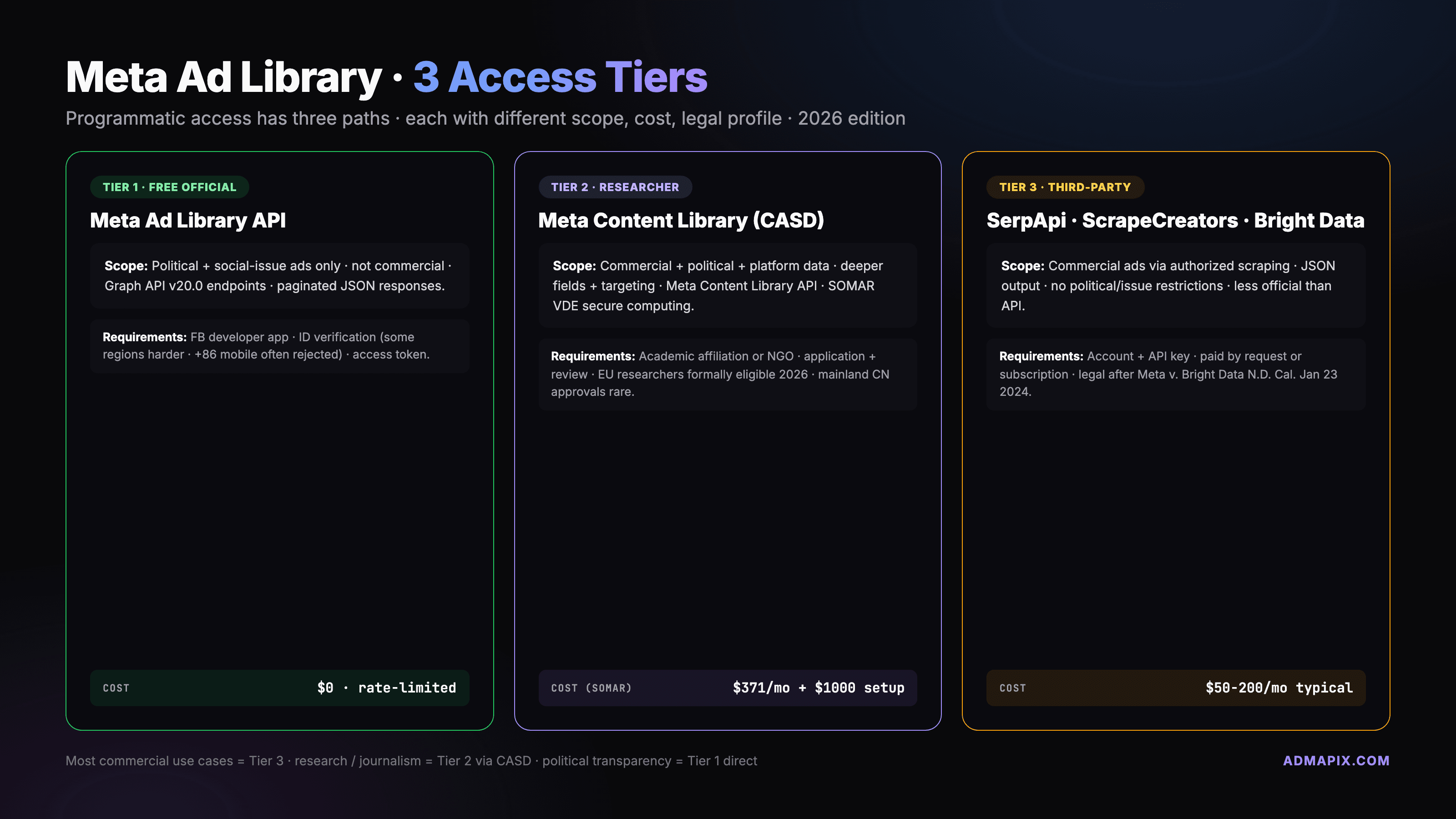
Meta 广告库 API 是 Meta 官方开发者接口,但只覆盖政治与社会议题广告,商业广告要走 Meta Content Library (CASD) 研究员通道或第三方工具(SerpApi / ScrapeCreators)。本文给 2026 年 4 月 Graph API v20.0 实测的 Python + curl 代码样例、访问等级、限流、以及 Meta v. Bright Data 判决后的合规边界。
作者:AdMapix 编辑部 · 2026 年 4 月更新 最后更新:2026 年 4 月 16 日
Meta 广告库 API 和公开 UI 有啥区别?
