Competitive Advertising Intelligence: What It Is, How It Works, and How to Turn Signals Into Decisions
A definitional, framework-first guide to competitive advertising intelligence: what the discipline is, where its evidence comes from, how to grade that evidence by reliability, the end-to-end workflow that turns scattered signals into decisions, and an honest line between what public ad data can prove and what it can never reveal.

Competitive Advertising Intelligence: What It Is, How It Works, and How to Turn Signals Into Decisions
Updated June 21, 2026 — written and reviewed by the AdMapix Research team.
Competitive advertising intelligence is the discipline of systematically collecting, verifying, and interpreting publicly observable signals from competitors' advertising — the creatives they run, the offers they push, the channels they buy, the angles they repeat — and converting those signals into decisions about your own marketing. It is not a single tool, a one-off competitor audit, or a folder of screenshots. It is a repeatable practice with defined sources, defined standards of evidence, and a defined path from raw observation to action.
This article is the definitional and framework piece. If you want a buyer's comparison of platforms, read our best ad intelligence tools roundup. If you want the broader strategic primer, read the advertising intelligence guide. If you want the step-by-step competitor teardown method, read the competitor ad analysis framework. Here, the job is narrower and more foundational: to explain what the discipline is, what counts as evidence inside it, how reliable each kind of evidence actually is, and how a working team turns a stream of signals into a short list of decisions every week.
TL;DR
- Competitive advertising intelligence is a discipline, not a dashboard. It is the practice of turning publicly observable competitor advertising into verified signals and then into decisions about budget, creative, offers, channels, and positioning.
- Every claim sits in an evidence tier. Some things are directly observable (a creative is running, an offer is stated), some are inferable with caveats (an angle is being scaled), and some are pure speculation (exact spend, ROAS, audience). Treating these as equal is the most common and most damaging mistake.
- Public ad data has a hard ceiling. You can see what competitors say and show. You cannot see their spend, conversion rates, ROAS, lifetime value, or audience targeting from ad libraries. Honest intelligence states this ceiling out loud.
- The workflow is the product. Scope → collect → verify → grade → interpret → decide → archive. Without the workflow, you have trivia. With it, you have a forecasting habit that compounds.
- AdMapix fits one layer of this stack: searchable, cross-network ad-creative evidence with saved examples, video breakdowns, and recurring reports. It does not — and cannot — show competitor spend, ROAS, or targeting. It is a complement to your analytics and to platform ad libraries, not a replacement for either.
What Competitive Advertising Intelligence Actually Is
Start with what it is not, because the confusion there is where most programs go wrong.
It is not your account analytics. Your analytics — Google Analytics, your ad platform reporting, your CRM — answer the question "what happened inside my own funnel?" They are precise, attributable, and yours. Competitive advertising intelligence answers a different question: "what is changing in the market around me?" It is market-facing where analytics is account-facing, and the two are not interchangeable. A program that confuses them either tries to read competitor performance off public data (impossible) or tries to read market shifts off its own conversion reports (blind to everything outside the account).
It is not a one-time competitor audit. An audit is a snapshot — useful for a pitch deck or a quarterly review, but stale within weeks because creative cycles move fast. Intelligence is a standing capability: a cadence, a method, and an archive that lets you say not just "here is what competitor X is doing today" but "here is what changed since last week, here is whether it is recurring, and here is what it implies for our next test."
It is not spying. The word "ad spy" is industry slang, but the practice is the opposite of secret surveillance. Everything legitimate competitive advertising intelligence touches is public by design: ads are, definitionally, broadcast to an audience, and most major platforms now run transparency libraries precisely so the public can inspect them. There is no privileged access, no leaked data, no insider feed. The skill is not in obtaining the data; it is in collecting it systematically, verifying it, and interpreting it without overreaching.
So what is it? Competitive advertising intelligence is the disciplined conversion of public advertising signals into decisions. It has three irreducible parts:
- Sources — the public surfaces where competitor advertising is observable.
- Evidence standards — a way of grading how reliable each observation is, so you do not act on speculation as if it were fact.
- A workflow — the repeatable path from raw signal to scored change to decision, run on a cadence so that signals are comparable over time.
The rest of this guide takes those three parts in order. Get all three right and you have a forecasting habit. Get any one wrong — collect without grading, grade without deciding, decide without a cadence — and you have an expensive way to produce trivia.
One more framing, because it changes how you value the whole exercise: competitive advertising intelligence is fundamentally a hypothesis engine, not an answer engine. It does not tell you what to do; it tells you, faster and more cheaply than your own experimentation could, which hypotheses are worth testing. When a competitor invests real money to put an angle in front of an audience, they have effectively run a generative step you can observe for free — and while you cannot see whether it worked for them, you can borrow the idea and test it properly against your own audience and your own data. Seen this way, the discipline's output is never "the answer is X." It is always "here are the three best-supported hypotheses about how the market is shifting, ranked by how much the evidence backs them, each ready to become a test." Teams that expect answers are perpetually frustrated that public data will not give them certainty. Teams that expect hypotheses are delighted that it gives them a steady, cheap supply of well-sourced things to try. That reframing alone — from "tell me what they are doing" to "tell me what I should test next" — is what separates a program that compounds from one that merely accumulates screenshots.

The Source Map: Where the Evidence Comes From
You cannot do intelligence without knowing where the raw material lives. Competitive advertising signals come from a layered set of public surfaces, each with a different shape, a different freshness, and a different blind spot. Treat them as a stack, not a single feed.
Platform ad transparency libraries. The foundation. Major ad platforms now run public archives that show currently running (and sometimes historical) creatives, the advertiser of record, and limited context such as when an ad started running or which regions it ran in. These are authoritative for existence — if an ad is in the library, it ran — but they are deliberately sparse on outcomes. They will tell you a competitor is running a creative; they will not tell you how that creative performed. Different platforms expose different fields, and political/issue advertising is usually documented far more richly than commercial advertising, so do not assume the depth you see in one vertical exists in another.
Cross-network creative-intelligence layers. Ad libraries are siloed: each platform shows only its own ads, with its own search and filtering quirks. A creative-intelligence layer sits on top of multiple networks and makes the creatives searchable and comparable — by keyword, advertiser, format, network, or recency — and lets you tag, save, and revisit examples. This is the layer that turns "I saw an interesting ad somewhere" into "show me every video ad in this category that opens with a price-anchoring hook." AdMapix lives here. It is worth being precise about what this layer adds: it adds findability and structure across networks, not new private data. It cannot manufacture spend or performance figures that the underlying libraries do not contain.
