AppLovin Ads Spy Tool & Ad Intelligence (2026): Research Creative Without a Public Library
The 2026 guide to AppLovin ad intelligence and spy tools: why AppLovin has no public ad library, what you can and can't observe, a creative-evidence workflow, how to read video and playable structure, mediation vs UA, and turning patterns into UA test briefs.
By the AdMapix Research Desk — Updated June 21, 2026
AppLovin Ads Spy Tool & Ad Intelligence (2026): How to Research Creative Without a Public Library
An "AppLovin ads spy tool" sounds like it should be a backdoor into competitors' campaigns — and the single most important thing to understand is that it isn't, because AppLovin has no public ad library. Unlike Facebook's Ad Library, AppLovin publishes no searchable archive of every active ad. AppLovin is a mobile ad network and optimization engine (its AXON AI predicts which users will engage with an advertiser's product), so "AppLovin ad intelligence" means building your own creative-evidence workflow from the ads you can actually observe — not querying a database that doesn't exist.
This guide is for mobile UA managers, game marketers, ecommerce advertisers testing AppLovin, creative strategists, and agencies who want a repeatable method instead of a screenshot folder. It covers what AppLovin actually exposes, what you can and can't prove from public creative, a disciplined research workflow, how to read video and playable structure (each fails and wins for different reasons), the mediation-vs-UA distinction that trips up most beginners, and how to turn captured patterns into UA test briefs. We'll be honest throughout about the hard boundary: you can study the creative, never the spend, ROAS, or targeting.
The core principle: an AppLovin ads spy tool is a way to collect, tag, and analyze the creatives served across the AppLovin/AXON network — not a window into private campaigns. What survives on an optimization network is signal (the engine kept serving it), so repeated patterns are worth studying. But frequency is the strongest honest signal you get; everything about budget and performance stays private.
For the broader app-network method, see our mobile app ad spy tool guide; for the games-specific deep dive, mobile game ad spy tool; and for the full landscape, best ad spy tools 2026.

TL;DR — AppLovin Ad Intelligence in 2026
- AppLovin has no public ad library. "AppLovin ad intelligence" is a research workflow, not a database search — read official context, capture observable creatives, group by pattern, label what's proven vs assumed.
- You can observe the creative surface; you cannot infer the media plan. Format, hook, offer, app category, and localization are visible. Spend, ROAS, install volume, and targeting are private — never present them as fact.
- Frequency and recency are your strongest honest signals. A creative that repeats survived AXON's optimization long enough to keep serving — useful, but not proof of profitability.
- Score each format on its own rules. A 15-second video, a playable, a rewarded unit, and a static all win and fail for different reasons; one rubric flattens them.
- Separate mediation from user acquisition. What an app shows to monetize its own users is a different question than what it runs to acquire new ones — confusing the two is the most common beginner error.
- The workflow ends in a brief. A repeating hook becomes a creative test; a dominant format becomes a production brief. Research that never ships a test produces zero growth.
What AppLovin Actually Is — and Why There's No Library
This is the fact that reframes the whole task. AppLovin is a mobile marketing-technology company and optimization network, not an ad-transparency archive. Its own materials frame its products around acquiring users, monetizing them, and measuring performance; its AXON engine connects advertisers with users across a very large daily-active audience and predicts who's likely to engage. None of those products is built to show you a rival's full creative set the way a political-ad archive or a social ad library does.
That distinction changes the question you can answer:
| Question you might ask | Answerable on AppLovin? |
|---|---|
| "Show me every ad advertiser X runs on AppLovin" | No — no public library exists |
| "How much does advertiser X spend on AppLovin?" | No — spend is private |
| "What's advertiser X's targeting and ROAS?" | No — AXON decides delivery internally; results are private |
| "What creative formats and hooks are common in my category?" | Yes — with disciplined evidence capture |
| "What should I test next based on what's serving?" | Yes — that's the whole point |
The first three are off-limits on any honest tool. The last two are answerable, and they're the ones that actually move UA. So "AppLovin ad intelligence" is not a lookup — it's a method: read official scope first, capture creatives you can observe, group by format and hook, and write down what the evidence does and doesn't prove. A tool helps by making that captured evidence searchable; it does not, and cannot, hand you a competitor's private campaign.