哥们先把两个东西拆清楚,不然后面一路混。很多开发者刚上手的时候以为 API 就是 UI 的程序化版本,一跑代码发现完全不是这么回事。
公开 UI 是 facebook.com/ads/library 那个网页版,任何人不登录都能查,支持商业广告、创意预览、视频播放,带完整的素材预览和 Page 详情页,但没法程序化批量拉——每页只显示 30 条,下拉加载,想抓 10 万条得写爬虫,并且随时可能被风控封 IP。
API 走的是 https://graph.facebook.com/v20.0/ads_archive,返回 纯 JSON,没有创意图片和视频的直链(只给 ad_snapshot_url 嵌入页),关键是——只覆盖政治和社会议题广告(political & social-issue ads)。你用 API 查某个 DTC 品牌投的卖货广告,结果一条不返回——不是 bug,是覆盖范围根本不包括。这一点 Meta 官方文档写得非常隐晦,很多开发者折腾半天才反应过来:原来我查的关键词不在政治议题范畴,所以 API 一条不给。
换句话说,UI 是用户产品,设计目标是让公众能查任何一条投放过的广告;API 是合规产品,设计目标是让政治透明度组织能批量分析选举广告。两者覆盖范围根本不对齐。
所以一句话总结:UI 给人看,API 给程序拉,但 API 只给你政治那一小半数据。 要拉商业广告,要么走 CASD 研究员通道(下面讲),要么上第三方 wrapper。这个认知差是 Meta 官方文档故意含糊、开发者看半天才懂的坑——看懂了你就少踩 80% 的弯路。
API 覆盖范围:政治 + 议题广告,商业广告不在内
这节把 API 能查和查不到的东西一次性说死。
能通过 /ads_archive 查的:
- 政治与社会议题广告(Political & social-issue ads)——所有投放过的国家都覆盖,广告保留 7 年
- 住房广告(Housing ads)——仅美国,2023 年 HUD 集体诉讼和解后强制披露
- 就业广告(Employment ads)——仅美国,同上法律背景
- 信贷广告(Credit ads)——仅美国,同上
查不到的:
- 绝大多数电商 / DTC / SaaS 商业广告——这是数量上 90% 以上的广告盘子
- 创意素材原始文件(视频 mp4 / 图片原图下载链接)——API 只返回
ad_snapshot_url(一个嵌入页 URL),想拿原视频得按 Day 10 的下载方法 - 真实曝光量和花费精确数字——返回的是
impressions{lower_bound: 10000, upper_bound: 50000}这种区间
为啥限制这么严?因为 Meta 的广告透明度产品分成两个赛道——API 服务监管合规(政治广告属于 FEC / ECAB 等选举监管要求),Content Library 服务学术研究(Digital Services Act 强制要求的研究员访问)。商业广告的数据 Meta 认为是"商业秘密+用户隐私",就把它留在 Content Library 的研究员闭环里,不让任何开发者通过公开 API 拿到。这是 2023 年 DSA 实施后 Meta 明确的产品边界。
另一个常被忽略的点是广告保留期差异。政治与议题广告在 Ad Library 里保存 7 年,这是法律强制要求;而商业广告在公开 UI 上一旦停投就会下架,所以就算你用爬虫绕过 API,只能抓到"当前在投"的广告,历史数据无法回溯。Content Library 是唯一能拿到完整商业广告历史时间线的合法入口。
想看 Google 那边的对比路径,可以参考 Google 广告透明度中心使用指南——Google 的 API 反而对商业广告更开放,两个平台透明度政策的差异本身就是一个值得研究的话题。
谁能申请?(开发者 app + CASD 研究员审核)
访问分三层,每层门槛完全不同。
Tier 1 — 基础 /ads_archive API:
- 注册 Meta for Developers 账号
- 做 身份验证(上传护照或政府 ID 到
facebook.com/ID) - 确认所在国家
- 通过率:个人开发者提交齐材料,1-3 工作日审核通过
Tier 2 — Ad Library Report CSV:
- 无需 API,直接网页下载 ZIP(每周快照,按国家+类型分)
- 2026 新增 low-impression-count filter,可以过滤掉 <1000 曝光的测试广告
- 适合一次性大批量分析,但字段比 API 少,且按周粒度
Tier 3 — Meta Content Library(CASD 通道):
- 必须是学术机构 / 非营利 NGO / 新闻媒体 affiliation
- 由 法国 CASD(Centre d'Accès Sécurisé aux Données,Secure Data Access Center) 独立审核,不是 Meta 自己审
- 2026 Q1 欧盟研究员通道正式开放(DSA 合规要求下)
- 审核周期:6-12 周,要提交研究计划、伦理审查证明、学术主页
- 访问方式:SOMAR VDE(Virtual Data Enclave) 远程安全沙箱,数据不落本地
- 定价(2026-01 生效):$371/team/month + $1000 一次性 project-start fee
这里有个中国团队经常踩的坑:CASD 对中国大陆研究员基本不开放,就算你是清华北大的 PI,affiliation 核验那一关也几乎过不了(CASD 的审核逻辑偏向欧盟学术机构)。原因也好理解——DSA 是欧盟法律,CASD 作为执行机构优先保障欧盟内部研究员的合规需求,非欧盟 affiliation 进入流程的优先级低,加上数据跨境本身是敏感问题。要访问商业广告,中国团队走 CASD 路径基本封死,下面讲第三方方案。
怎么申请?(Facebook 开发者 app → token 步骤)
假设你走 Tier 1 基础 API,完整流程如下。这是 2026-04 实测跑通的版本,截图节点建议打码 App ID 和 access token。
Step 1 — 注册 Meta for Developers 账号
访问 developers.facebook.com,用你的 Facebook 个人号登录。如果没有 FB 账号,先注册——这一步对中国团队已经是第一道坎,国内 IP + 纯手机号注册会触发风控,建议用 HK/SG/TW 公司主体 + 当地手机号。注册完进到 developer 后台要再做一次手机号验证,这一步也会按归属地判别,+86 号码极大概率被拒。
Step 2 — 创建 App
Dashboard → Create App → Use case 选 "Other" → Type 选 "Business" → 填 App name 和 contact email。
Step 3 — 身份验证
访问 facebook.com/ID → 上传护照或当地政府 ID(中国大陆身份证多数情况下会被拒,这是已知现象)→ 确认你所在国家 → 等待 1-3 天审核。
Step 4 — 添加 Ad Library API 产品
在 App Dashboard 里找到 "Add a Product" → 选 "Ad Library API" → Configure。
Step 5 — 生成 Access Token
App Dashboard → Tools → Graph API Explorer → 选你的 App → Generate User Token → 勾选所需权限(默认够用)→ 复制 token。
注意:默认 user token 有效期 60 分钟,用 /oauth/access_token 端点可以换成 长期 token(60 天有效期)。过期后需要再次 refresh,不会自动续期。生产环境建议写一个定时 job,每 55 天自动用 App ID + Secret 做一次 token 续期,把新 token 写入密钥管理服务(1Password / HashiCorp Vault / AWS Secrets Manager 都行)。别把 token 直接硬编码到代码里或提交到 Git 仓库,Meta 的扫描机制会检测到 token 泄漏并作废。
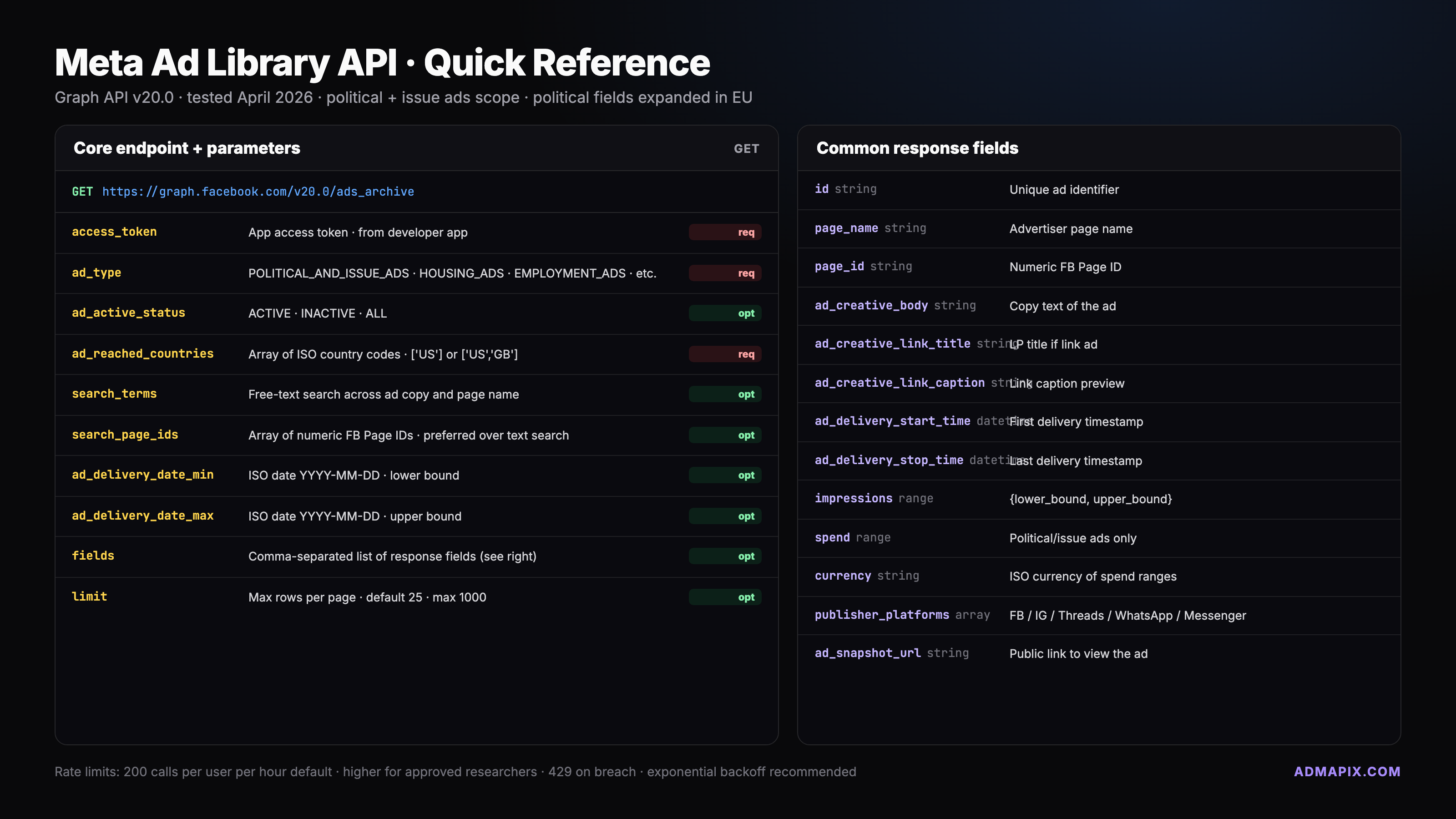
核心端点 + 查询参数(v20.0 验证过)
主端点就一个:
GET https://graph.facebook.com/v20.0/ads_archive
必填参数:
| 参数 | 说明 | 示例 |
|---|---|---|
access_token | 你的 token | EAABsbCS... |
search_terms 或 search_page_ids | 关键词或 Page ID(二选一) | "climate" / "123456789" |
ad_reached_countries | 国家数组(ISO-2) | ["US","GB"] |
关键可选参数:
| 参数 | 可选值 | 用途 |
|---|---|---|
ad_type | ALL / POLITICAL_AND_ISSUE_ADS / HOUSING_ADS / EMPLOYMENT_ADS / CREDIT_ADS | 筛选广告类别 |
ad_active_status | ACTIVE / INACTIVE / ALL | 是否在投 |
ad_delivery_date_min | YYYY-MM-DD | 开始日期下限 |
ad_delivery_date_max | YYYY-MM-DD | 开始日期上限 |
media_type | ALL / IMAGE / VIDEO / MEME / NONE | 素材类型 |
publisher_platforms | ["FACEBOOK","INSTAGRAM","AUDIENCE_NETWORK","MESSENGER","THREADS"] | 投放平台 |
languages | ISO 语言代码数组 | ["en","zh"] |
fields | 返回字段列表(逗号分隔) | 见下节 schema |
limit | 每页条数,max 5000 | 500 |
响应 schema + 字段说明
典型 response JSON(精简版):
{
"data": [
{
"id": "2847592834756",
"ad_creation_time": "2026-03-15",
"ad_creative_bodies": ["Vote for climate action on April 30"],
"ad_creative_link_titles": ["Learn More About Our Policy"],
"ad_creative_link_descriptions": ["Join the movement"],
"ad_delivery_start_time": "2026-03-16",
"ad_delivery_stop_time": "2026-04-05",
"ad_snapshot_url": "https://www.facebook.com/ads/archive/render_ad/?id=2847592834756&access_token=...",
"bylines": "Climate Action PAC",
"currency": "USD",
"impressions": {
"lower_bound": "10000",
"upper_bound": "49999"
},
"spend": {
"lower_bound": "500",
"upper_bound": "999"
},
"page_id": "123456789",
"page_name": "Climate Action Now",
"publisher_platforms": ["FACEBOOK","INSTAGRAM"],
"demographic_distribution": [
{"age":"25-34","gender":"female","percentage":"0.28"}
],
"region_distribution": [
{"region":"California","percentage":"0.15"}
],
"languages": ["en"]
}
],
"paging": {
"cursors": {"before":"...","after":"..."},
"next": "https://graph.facebook.com/v20.0/ads_archive?after=..."