Landing pages and offer surfaces. The ad is the promise; the landing page is the proof of what the promise leads to. Landing pages, pricing pages, checkout flows, and lead-capture forms are all public, and they reveal the offer architecture behind a creative: the discount, the trial length, the guarantee, the urgency mechanic, the order-bump. A creative tells you the angle; the landing page tells you the economics the competitor is willing to expose. Snapshotting these over time is one of the highest-signal, lowest-cost moves in the whole discipline.
Organic and owned surfaces. Social profiles, email/SMS programs you can subscribe to, app-store listings, review patterns, and press or careers pages all leak strategic signal. A competitor hiring three performance marketers and a creative producer is a louder signal about future ad volume than any single creative. These surfaces are noisier than ad libraries, but they are where you catch intent before it shows up as spend.
Marketplace and ranking surfaces. In app, e-commerce, and marketplace contexts, public rankings, category charts, and "best seller" badges are advertising-adjacent signals: they reflect the outcome of demand generation even when you cannot see the spend that drove it. A sustained climb up a category chart paired with a burst of new creatives is a much stronger signal than either alone.
The point of mapping sources is not to monitor all of them all the time — that way lies a full-time job and a noise problem. The point is to know which surface answers which question, so that when you need to verify a signal you reach for the surface with the right shape of evidence.
A useful way to internalize the stack is to ask, for any signal you care about, "what is the shortest path to the most authoritative surface?" If the question is "does this creative actually exist and run?", the shortest path is the platform's own transparency library, and nothing else is more authoritative — a creative-intelligence layer that says an ad exists is ultimately reflecting what the library reports. If the question is "what does this category's creative look like right now, across networks?", the shortest path is a cross-network layer, because querying five libraries by hand is exactly the manual cost that layer exists to remove. If the question is "what is the real offer behind this promise?", the shortest path is the landing page, because the ad is a teaser and the page is the contract. And if the question is "is this competitor about to escalate?", the shortest path is owned and hiring surfaces, because intent precedes spend. Matching question to surface is the difference between an efficient program and one that drowns in tabs.
It is also worth naming the freshness problem explicitly, because it bites teams that trust libraries too literally. An ad appearing in a library does not always mean it is currently serving — some libraries retain entries past the point where the advertiser has paused them, and some lag reality by hours or days. Conversely, a brand-new creative may not appear instantly. This is why verification (covered later in the workflow) is a distinct stage and not an afterthought: the library tells you what it knows, but "the library says so" is a Tier 1 fact about the library, not always a Tier 1 fact about the live market. Good operators treat a single library entry as a strong prior and confirm currency before betting a decision on it.

Evidence Tiers: Not All Signals Are Equal
This is the section most teams skip, and skipping it is why so many competitive intelligence programs quietly produce nonsense. The single most important habit in the discipline is to attach a confidence tier to every claim, and never to let a lower-tier claim masquerade as a higher one.
Public advertising data supports three fundamentally different kinds of statements, and they are not interchangeable.
Tier 1 — Directly observable (high confidence). These are claims you can point at. "Competitor X has a video creative running on this network as of today." "Their landing page offers a 14-day trial." "This headline appears across five of their current creatives." "They launched a new ad set in the last 30 days." Tier 1 facts come straight off a public surface with no inference required. They are the bedrock. A strong intelligence note is built almost entirely from Tier 1 facts, with everything else clearly labeled as interpretation.
Tier 2 — Inferable with caveats (medium confidence). These are reasonable readings of Tier 1 facts, but they involve a judgment call. "They appear to be scaling this angle" (inferred from a creative appearing across many variants and regions, but you cannot see impressions). "This looks like their primary offer right now" (inferred from prominence and repetition, but you cannot see what converts). "They are shifting budget toward video" (inferred from a change in creative mix, but the mix in a library is not the same as the spend mix). Tier 2 claims are useful and often the most decision-relevant — but they must always carry the caveat. The honest phrasing is "the public signal is consistent with X," never "they are doing X."
Tier 3 — Speculative (low confidence, often unknowable). These are the claims people want but public data cannot support. "They are spending $X per month." "Their ROAS is Y." "They are targeting these specific audiences." "This creative is their best performer." None of these is visible in any ad library. Where you see precise spend or performance numbers attributed to a competitor, they are almost always modeled estimates with wide error bars, not measurements — and you should treat them as hypotheses to test, not facts to act on. Acting on Tier 3 claims as if they were Tier 1 is the fastest way to burn budget chasing a competitor's imagined strategy.
The discipline is the labeling. A note that says "Competitor X is spending heavily on a discount angle and crushing it" is three unlabeled claims of three different tiers stacked into a sentence that sounds authoritative and is mostly guesswork. The same observation, properly tiered, reads: "Competitor X has a discount-led creative running across multiple variants [Tier 1]; the spread of variants suggests they are actively scaling it [Tier 2]; we cannot see whether it is profitable for them [Tier 3 — unknowable]." The second version is less exciting and far more useful, because it tells you exactly how much weight the signal can bear.
There is a practical reason this matters beyond intellectual honesty: tiers determine how much you are allowed to spend reacting to a signal. A Tier 1 fact — a competitor has clearly launched a new offer — can justify a real budget allocation, because you are reacting to something you can verify. A Tier 2 inference — they appear to be scaling that offer — justifies a hypothesis-sized bet: a small, controlled test, not a roadmap pivot. A Tier 3 guess — they are spending six figures and winning — justifies nothing on its own; at most it becomes one input into a test you would design anyway. When a team skips tiering, every claim implicitly gets treated as Tier 1, which means Tier 3 guesses end up sizing real budgets. That is the precise mechanism by which sloppy intelligence becomes expensive: not because the observations are wrong, but because the confidence attached to them is wildly miscalibrated.
A second reason tiers matter is that they protect you from a competitor's deliberate misdirection. Advertising is public, and sophisticated competitors know they are being watched. A brand can flood a library with creatives in an angle they have no intention of scaling, simply to provoke rivals into chasing it. If you treat creative presence as Tier 1 (true — the creatives exist) but creative intent as Tier 1 as well (false — intent is Tier 2 at best), you can be steered. Keeping intent at Tier 2, and demanding corroboration from a second surface before you act, is what makes your program robust to being gamed. You are not just grading evidence for accuracy; you are grading it for how easily it could be a head-fake.
Finally, tiering creates an honest paper trail. When you archive a decision, you archive the tier behind it. A quarter later you can audit yourself: did the Tier 2 inferences you acted on tend to be right? Did the Tier 1 facts you ignored turn out to matter? This is how a program improves — not by collecting more, but by calibrating better, and you can only calibrate what you labeled.