What AppLovin Exposes — and What Stays Private
AppLovin exposes creative output served through its network, plus product-level context about how the network optimizes. It does not publish a competitor ad library with budgets or targeting. Because the creatives that survive are the ones AXON could match to responsive users, repeated patterns are signal, not noise — but the boundary between observable and private is absolute.

| What you CAN observe | What you CANNOT infer from it |
|---|---|
| Creative format (video, playable, rewarded, static) | Campaign budget or daily spend |
| Hook and offer in the first seconds | ROAS or install-to-pay ratios |
| App category and genre being promoted | Audience targeting or geo splits |
| Repeated angles across many creatives | Bid strategy or account structure |
| Localization signals (language, casting) | Which placements or apps served it |
| Rough recency (a creative looks current) | Install volume or impressions |
Treat the left column as a hypothesis source and the right column as off-limits unless you have account-level data. When a finding falls in a "cannot infer" row, label it a hypothesis, not a fact. "This studio leans on rewarded-video playables" is supportable from observation; "this studio spends $X on AppLovin" is fabrication. This methodology line is what keeps your reports credible with a client or a CMO — overclaiming private data is the fastest way to lose that trust.
A Workflow That Actually Produces Intelligence
The most reliable AppLovin ad-intelligence workflow runs official context first, evidence capture second, pattern analysis third. Skipping any step is where most research goes wrong — teams either treat AppLovin's product pages as competitor data, or collect screenshots with no context that decay into trivia.
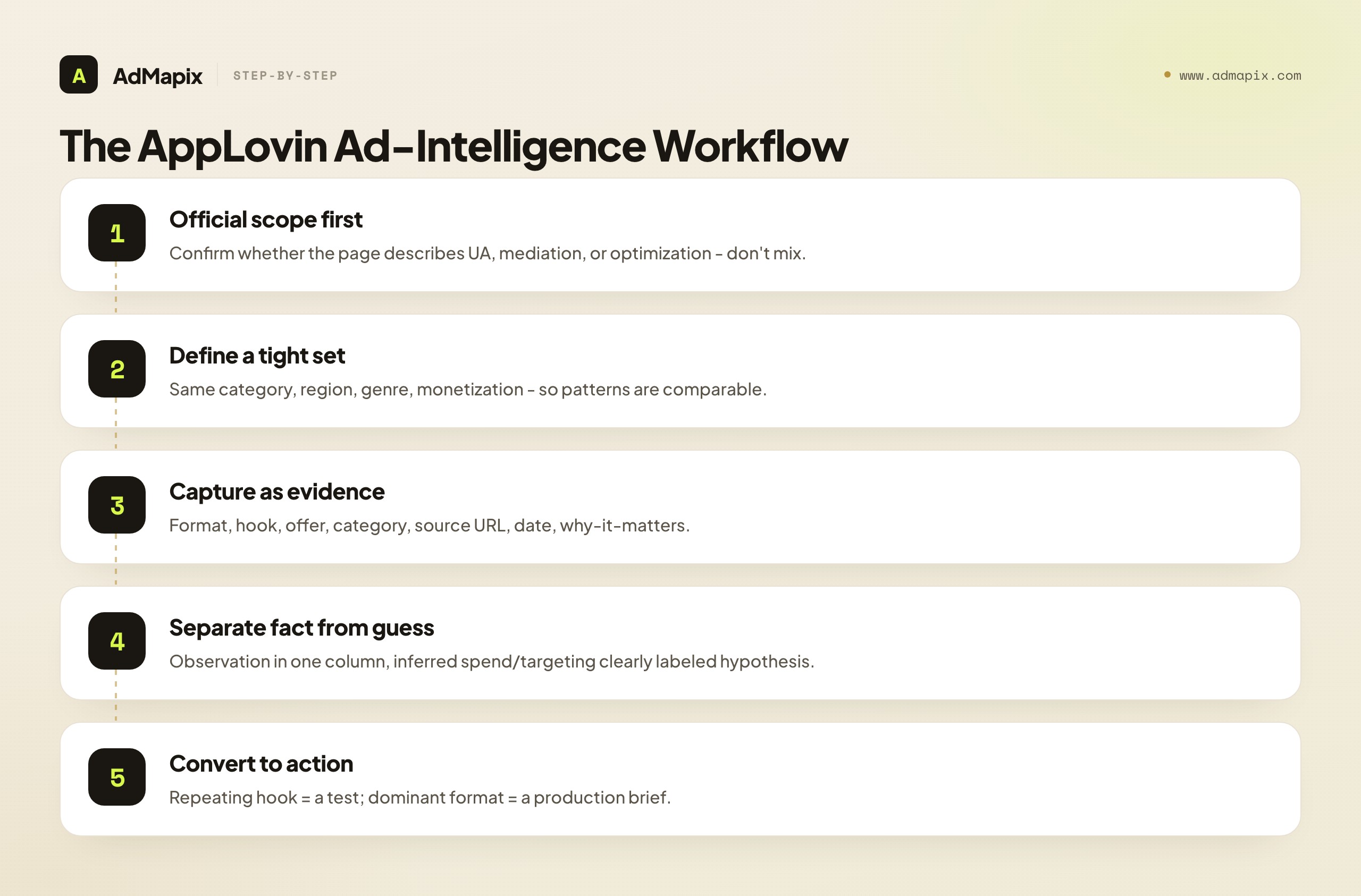
Step 1: Start with official scope
Before reading anything as "competitor intelligence," confirm what the AppLovin or AXON page you're looking at actually describes — a UA product, a mediation/monetization SDK, an optimization engine, or creative services. These answer completely different questions and must not be mixed. AppLovin's official context tells you how the network behaves (optimization-driven, AXON-matched); it does not tell you what any specific competitor is running.
Step 2: Define a tight competitor set
Lock the same app category, region, genre, and monetization model. A match-3 game's creatives and a 4X strategy game's creatives follow different rules; mixing them produces averages that describe nobody. A puzzle game and a hyper-casual runner don't share creative logic either. The tighter the set, the more meaningful the patterns.