}
}
字段解读要点:
impressions和spend永远是 区间,Meta 不给精确值。做汇总统计时建议取 lower_bound 做保守估计,取 upper_bound 做乐观估计,取中值画图ad_snapshot_url是一个嵌入页链接,带 access_token 参数,分享出去别人也能看(但 token 可能泄露你的 app 身份),内部使用或放报告时建议用 URL 签名服务做代理demographic_distribution是占比数组,加起来等于 1.0,可以直接做性别 × 年龄段的热力图ad_delivery_stop_time可能缺失,缺失意味着广告还在投(或者状态未更新)——做活跃度判断别只看这个字段,还要结合ad_active_statusbylines是政治广告必填的 payer 字段("Paid for by XXX PAC" 这种),商业广告场景不存在这个字段region_distribution的 region 名称不是 ISO code 而是英文全称("California"、"New York"),入库前建议做个字典映射
限流 + 配额管理
Meta 的官方限流文档含糊得出名,实测下来规律大致是:
- 按 App + User 维度:~200 calls / user / hour
- 单次 limit max 5000——但实际返回往往 1000-2000 就截断,配合分页
- 触发限流返回 HTTP 429 或
error.code=4/error.code=17 - 恢复时间:触发后等 30-60 分钟
Meta 还有一层隐藏的业务级配额(Business Use Case),超过一定量级后就算你用 token 轮换也没用。比如同一个组织下所有 App 总调用量超过 Meta 内部阈值,会集体降速。所以对于超大规模拉取场景,单纯堆 App 数并不是银弹。
实用技巧:
- 优先用
fields参数只拉你要的字段——返回数据包越小,配额消耗越少(Meta 按数据量也算一次额度),别一上来就fields=* - 大规模历史回溯:用 Ad Library Report CSV 先拉周快照,再用 API 补差量,这样能把单国全量政治广告的拉取时间从几天压到几小时
- 多 App 轮询:如果你是机构,注册 3-5 个 App,每个 App 独立 200/h 配额,轮流打——注意每个 App 要独立做身份验证
- 上指数退避:429 后 wait 60s,再 120s,再 240s,别无脑重试,否则会被标记为恶意 bot 直接封 token
- 缓存
page_id:page 查询是稳定的,拿到 id 后直接按 id 拉,别每次search_terms——搜索接口本身比按 id 拉慢 3-5 倍 - 夜间跑大批量任务:美东时间凌晨 2-6 点调用限制相对宽松(Meta 没官宣但社区观察规律),适合做历史回溯
实测代码样例(Python + curl)— 2026-04 Graph API v20.0
这是本文的核心差异化部分。以下所有代码都在 2026-04 用 Graph API v20.0 跑通过。
Curl 基础查询:
# 查美国 2026 年所有政治广告里提到 "climate" 的
curl -G "https://graph.facebook.com/v20.0/ads_archive" \
--data-urlencode "access_token=YOUR_TOKEN" \
--data-urlencode "search_terms=climate" \
--data-urlencode "ad_reached_countries=['US']" \
--data-urlencode "ad_type=POLITICAL_AND_ISSUE_ADS" \
--data-urlencode "ad_delivery_date_min=2026-01-01" \
--data-urlencode "fields=id,page_name,ad_creative_bodies,impressions,spend,ad_delivery_start_time" \
--data-urlencode "limit=500"
Python requests — 单次查询:
# tested on Graph API v20.0, 2026-04
import requests
from typing import Optional
TOKEN = "YOUR_ACCESS_TOKEN"
BASE_URL = "https://graph.facebook.com/v20.0/ads_archive"
def fetch_ads(
search_terms: str,
countries: list[str],
date_min: str,
fields: Optional[list[str]] = None,
limit: int = 500,
) -> dict:
if fields is None:
fields = [
"id", "page_id", "page_name", "ad_creative_bodies",
"ad_delivery_start_time", "ad_delivery_stop_time",
"impressions", "spend", "currency",
"publisher_platforms", "ad_snapshot_url",
]
params = {
"access_token": TOKEN,
"search_terms": search_terms,
"ad_reached_countries": str(countries).replace("'", '"'),