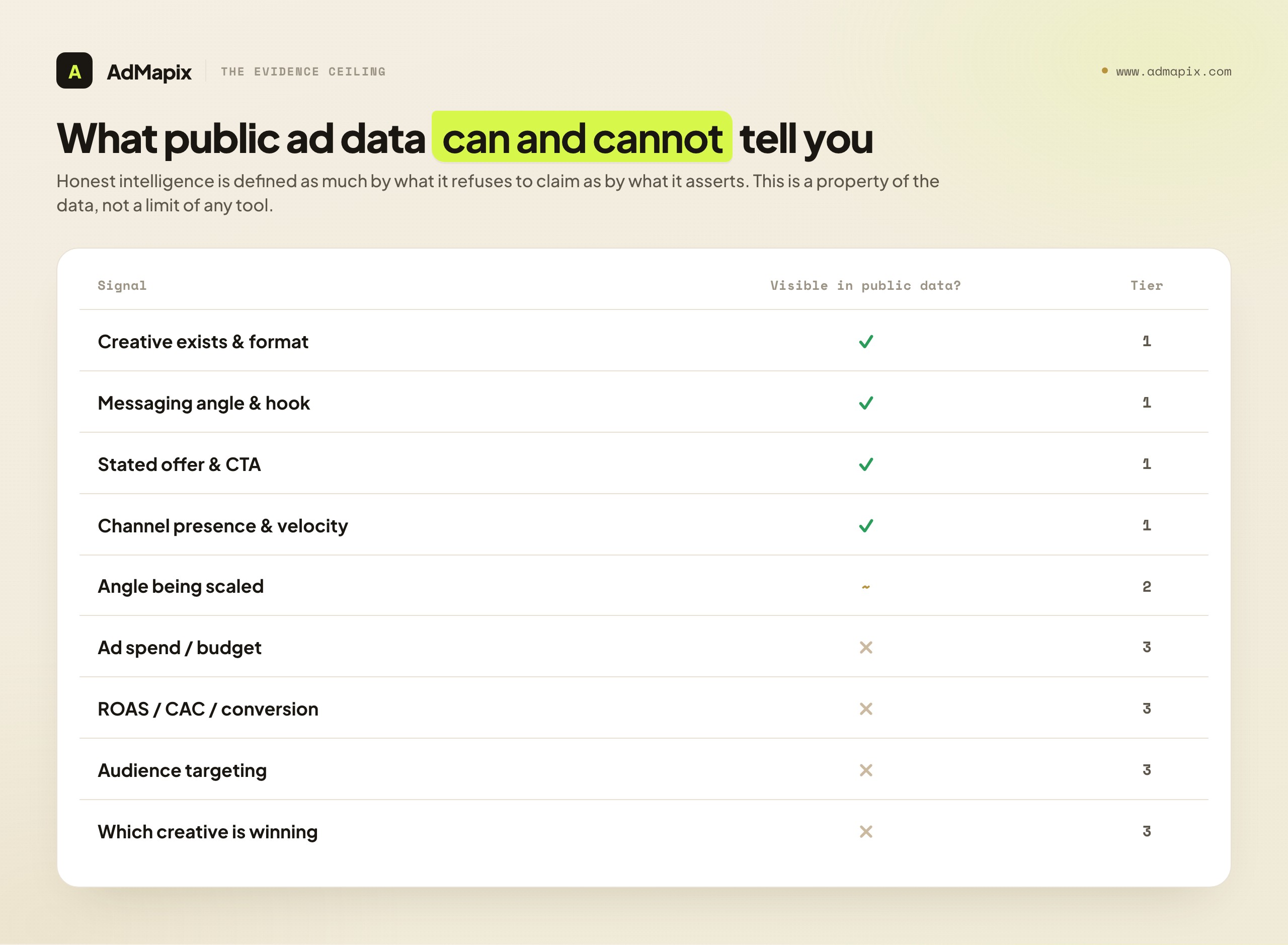
What Public Ad Data Can and Cannot Tell You
Because the evidence ceiling is the single most misunderstood part of this discipline, it deserves its own explicit treatment. Honest competitive advertising intelligence is defined as much by what it refuses to claim as by what it asserts.
What you can see (with public data). You can see what is being said and shown. The existence of a creative. Its format — static, video, carousel, UGC-style, demo. Its messaging angle and hook. The headline and primary copy. The call to action. The offer stated in the ad and on the landing page. The advertiser of record. Rough timing — when an ad appears to have started, and whether it is still running. Recurrence — whether an angle shows up once or across dozens of variants. Channel presence — which networks a brand appears to be active on. Creative velocity — how fast new creatives appear. These are all observable, and together they paint a genuinely rich picture of a competitor's creative and offer strategy.
What you cannot see (full stop). You cannot see spend. Ad libraries do not publish how much a commercial advertiser is paying. You cannot see ROAS, CAC, conversion rate, or any performance metric — those live inside the competitor's own analytics, which is private. You cannot see audience targeting: the demographics, interests, lookalikes, or custom audiences behind a campaign are not exposed. You cannot see lifetime value, margin, or unit economics. You cannot see which of their creatives is actually winning — only which ones exist and recur. And you cannot reliably infer outcomes from inputs: a creative running for a long time might mean it is profitable, or it might mean nobody turned it off.
This is not a limitation of any particular tool. It is a property of the data itself. No ad-intelligence product — AdMapix included — can show you a competitor's spend, ROAS, or targeting, because that data is not public and cannot be. Any vendor implying otherwise is either selling modeled estimates dressed up as facts, or overstating what their data means. The mature posture is to treat the visible layer (messaging, creative, offers, channels, velocity) as a leading indicator of strategy and your own controlled tests as the only reliable measure of performance.
Internalizing this ceiling changes how you use the discipline. You stop asking "how much are they spending?" (unknowable) and start asking "what angle are they betting on, how committed do they look, and what does that imply for the test I should run next?" The second question is answerable from public data, and it is the one that actually moves your roadmap.