Step 3: Capture each creative as evidence
For every example, record the asset, the format, the first-3-second hook, the offer or CTA, the app category, the source URL, the capture date, and one sentence on why it matters. That last field is what separates a research library from a folder of clutter. Without source and date, the example is unusable months later — and on AppLovin specifically, nothing fills that gap automatically.
Step 4: Separate observation from inference
Move budget, ROAS, and targeting claims into a clearly marked "hypothesis" column. This single discipline is what keeps an AppLovin ad-intelligence report credible. Observable facts ("rewarded-video playable, loss-state hook, US English") go in one column; inferences ("they're probably scaling this") go in another, explicitly labeled as guesses.
Step 5: Convert patterns into action
A repeating hook becomes a creative test; a dominant format becomes a production brief; a localized variant becomes a market note. The output is a format map, a hook list, and a test backlog — not a screenshot folder. Research that never becomes a brief produces zero growth. For the broader competitor-to-test discipline, see paid ads competitor research.
How to Capture Creative Evidence Worth Keeping
Good evidence capture means saving the creative plus enough context that a teammate can act on it months later. A screenshot with no source, date, or note is close to useless. The minimum fields for every saved AppLovin creative:

| Field | Why it matters |
|---|---|
| Asset (the creative itself) | The thing you're studying |
| Format (video/playable/rewarded/static) | Each format is judged by different rules |
| First-3-second hook | Carries most of a mobile ad's performance |
| Offer / CTA | The conversion mechanism |
| App category & genre | Keeps patterns comparable |
| Apparent market (language, casting) | Localization signal |
| Source URL & capture date | Makes the example verifiable and findable |
| Why-it-matters note | Turns a screenshot into reusable intelligence |
Work from a defined competitor set rather than whatever surfaces randomly, and tag consistently so the library stays queryable — "show me every rewarded-video playable with a loss-state hook in match-3" is the kind of query a tagged library answers and a screenshot folder can't. The teams that win run this capture discipline every week until the library itself becomes the most valuable creative asset they own.