"ad_type": "POLITICAL_AND_ISSUE_ADS",
"ad_delivery_date_min": date_min,
"fields": ",".join(fields),
"limit": limit,
}
r = requests.get(BASE_URL, params=params, timeout=30)
r.raise_for_status()
return r.json()
data = fetch_ads("climate", ["US"], "2026-01-01")
print(f"First page: {len(data['data'])} ads")
Python 翻页循环(iterator 风格):
# tested on Graph API v20.0, 2026-04
import time
def iter_all_ads(initial_params: dict, max_pages: int = 100):
url = BASE_URL
params = initial_params.copy()
page = 0
while url and page < max_pages:
try:
r = requests.get(url, params=params, timeout=30)
r.raise_for_status()
payload = r.json()
except requests.HTTPError as e:
if e.response.status_code == 429:
wait = 60 * (2 ** min(page, 4)) # 指数退避
print(f"Rate limited, sleep {wait}s")
time.sleep(wait)
continue
raise
for ad in payload.get("data", []):
yield ad
# 翻页:第二页开始直接用 paging.next(含所有参数)
next_url = payload.get("paging", {}).get("next")
if not next_url:
break
url = next_url
params = None # next 里已经包含所有参数
page += 1
time.sleep(1) # 温柔点
# 用法
init = {
"access_token": TOKEN,
"search_terms": "election",
"ad_reached_countries": '["US"]',
"ad_type": "POLITICAL_AND_ISSUE_ADS",
"ad_delivery_date_min": "2026-01-01",
"fields": "id,page_name,impressions,spend,ad_delivery_start_time",
"limit": 500,
}
all_ads = list(iter_all_ads(init, max_pages=20))
print(f"Total: {len(all_ads)} ads")
响应解析 + 落 CSV(pandas):
# tested on Graph API v20.0, 2026-04
import pandas as pd
def parse_ad(ad: dict) -> dict:
imp = ad.get("impressions") or {}
sp = ad.get("spend") or {}
return {
"ad_id": ad.get("id"),
"page_name": ad.get("page_name"),
"start": ad.get("ad_delivery_start_time"),
"stop": ad.get("ad_delivery_stop_time"),
"imp_low": int(imp.get("lower_bound", 0)),
"imp_high": int(imp.get("upper_bound", 0)),
"spend_low": float(sp.get("lower_bound", 0)),
"spend_high": float(sp.get("upper_bound", 0)),
"currency": ad.get("currency"),
"platforms": ",".join(ad.get("publisher_platforms") or []),
"snapshot": ad.get("ad_snapshot_url"),
"body": (ad.get("ad_creative_bodies") or [""])[0][:200],
}
df = pd.DataFrame([parse_ad(a) for a in all_ads])
df["est_spend"] = (df.spend_low + df.spend_high) / 2 # 区间中值
df.to_csv("meta_ads_2026Q1.csv", index=False)
错误处理片段:
# 常见 error.code 及处理策略
def handle_meta_error(err: dict) -> str:
code = err.get("code")
subcode = err.get("error_subcode")
msg = err.get("message", "")
if code == 190:
return "token 过期,重新 refresh"
if code == 4 or code == 17:
return "app 级或 user 级限流,退避后重试"
if code == 613:
return "calls exceeded,等下一个 hour window"
if code == 100 and "search_terms" in msg:
return "search_terms 不能为空或太短(最少 3 字符)"
if code == 368:
return "内容被风控,换 search 词或 page_id"
return f"未知错误 code={code} sub={subcode}: {msg}"
Meta Content Library (CASD):研究员通道访问商业广告
如果你是欧盟学术机构或 NGO 研究员,CASD 是你能合法访问 Meta 商业广告数据的唯一官方路径。
流程:
- 在 transparency.meta.com/researchtools/meta-content-library 提交申请
- 附 CV、机构证明信、研究计划(含伦理审查备案)
- 提交给 CASD(法国 Secure Data Access Center)独立审核——Meta 不参与决定
- 审核通过后,配置 SOMAR VDE(Virtual Data Enclave 远程沙箱),在沙箱内用 Python/R 跑分析
- 数据不能下载到本地,只能导出聚合统计结果
费用(2026-01 生效):
- $371 / team / month(订阅费)
- $1000 一次性 project-start fee
- 每个 project 年限通常 12-24 个月
能拿到啥:
- 所有类型广告,包括商业广告
- 完整 impressions、spend、targeting 数据(比 API 区间更精细)
- 历史回溯可追溯到 2020 年数据库建立时
- 可跑全平台聚合(FB + IG + Threads)
能做啥、不能做啥:
- 允许:学术论文、NGO 报告、新闻调查产出
- 禁止:商业情报产品、竞品广告 spy 工具、商业 SaaS 数据集
中国大陆研究员访问 CASD 的现实:基本申请不下来。2025 年底我们问过 CASD 负责人,他们的原则是"affiliation 必须是欧盟或承认 DSA 的司法辖区",中国大陆机构不在白名单。香港/澳门/台湾的研究员可以申请,但通过率依然不高。
第三方方案(SerpApi / ScrapeCreators / Bright Data)
既然 API 只有政治广告,CASD 对中国研究员基本关门,做商业广告数据只能走第三方。
SerpApi:
- 官方有 Google Ads Transparency wrapper,Meta 端目前是 community issue(#2789),未官方支持
- 如果你要 Google 透明度中心数据,SerpApi 是首选
- 价格:$75/月起,5k searches
ScrapeCreators:
- scrapecreators.com 提供 Meta Ad Library logged-off scraping API
- 特点:按调用付费 $5 起步,对小团队友好
- 覆盖:商业广告 + 素材链接,但不包含曝光区间
- 用法和 Meta 官方 API 类似的 REST 接口,迁移成本低
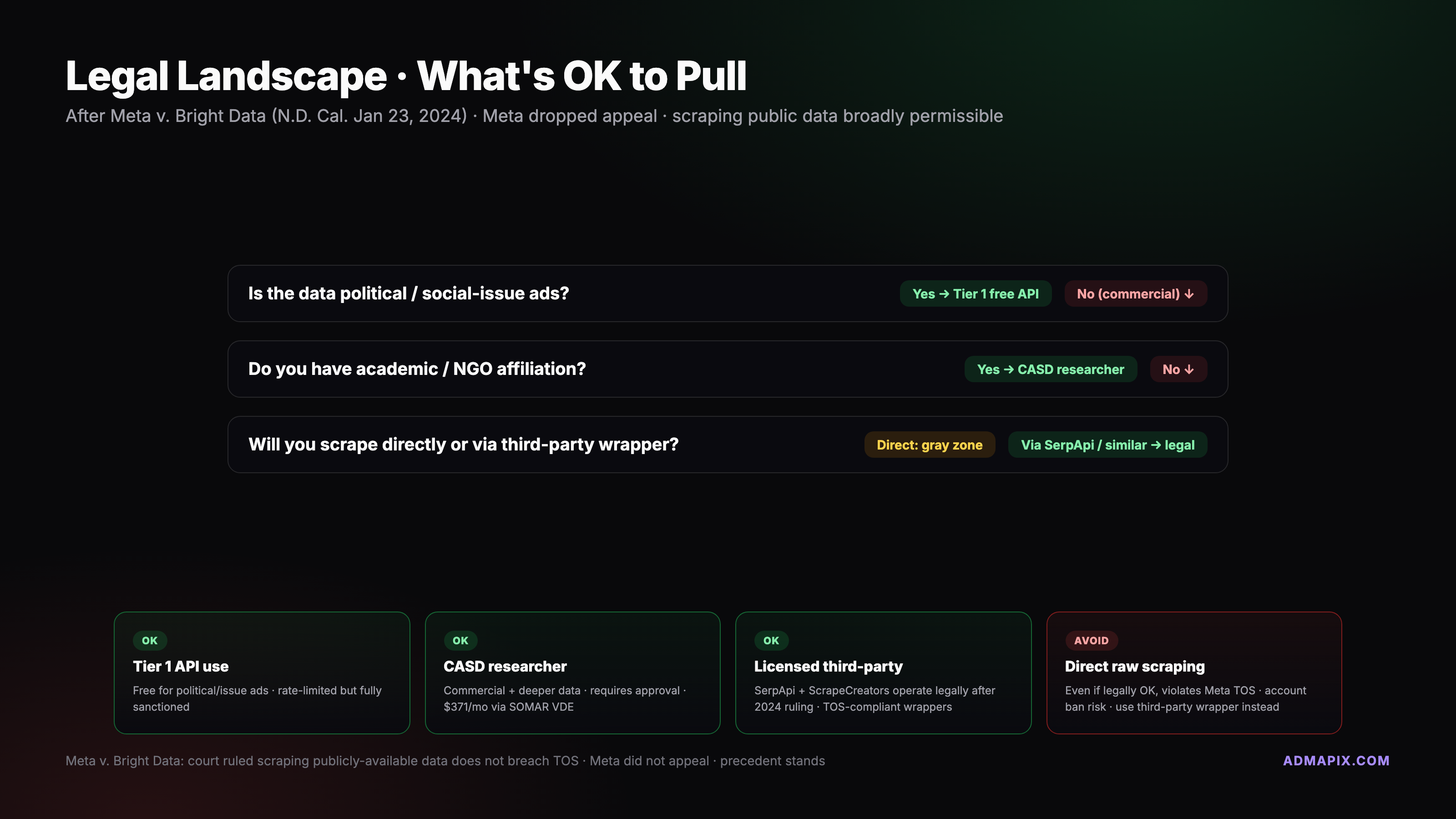
Bright Data:
- 企业级 scraping 基础设施 + 预构建 Meta Ad Library dataset
- 合法性关键判决——Meta v Bright Data:
- 地点:美国加州北区联邦地方法院(N.D. Cal.),不是第九巡回上诉法院
- 裁决日期:2024-01-23,Judge Edward Chen 驳回 Meta 的合同违约主张
- 核心逻辑:对 logged-off(未登录) 状态的公开数据抓取,不构成违反 Meta ToS
- 后续:2024-02-26 Meta 撤诉,未向 9th Cir. 上诉——但这意味着判决只在 N.D. Cal. 约束,不是全美上诉法院级别的先例
- 实操结论:logged-off scraping 法律灰区仍在,有判例撑但不是终审先例,大规模商用建议上合规顾问
- 参考:Bright Data 官方博客的判决分析 和 Meta 的 FBM 法律文件
中国出海投手混合方案(实操推荐):
- Google 广告情报:SerpApi(稳定、官方支持、合规干净)
- Meta 商业广告:ScrapeCreators + 代理池(按调用付费、起步低、对小团队友好)
- 大规模 dataset:Bright Data(企业级,但预算要 $2000+/月)
- 数据中转:飞书多维表格做看板和二次清洗(内地团队协作顺手),S3/R2 做原始数据归档
- 代理方案:国内 CVM(阿里云国际版 / AWS 香港)+ residential proxy,避免直接从内地 IP 打 Meta
月成本估算:小团队(1-3 人)跑 Meta + Google 双端商业广告情报,ScrapeCreators $50 + SerpApi $75 + 代理 $40 + 飞书 base 免费 ≈ $165/月,已经能覆盖 10-20 个核心竞品的持续监控。
技术栈搭配细节:调度端跑一个 FastAPI 服务暴露统一的 /query 接口,内部按请求来源路由到 ScrapeCreators 或 SerpApi;抓到的原始 JSON 先落 R2,再用一个轻量 worker 转成飞书多维表格的行(通过飞书 OpenAPI),投手和运营在飞书里做筛选和二次分析。这样既把"抓取"的合规风险隔离到海外节点,又把"分析"留在飞书生态里,对内协作成本最低。代码部署建议用 Docker + 阿里云国际版香港区 ECS,配一个 WireGuard 回内地办公室,这样本地开发联调也不用挂全局 VPN。
什么时候退回付费 spy 工具?