The Workflow: Turning Signals Into Decisions
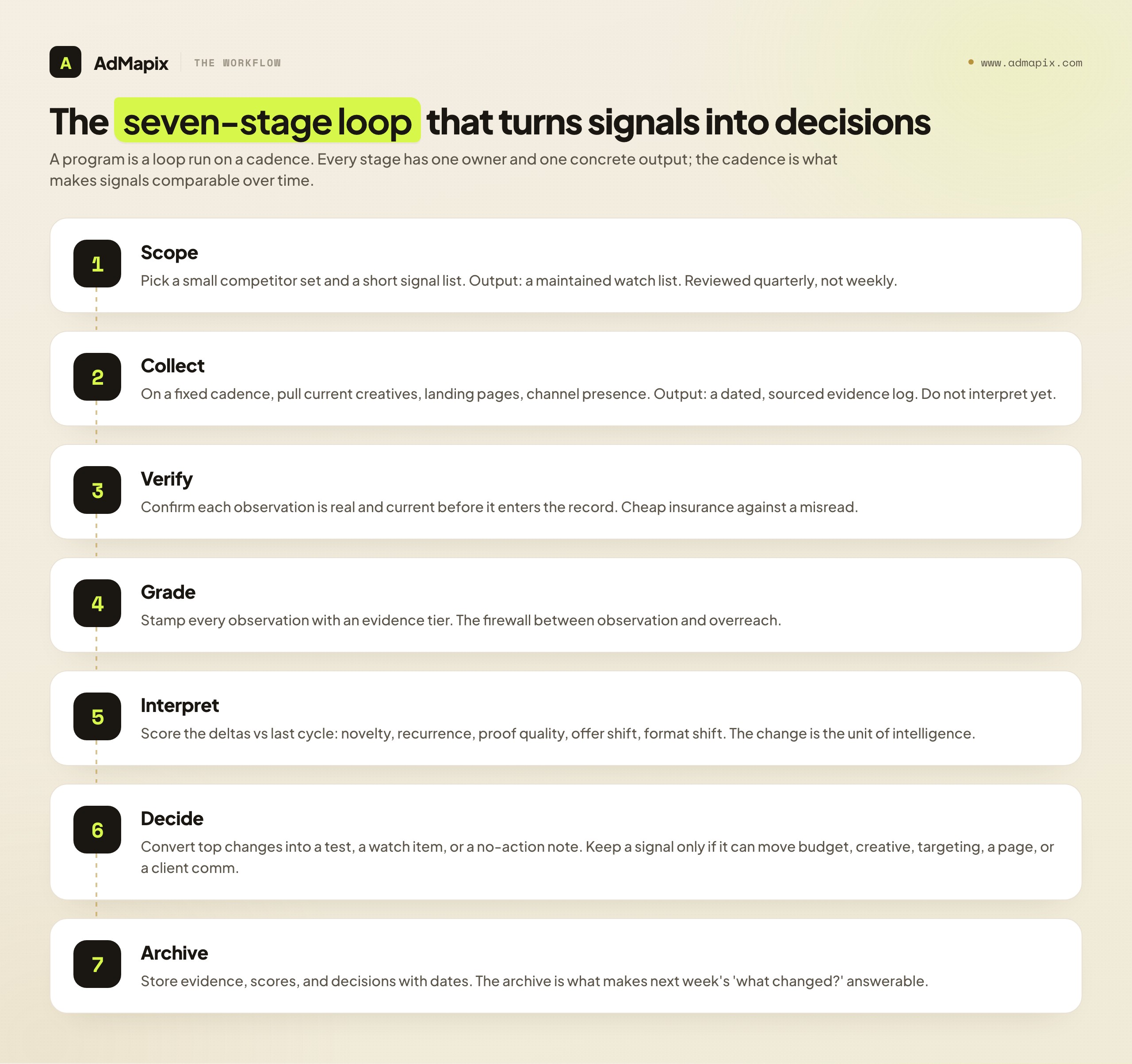
Sources and evidence tiers are the raw materials and the quality control. The workflow is what turns them into output. A competitive advertising intelligence program is, at its core, a loop that runs on a cadence. The loop has seven stages, and every stage has one owner and one concrete output. The cadence is what makes the signals comparable: a change only means something relative to a baseline, and you only have a baseline if you run the same loop on the same rhythm.
Stage 1 — Scope. Decide who and what you are watching. Pick a small competitor set: a handful of direct rivals, one aspirational brand a tier above you, and one adjacent-category player who might encroach. Then decide which signals matter — angles, offers, formats, channels, landing pages — and write them down. A watch list of forty competitors and twenty signals is a watch list nobody maintains. Scope is reviewed quarterly, not weekly; the whole point is stability.
Stage 2 — Collect. On a fixed cadence, pull the current state of each watched surface: recent creatives, current landing pages, any new channel presence. This is mechanical, and it should be. The output is an evidence log — dated, sourced, and raw. Do not interpret yet. The temptation to jump straight to "ooh, they changed their offer" is exactly what corrupts the record; collection and interpretation are separate stages for a reason.
Stage 3 — Verify. Confirm each observation is real and current before it enters the record. Is the creative actually live, or a stale library entry? Is the landing page the production page, or a test variant you stumbled into? Is the "new" angle actually new, or did you simply miss it last week? Verification is cheap insurance against building a week's decisions on a misread.
Stage 4 — Grade. Assign every observation an evidence tier (the previous section). This is where "they're scaling video" gets stamped Tier 2 and "they spend $50k/month" gets stamped Tier 3 and quietly dropped. Grading is the firewall between observation and overreach.
Stage 5 — Interpret (score what changed). Now compare against last cycle's baseline and score the deltas. The change is the unit of intelligence, not the static snapshot. Useful scoring dimensions: novelty (have we seen this angle before?), recurrence (one creative or many variants?), proof quality (does the landing page back the claim?), offer shift (did the deal change?), and format shift (did the creative mix move?). A high-novelty, high-recurrence change with a matching landing-page shift is a loud signal. A single new creative with no other movement is noise until it recurs.
Stage 6 — Decide. Convert the top-scoring changes into exactly one of three outcomes: a test (we will run a creative or offer experiment in response), a watch item (interesting but not yet actionable — flag and revisit), or a no-action note (we considered it and consciously chose not to react). The single decision criterion is brutal and clarifying: keep a signal only if it can change budget, creative, targeting, a landing page, or a client communication. If a signal cannot alter one of those, it does not belong in the decision note, no matter how interesting it is.
Stage 7 — Archive. Store the evidence, the scores, and the decisions with dates. The archive is what makes next week's "what changed?" answerable and what lets you, a quarter later, check whether your interpretations were right. Intelligence that is not archived is intelligence that resets to zero every week.
The loop is deliberately boring. Its power is in the repetition: run it for a quarter and you stop reacting to individual ads and start seeing trajectories — who is escalating, who is retreating, which angles are spreading across a category, which offers are converging. That trajectory view is something no single screenshot, and no Tier 3 spend estimate, can give you.