Reading Video and Playable Structure
The value in mobile creatives is in their structure, so judge each format on its own terms instead of treating every ad as one bucket. This is the single most useful analytical habit in AppLovin research, because the network is heavy on playables and rewarded video — formats that win and fail for entirely different reasons than a feed video.
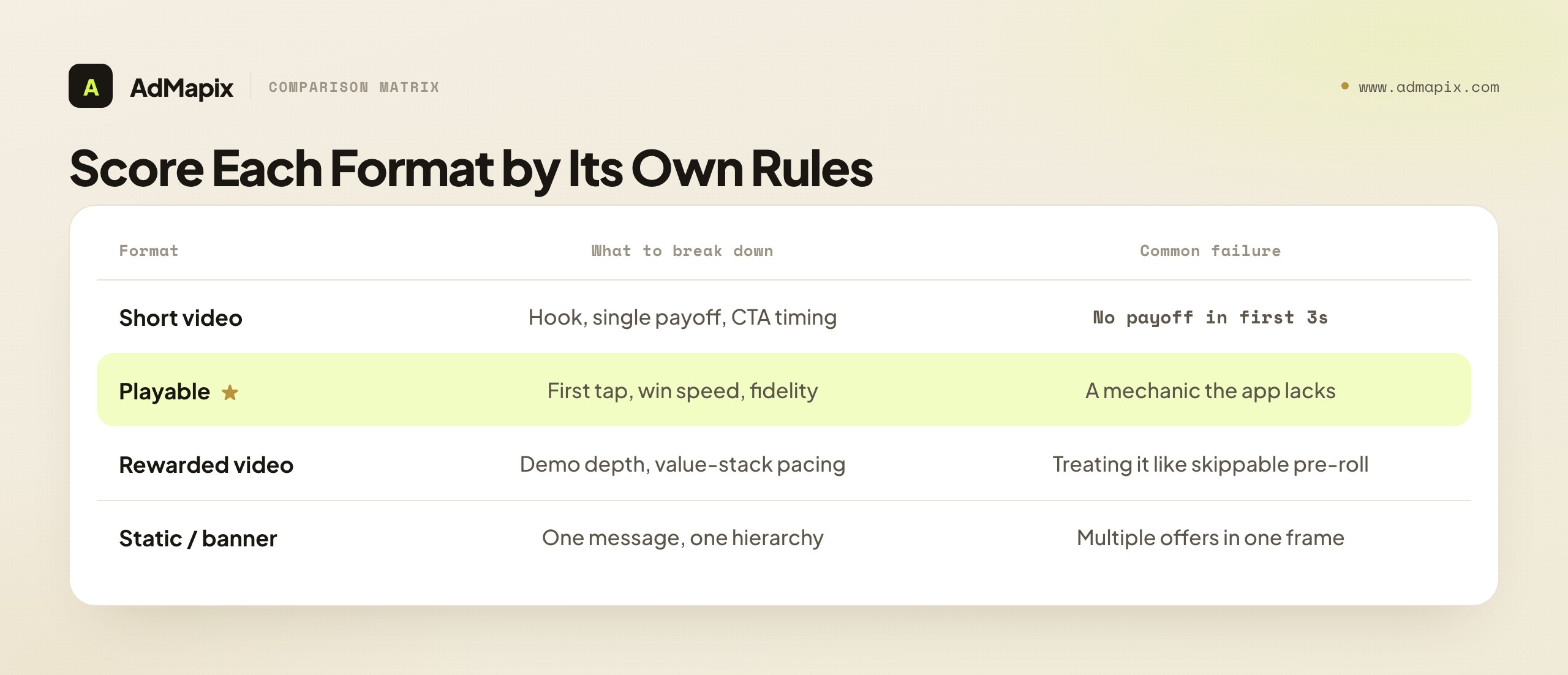
| Format | What to break down | Common failure |
|---|---|---|
| Short video ad | Hook, single payoff, CTA timing | No payoff in the first 3 seconds |
| Playable ad | First interaction, win speed, fidelity to game | A mechanic that doesn't exist in the real app |
| Rewarded video | Depth of demo, value-stack pacing | Treating it like a skippable pre-roll |
| Static / banner | One message, one visual hierarchy | Cramming multiple offers into one frame |
A 15-second video ad lives or dies on its first three seconds and a single clear payoff. A playable ad lives or dies on whether the interactive moment matches the real game and how fast it reaches a win or a CTA — and AppLovin is one of the networks where playables matter most. Rewarded video sits in a different mental state again: the user opted in for a reward, so the ad can show more and sell harder, and the value-stack pacing (how it layers benefits over the runtime) is the thing to study. Scoring all of these with one rubric flattens the very differences that decide performance.