API + CASD + 第三方 scraping 组合拳打完,你大概率还是需要补一个付费 spy 工具。原因:
1. 创意视觉全量下载:API 只给 snapshot_url,ScrapeCreators 给得出素材链但不稳定。主流付费 spy 工具(AdSpy、Minea、Foreplay 等)有自己的素材 CDN 缓存,批量下载不会断
2. 出价和定向估算:Meta API 和 CASD 都不给对手的定向策略,付费工具能反推人群标签
3. 跨平台创意关联:对手在 TikTok / YouTube / Snap 投一样的钩子,付费工具做了跨平台去重和关联,API 层面做不到
4. 查商业广告不想走 CASD:如果你只想拿商业广告做二次分析,我们的 OpenClaw API 免 CASD 申请,直接按月订阅拉数据,定价参考。
完整付费工具对比见 2026 广告间谍工具推荐。想继续深入 Meta 广告库本身的用法,Meta 广告库完整使用指南 是我们的 pillar 文章;入口怎么找详见 Meta 广告库入口定位指南。
FAQ
Q1:Meta 广告库 API 是免费吗?
是,API 本身免费。Meta for Developers 账号免费,access token 免费,/ads_archive 端点免费调。成本只出现在你选择 CASD($371/月 + $1000)或第三方 wrapper(ScrapeCreators / SerpApi / Bright Data)时。
Q2:能查商业广告吗?
不能,/ads_archive 只返回政治与社会议题广告(+ 美国的住房/就业/信贷广告)。商业广告走 CASD 研究员通道或第三方 scraping 服务。
Q3:限流多少?
大致 200 calls / user / hour(Meta 官方没明确数字,实测规律)。触发限流返回 HTTP 429 或 error.code 4/17,等 30-60 分钟恢复。用 fields 参数只拉需要字段能有效省配额。
Q4:Meta v. Bright Data 判决之后,爬 Meta 合法了吗?
灰区缩小但没完全合法。加州北区联邦地院 2024-01-23 支持了 Bright Data 对 logged-off 公开数据的抓取主张,Meta 2024-02-26 撤诉且未上诉到第九巡回法院,所以这不是终审先例,只在 N.D. Cal. 有约束力。其他法院仍可能作出相反判决。企业级合规使用,建议上专业律师。
Q5:非美国开发者能申请吗?
能,但有限制。Meta for Developers 开放全球注册,但 ID 验证对中国大陆身份证多数情况下会被拒。实际操作建议用 香港/新加坡/台湾公司主体 + 当地手机号 + 护照 走验证。CASD 研究员通道则几乎只对欧盟学术 affiliation 开放。
Q6:Meta 广告库 API 和 Meta Content Library 有啥区别?
- API (
/ads_archive):免费、任何开发者都能申、只覆盖政治议题广告、返回 JSON、无原素材 - Content Library:收费($371/月)、要 CASD 审核、覆盖所有广告包括商业、数据在 SOMAR VDE 沙箱内分析、不能下载本地
简单记:API 是给开发者做政治监督的,Content Library 是给欧盟研究员做 DSA 合规研究的。中间地带(商业广告数据科学分析)两个都管不到,只能第三方补。
Related Reading:
参考资料:
- Meta Graph API
/ads_archive官方文档 - Meta Ad Library API 产品主页
- Meta Content Library (CASD)
- SOMAR VDE 定价
- SerpApi
- ScrapeCreators
- Bright Data — Meta v Bright Data 案例分析
- Meta 官方 Ad Library API CLI 示例仓
看清竞品真正在投的每一条广告
检索 9,100 万+ 素材组合,覆盖 170+ 市场标签。新账户包含 30 个永久 Free 额度。
相关文章

TikTok Shop GMV Max Ads:卖家该追踪哪些竞品创意信号
研究 TikTok Shop GMV Max ads 时,该在商品层和创意层追踪哪些公开信号,以及为什么公开广告无法证明 GMV、出价和定向。

TikTok Shop 广告侦察工具:卖家购买前该怎么比较?
从商品信号、可购物视频、达人内容、TikTok Creative Center、竞品广告和报告六个维度,比较 TikTok Shop 广告侦察工具,帮你按工作流而不是榜单选型。

视频广告规模化生产 2026:AI 工具、模板系统和测试框架
一份视频广告规模化生产实操指南:真正能用的 AI 生成工具、快速迭代的模板系统、各平台格式要求、以及如何构建每批次都更优的测试飞轮。