Scoring a Change: A Worked Example
Frameworks are easy to nod at and hard to apply, so here is the scoring stage made concrete. Suppose your weekly collection turns up the following on a direct competitor:
- A new video creative, UGC-style, opening with a price-anchoring hook ("Most people pay $X — here's how to pay a third of that").
- The same hook appears across four creative variants with different talent.
- Their pricing page now leads with an annual plan that was previously buried below the monthly plan.
- A 7-day trial that was on the page last month is gone.
Walk it through the tiers and the scoring dimensions. The existence of the creatives and the content of the pricing page are Tier 1 — directly observable, high confidence. The reading that they are "scaling" the price-anchoring angle is Tier 2 — four variants with different talent is consistent with deliberate testing or a push, but you cannot see impressions, so it carries a caveat. Any claim about how well it converts is Tier 3 — unknowable, set aside.
Now score the deltas. Novelty: medium — price-anchoring is a known angle, but it is new for this competitor. Recurrence: high — four variants is not a one-off. Proof quality: high — the messaging change is mirrored by a real landing-page change (annual plan promoted, trial removed), so the creative and the offer are telling the same story, which is the strongest possible corroboration short of seeing their numbers. Offer shift: high and specific — promoting annual while removing the trial is a coherent move toward higher upfront commitment and, plausibly, better cash flow or churn. Format shift: notable — a move into UGC-style video if their prior creatives were static.
The interpretation writes itself, properly tiered: "Competitor is running a coordinated price-anchoring + annual-commitment play [creatives Tier 1, landing page Tier 1, 'coordinated' is a well-supported Tier 2 read]. The trial removal suggests they are optimizing for upfront commitment over top-of-funnel volume [Tier 2]. We cannot confirm it is working for them [Tier 3]."
And the decision, against the one criterion: this can change our creative and our offer, so it earns a test. The brief: test a price-anchoring hook of our own against our current control, and separately test promoting our annual plan more prominently. Note in the archive that the trial-removal is a watch item — if a second competitor mirrors it, the category may be shifting and our own trial becomes a strategic question rather than a tactical one.
That is the whole discipline in one example: observe at Tier 1, infer carefully at Tier 2, refuse Tier 3, score the change, and emit a brief that can actually move something.
Notice what the example deliberately does not do. It does not estimate the competitor's spend, even though that is the number a stakeholder will instinctively ask for. It does not declare the price-anchoring angle a winner, because winning is invisible from outside. It does not pivot the whole roadmap on one observation; it converts the signal into a test, which is the correctly-sized response to a Tier 2 inference. And it preserves the trial-removal as a watch item rather than forcing it into action prematurely — because a single competitor removing a trial is a data point, while two competitors removing trials in the same quarter is a category signal worth a strategic conversation. The restraint is the craft. Anyone can look at four creatives and a pricing page and spin a confident story; the discipline is in telling the part of the story the evidence actually supports and explicitly parking the rest.
It is also worth seeing how the archive compounds this. Logged with its date, tiers, and decision, this observation becomes a reference point. If, three weeks later, the price-anchoring creatives are gone and the trial is back, that withdrawal — readable only against the archived baseline — tells you the angle probably did not work for them, which is itself useful intelligence and a reason not to over-invest in your own version. Without the archive, the same withdrawal is invisible; you simply would not notice that something you saw three weeks ago had vanished. The single observation is worth a little; the observation in a dated series is worth a great deal more.

Building the Capability: Roles, Cadence, and Tooling
A discipline needs a home. Competitive advertising intelligence fails most often not because the method is wrong but because nobody owns it, so it decays into an occasional panic before a board meeting. Three things keep it alive.
Ownership. One person owns the loop. Not a committee, not "the growth team in general" — a named owner who runs collection on the cadence, maintains the archive, and produces the weekly decision note. In a small team this is a fraction of one person's role; in an agency it might be a productized service line. The size matters less than the singularity: diffuse ownership is no ownership.
Cadence. Weekly is the default heartbeat for collection, scoring, and decisions, because creative cycles move on roughly that timescale and a slower cadence misses fast tests. Scope (the competitor set and signal list) is reviewed quarterly, because changing what you watch every week destroys comparability. The mismatch is intentional: fast loop, slow frame.
Tooling, honestly scoped. Tooling should reduce the mechanical cost of the loop, not promise to replace the judgment in it. You need, at minimum: a way to find and save creatives across networks (a creative-intelligence layer), a way to snapshot landing pages over time, a place to keep the evidence log and archive, and your own analytics for the performance side. No tool does all of this, and any tool claiming to also reveal competitor spend or ROAS is overselling. The right question when evaluating tools is not "which has the most data?" but "which removes the most manual collection work while being honest about what its data means?" For a structured comparison of the platforms in this space, see the best ad spy tools 2026 breakdown.
Where AdMapix fits in this picture is specific and bounded. It is the creative-intelligence layer: a cross-network, searchable archive of ad creatives where you can hunt by keyword, format, or network, save examples into your evidence log, study video breakdowns, and set up recurring reports so the collection stage is less manual. That is a real, useful slice of the workflow — and it is one slice. It does not replace your analytics (which owns the performance truth), it does not replace platform ad libraries (which are the authoritative record of existence), and it categorically does not show you competitor spend, ROAS, or targeting, because that data is not public. Used as a complement — the findability layer on top of public creatives — it makes the collection and interpretation stages faster. Used as a claimed source of competitor performance, it (like every tool) would be misused. The honest framing is the useful one.