A closer look at playables on AppLovin
Because playables are so central to AppLovin, they deserve their own lens. When you study a competitor's playable, work through the interaction: the first tap (does it get a finger on screen in the first two seconds?), the tutorial framing (does it teach the real loop, or a simplified/fake version?), the friction-to-reward ratio (how many taps to the satisfying payoff?), and the end-card handoff (where and how it sends to the store). Fake playables — showing a mechanic the app doesn't have — win installs but tank retention, so note them as a what-not-to-do as much as a what-works. The catch: playables are interactive HTML5, far harder to "save" than a video, so when you study one, record the interaction flow in writing — it survives even though the playable itself doesn't.
Mediation vs User Acquisition: Don't Confuse Them
This is the distinction that trips up most beginners, and getting it wrong corrupts an entire research set. AppLovin has two sides:
- Monetization / mediation (MAX): tools that help app publishers earn from their own ad inventory — i.e., what ads an app shows to its users.
- User acquisition (AXON): the engine that helps advertisers acquire new users — i.e., what ads an app runs to grow.
These answer opposite questions. What an app shows you while you play it is its monetization, not its acquisition strategy. If you screenshot the ads served inside a competitor's game and call that "their UA creative," you've mislabeled the evidence — those are ads other advertisers paid to show to that game's users, not the game's own acquisition ads. Keep the two strictly separate: ad-intelligence research is about what advertisers create to acquire, not what publishers show to monetize. Confusing them is the fastest way to build a research set that describes the wrong thing entirely.
Why AppLovin Creative Matters More in 2026
To understand why this research is worth the discipline, you have to understand how AppLovin's AXON engine changed the job. On an optimization network, you don't pick the audience — the engine does, from your creative and conversion signals. AXON predicts which users will engage with an advertiser's product and serves accordingly. That means the lever you control is overwhelmingly the creative: the format, the hook, the offer, the pacing. The audience layer that UA managers used to fight over is now the algorithm's job.
The consequence for competitor research is direct: on AppLovin, creative is the primary differentiator, and creative is the one thing you can actually observe. When delivery is AI-optimized, the difference between a winning and losing campaign is mostly the ad itself — so studying competitor creative is research into the single biggest determinant of UA success on the network. A team that systematically reads the creative market is studying exactly the lever that decides outcomes; a team obsessing over invisible targeting is chasing a knob the engine already turned.
This also reframes the "I can't see their targeting" complaint that newcomers fixate on. On AXON there's little targeting to see — the engine handles it. What's worth seeing is the creative, and that's observable. So the absence of a public library, while real, matters less than it first appears: the most valuable intelligence on an optimization network is the creative structure, and that survives observation even when budgets and audiences don't. The honest researcher accepts the boundary and mines the side that's both visible and decisive.
| What you control on AXON | What the engine controls |
|---|---|
| Creative (format, hook, offer, pacing) | Audience selection |
| Conversion signals you send | Delivery and bidding |
| Which creatives you feed it | Who actually sees each ad |
The takeaway: don't lament that AppLovin hides spend and targeting. The creative it lets you observe is the more valuable intelligence in 2026, because creative is where campaigns on the network are won and lost.