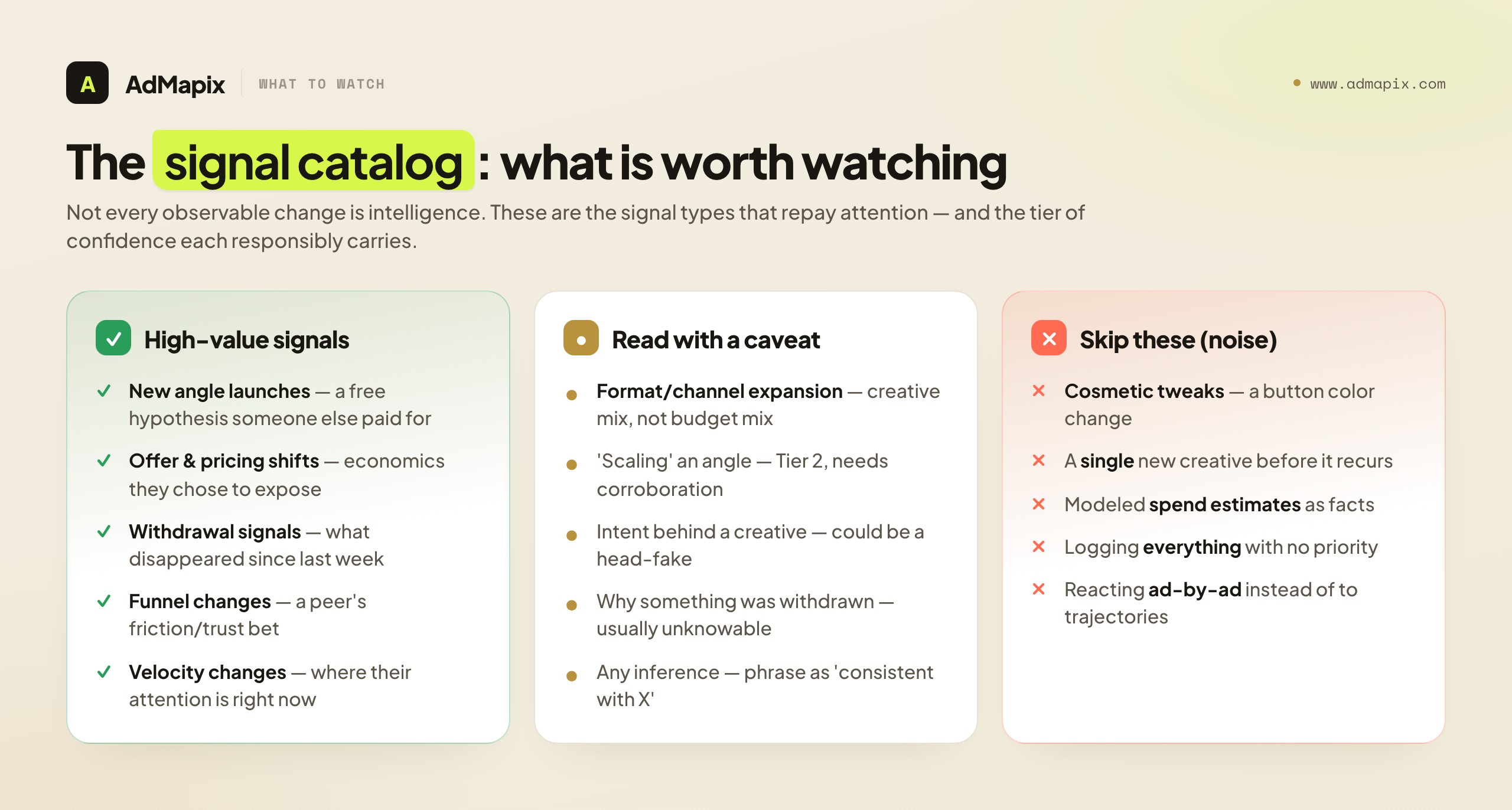
The Signal Catalog: What to Actually Watch For
The framework tells you how to process signals; this section tells you which signals are worth catching in the first place. Not every observable thing is intelligence. A competitor changing a button color is observable and almost never decision-relevant. The catalog below is the set of signal types that, in practice, repay attention — each tied to the kind of decision it can move, and each anchored to the evidence tier you can responsibly assign it.
New angle launches. The single highest-value signal. When a competitor introduces a messaging angle you have not seen from them — a new pain point, a new proof type (testimonial vs. data vs. demo), a new emotional register — that is a Tier 1 observation (the creative exists and says something new) with a Tier 2 read on whether it is a deliberate bet. New angles matter because they are the cheapest thing for you to test: you can clone the structure of an angle without copying the creative, run it against your control, and let your own data tell you whether the angle works for your audience. A rival's new angle is, in effect, a free hypothesis someone else paid to generate.
Offer and pricing shifts. When the deal changes — a discount appears or disappears, a trial lengthens or vanishes, a plan gets promoted or buried — you are seeing a Tier 1 fact about the competitor's economics that they have chosen to expose. These are higher-signal than creative changes because offers are expensive to change and rarely changed casually. An offer shift corroborated across the ad and the landing page is among the strongest signals in the whole discipline, because two independent surfaces are telling the same story. It can move your own pricing tests, your promotional calendar, and how you position value.
Format and channel expansion. When a competitor who ran only static ads starts producing video, or shows up on a network where they were previously absent, that is a Tier 1 observation of creative mix change and a Tier 2 inference about strategic direction. The caveat here is crucial and frequently violated: a shift in the creative mix you can see is not the same as a shift in the budget mix you cannot see. Phrase it as "they have expanded into video creative," never "they have moved budget into video." Still, format and channel expansion can legitimately prompt you to ask whether you are under-invested on a surface a serious rival is now contesting.
Velocity changes. How fast new creatives appear is itself a signal. A competitor who shipped two creatives a month suddenly shipping twenty is doing something — testing aggressively, launching a campaign, or responding to pressure. Velocity is a Tier 1 count and a Tier 2 interpretation, and it is best read as an intensity indicator: it tells you a competitor's attention is on this front right now, which raises the value of watching them closely for the next few cycles.
Landing-page and funnel changes. Beyond the offer itself, the structure of a landing page leaks strategy: a new lead-capture step, a removed form field, a changed guarantee, a new social-proof block, a reordered page. These are Tier 1 facts about the funnel a competitor is sending paid traffic into. They can move your own funnel tests directly, because they are a peer's bet about what reduces friction or raises trust for the same kind of buyer you are chasing.
Withdrawal signals. Often overlooked: a competitor stopping something is intelligence too. An angle that ran for months and then disappeared, an offer that was pulled, a channel that went quiet. A withdrawal is a Tier 1 observation (it is no longer there) with a deliberately humble Tier 2 read (you cannot know why — it could mean the angle failed, or that it succeeded and was retired, or that it was paused for a relaunch). Withdrawals are valuable precisely because they are easy to miss; building "what disappeared since last week?" into your collection routine catches signals a presence-only scan never sees.
The discipline of the catalog is selectivity. You are not trying to log every observable change; you are trying to catch the six or seven types of change that move decisions, and to deliberately ignore the rest. A program that watches for new angles, offer shifts, format/channel expansion, velocity changes, funnel changes, and withdrawals — and consciously skips cosmetic noise — will outperform one that records everything and prioritizes nothing.
Common Failure Modes (and How to Avoid Them)
Knowing the framework is not the same as running it well. The same handful of mistakes sink most programs, and all of them are avoidable once named.
Collecting without deciding. The most common failure. Teams build beautiful evidence logs and never convert them into briefs, so the program produces archives nobody reads. The fix is the single decision criterion: every cycle must end in tests, watch items, or explicit no-action notes. If a cycle ends with only a screenshot folder, the loop is broken.
Treating Tier 3 as Tier 1. Quoting a modeled spend estimate as if it were a measured fact, then setting your own budget against it. The fix is mandatory tiering and a standing rule: no Tier 3 claim ever enters a decision note as a justification. It can be a hypothesis to test; it can never be a premise to act on.
Watching too much. A competitor set of forty and a signal list of twenty guarantees the loop will be abandoned within a month. The fix is ruthless scope: a small set, a short signal list, reviewed quarterly. Depth on a few competitors beats shallow coverage of many.
Confusing the library mix with the spend mix. Inferring "they've shifted 60% of budget to video" because video is 60% of what you see in a library. The library shows creatives, not dollars, and creative count is a weak proxy for spend. The fix is to keep that inference firmly at Tier 2 and phrase it as "their creative mix shifted toward video," never "their budget shifted."
Reacting to noise. Treating a single new creative as a trend and chasing it before it recurs. The fix is the recurrence dimension in scoring: a change earns a decision when it recurs or is corroborated by a second surface (e.g., a matching landing-page change), not on first sighting.
Letting it decay. No owner, no cadence, no archive — the program runs hot before a pitch and goes cold afterward. The fix is the capability section above: name an owner, set a heartbeat, keep an archive. A discipline without a home is a project, and projects end.
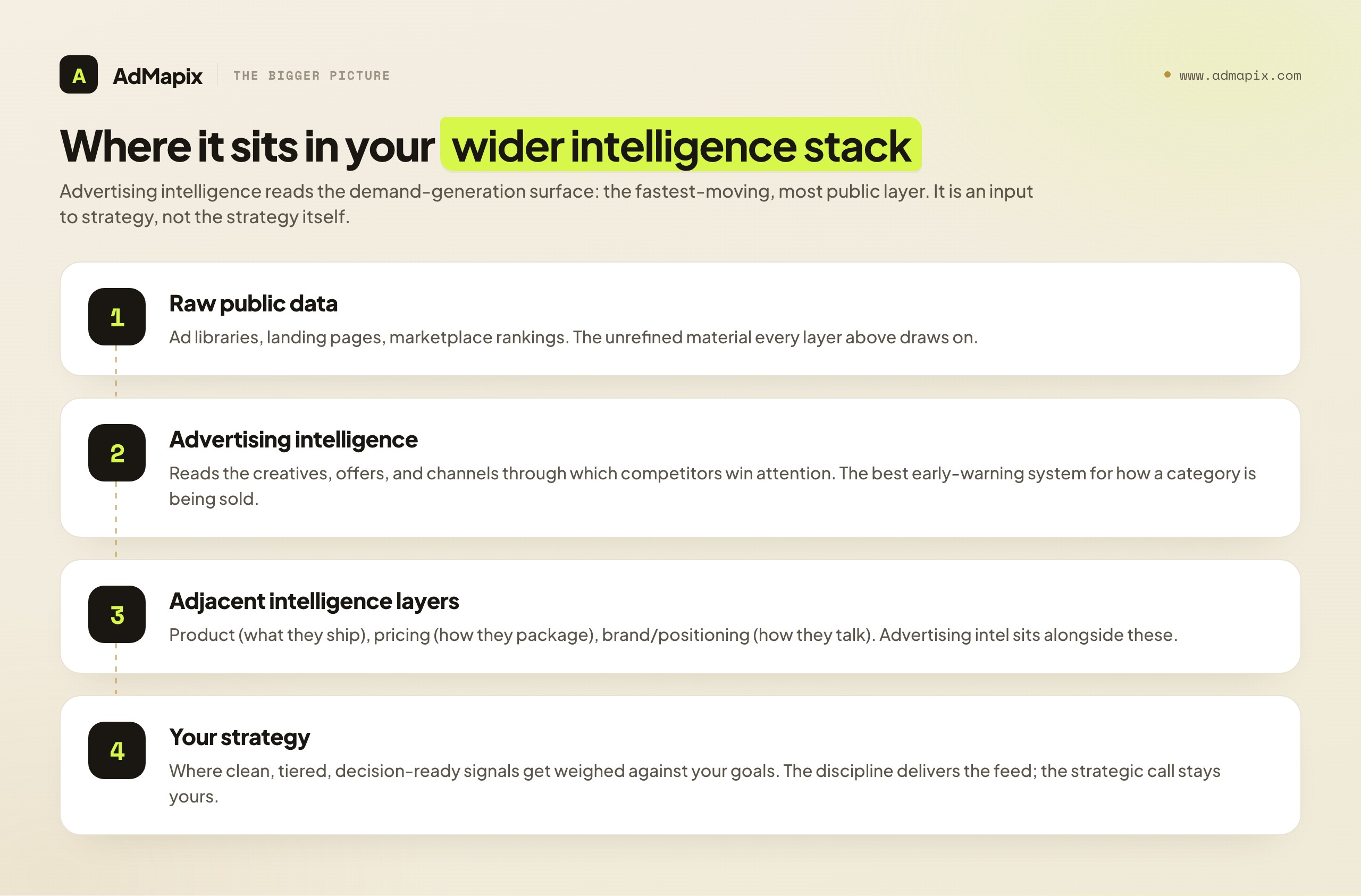
Where This Sits in Your Wider Intelligence Stack
Competitive advertising intelligence is one layer of a larger market-intelligence stack, and it is healthiest when it knows its boundaries. Below it sits raw public data — ad libraries, landing pages, marketplace rankings. Alongside it sits product intelligence (what competitors are shipping), pricing intelligence (how they package and charge), and brand/positioning intelligence (how they talk about themselves). Above it sits your own strategy, where these inputs get weighed against your goals.
Advertising intelligence is the layer that reads the demand-generation surface specifically: the creatives, offers, and channels through which competitors try to win attention and customers. It is uniquely valuable because advertising is the most public and most fast-moving of all these surfaces — competitors broadcast their messaging by definition, and they iterate it weekly. That makes it the best early-warning system you have for shifts in how a category is being sold. But it is an input, not a strategy. The discipline's job is to deliver clean, tiered, decision-ready signals up to the strategy layer — not to make the strategic call itself.
The teams that get the most from it treat it as exactly that: a reliable, honest, repeatable feed of "here is what changed in how the market is being sold, graded by how much you can trust it, ending in a short list of things you could do about it." That feed compounds. The first week it is noise; the first quarter it is a trajectory; the first year it is a forecasting habit that few competitors bother to build — which is, fittingly, its own competitive advantage. For the broader strategic context around all of this, the advertising intelligence guide connects this layer to the rest of the stack, and the best ad intelligence tools comparison covers the platforms that support it.
Frequently Asked Questions
What is competitive advertising intelligence in simple terms?
It is the practice of systematically watching competitors' advertising — the creatives they run, the offers they push, the channels they use, the angles they repeat — and turning what you observe into decisions about your own marketing. The key words are systematically and decisions: it is not a one-off competitor audit and not a folder of screenshots, but a repeatable loop with defined sources, a way of grading how reliable each observation is, and a clear path from raw signal to a test, a watch item, or a deliberate no-action note.
How is it different from my own analytics?
Your analytics are account-facing: they tell you, precisely and attributably, what happened inside your own funnel. Competitive advertising intelligence is market-facing: it tells you what is changing around you, in how the category is being advertised. They answer different questions and cannot substitute for each other. The discipline gets dangerous when a team tries to read competitor performance off public data (impossible) or tries to read market shifts off its own conversion reports (blind to everything outside the account). A healthy program runs both and connects them — public signals to generate hypotheses, your own tests to measure outcomes.
Is this the same as "ad spying"?
"Ad spy" is industry slang, but the practice is the opposite of secret surveillance. Everything legitimate competitive advertising intelligence touches is public by design: ads are broadcast to audiences, and major platforms run transparency libraries specifically so the public can inspect them. There is no privileged access, leaked data, or insider feed. The skill is not in obtaining the data — anyone can — but in collecting it systematically, verifying it, grading its reliability, and interpreting it without overreaching.
Can I see how much a competitor spends on ads?
No — not reliably, and not from any public source. Ad transparency libraries do not publish how much commercial advertisers pay, and no tool can extract a number that does not exist in the data. Where you see precise competitor spend figures, they are modeled estimates with wide error bars, not measurements. Treat them as hypotheses to test, never as facts to set your budget against. The honest version of the question that public data can answer is: "what angle are they betting on, how committed do they look, and what does that imply for my next test?"
What are evidence tiers and why do they matter?
Evidence tiers are a way of labeling how much you can trust each claim. Tier 1 is directly observable (a creative is running; a landing page states a 14-day trial) — high confidence. Tier 2 is inferable with caveats (they appear to be scaling an angle, inferred from many variants but without seeing impressions) — medium confidence, always caveated. Tier 3 is speculative and usually unknowable (exact spend, ROAS, targeting) — low confidence, kept out of decisions. They matter because the most damaging mistake in the whole discipline is letting a Tier 3 guess masquerade as a Tier 1 fact, which leads teams to set real budget against imagined competitor strategy.
What sources should I actually monitor?
Think of it as a stack, not a single feed. Platform ad transparency libraries are the authoritative record of which creatives exist. Cross-network creative-intelligence layers make those creatives searchable and comparable across networks. Landing pages and pricing surfaces reveal the offer economics behind a creative. Organic and owned surfaces (social, email, app listings, even hiring pages) leak intent before it becomes spend. Marketplace rankings reflect demand-generation outcomes. You do not monitor all of them constantly — you learn which surface answers which question, and reach for the right one when you need to verify a signal.
How often should I run this?
Weekly is the default heartbeat for collection, scoring, and decisions, because advertising creative cycles move on roughly that timescale and a slower cadence misses fast tests. The exception is scope — the competitor set and signal list — which you review quarterly, not weekly, because changing what you watch constantly destroys the comparability that makes "what changed?" answerable. The pattern is a fast loop inside a slow frame: weekly decisions, quarterly scope reviews.
How do I turn a signal into an actual decision?
Run it through one criterion: keep the signal only if it can change budget, creative, targeting, a landing page, or a client communication. If it cannot move one of those, it does not belong in the decision note no matter how interesting it is. For the signals that pass, convert each into exactly one of three outcomes — a test (run an experiment in response), a watch item (flag and revisit), or a no-action note (you considered it and consciously chose not to react). The no-action note matters as much as the test: it records that you weighed the signal, which keeps the program honest and the archive complete.
Where does AdMapix fit, honestly?
AdMapix is the creative-intelligence layer of this stack: a cross-network, searchable archive of ad creatives where you can hunt by keyword, format, or network, save examples into your evidence log, study video breakdowns, and set up recurring reports so collection is less manual. That is a real, bounded slice of the workflow. It is a complement to — not a replacement for — your own analytics (which owns performance truth) and platform ad libraries (the authoritative record of existence). It cannot show competitor spend, ROAS, or targeting, because that data is not public. Used as the findability layer over public creatives it speeds the collection and interpretation stages; that is the honest scope of what it does.
How do I know if my program is actually working?
A working program produces decisions, not archives. The simplest health check: does every cycle end in tests, watch items, or explicit no-action notes? If cycles end in screenshot folders nobody reads, the loop is broken at the decision stage. Over a longer horizon, the signal of a mature program is that you stop reacting to individual ads and start seeing trajectories — who is escalating, who is retreating, which angles are spreading across the category. If, a quarter in, you can describe a competitor's direction and not just their latest creative, the discipline is paying off. If you are still reacting ad-by-ad, you are collecting, not yet doing intelligence.
Sources
- Meta Ad Library
- Google Ads Transparency Center
- TikTok Commercial Content Library
- LinkedIn Ad Library
- AdMapix — cross-network ad creative intelligence
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Playable Ad Analysis for Mobile Games: A Practical Method
A practical method for playable ad analysis in mobile games: how to reverse-engineer a competitor's playable by the job it is built to do, decode its structure beat by beat, infer which concepts are likely working, turn observations into testable briefs, and stay honest about what a public playable proves (structure and intent) versus what it never can (spend, installs, retention, ROAS).

Best Mobile Game Ad Formats Across Platforms: A 2026 UA Playbook
A platform-by-platform guide to the best mobile game ad formats in 2026: which formats do the heavy lifting on Meta, Google, TikTok, AppLovin, and Unity; why the right format depends on platform, genre, and funnel stage; a format-selection framework; a creative-testing cadence; and the honest limits of what competitor ads can and cannot tell you about which format wins.

Meta Ads Library vs Ad Intelligence Tools for Game UA (2026): Which to Use, When, and Why
A definitive 2026 comparison of the Meta Ads Library vs dedicated ad intelligence tools for mobile game user acquisition — where the free transparency library genuinely helps, the structural limits that create blind spots for game UA creative research, a side-by-side capability matrix, the exact decision criteria for when to add a paid intelligence layer, and an honest account of what neither can show.