How AppLovin Fits the In-App Network Landscape
AppLovin isn't the only library-less in-app network, and understanding how it relates to its peers sharpens your research. The major in-app advertising networks — AppLovin (AXON), Unity Ads, ironSource, Mintegral, and Moloco — share a defining trait: none publishes a public ad library. They're optimization-and-monetization platforms, not transparency archives. But they differ in emphasis, which affects what creative you'll see and how to research each.
| Network | Emphasis | Creative you'll see most | Research note |
|---|---|---|---|
| AppLovin / AXON | UA optimization + monetization (MAX) | Playables, rewarded video | Heavy on playables; separate MAX (monetization) from AXON (UA) |
| Unity Ads | Game-focused UA + mediation | Gameplay video, playables | Strong in games; rewarded-heavy |
| ironSource | Monetization + UA (now part of Unity) | Interstitial, rewarded | High-impact interstitial creative |
| Mintegral | Performance UA, programmatic | Playable + video mix | Volume and variant breadth |
| Moloco | ML performance ads | Performance-tuned video | ML-friendly variant testing |
The practical implication: because all of these are library-less, the research method is the same across them — capture observable creatives, classify by format and hook, never infer spend. But the creative norms differ, so a fail-state gameplay hook common on AppLovin rewarded slots may show up differently on a Moloco performance placement. This is also why a cross-network tool beats a single-network one for in-app research: your competitors run across several of these networks, and seeing how one studio adapts a concept across AppLovin, Unity, and Mintegral teaches you more than any single network's slice. For the network-by-network method, see mobile app ad spy tool.
The reason to single out AppLovin specifically — and the reason this guide exists — is that AXON's scale and its playable-heavy inventory make it one of the most important and least transparent networks in app UA. Master the AppLovin research method and the same discipline transfers cleanly to its peers.
Building a Format Map and a Hook List
The concrete output of good AppLovin research isn't a report nobody reads — it's two living artifacts that directly feed creative production: a format map and a hook list. Building them is how you turn weeks of captured creatives into something a producer can brief from on day one.
The format map answers "what formats dominate my category on AppLovin, and in what mix?" After tagging a few dozen creatives by format (playable, rewarded video, vertical video, static), you'll see the distribution — for example, "70% of top match-3 competitors lead with rewarded-video playables, 20% vertical video, 10% static." That distribution is a production decision: it tells you where to invest your creative budget. If your studio is shipping mostly static while the category runs playables, the format map just found your biggest gap — before you spent a dollar testing.
The hook list answers "what openings actually repeat in my category?" Tag each creative's first-3-second hook (loss-state, satisfying-loop, before/after, fail-bait, social proof, curiosity gap), and the convergent ones become your test backlog. A hook that appears across six independent competitors is a far stronger bet than one clever ad — convergence is the signal. The hook list turns "I have a vague sense of what works" into a ranked, evidence-backed list of openings to test on your own product.
| Artifact | What it answers | How it feeds production |
|---|---|---|
| Format map | Which formats dominate, in what mix | Where to invest creative budget |
| Hook list | Which openings repeat across competitors | A ranked, evidence-backed test backlog |
| Pattern library | Every tagged creative, searchable | The brief comes from the library, not a blank page |
Both artifacts are living — each weekly research loop updates them. Over a quarter, the format map tracks how your category's creative is shifting (are playables giving way to UGC video?), and the hook list accumulates which openings won your tests versus which only worked for competitors. That accumulated, category-specific, validated knowledge is the real asset — far more valuable than any single competitor audit, and impossible to build without the disciplined capture-and-tag habit. It's the difference between researching AppLovin once and building a permanent creative-intelligence advantage on it.
What Public Creative Data Can and Cannot Prove
Public creatives prove what an advertiser is willing to show and how often a pattern repeats; they do not prove what's working. This is the methodology line that keeps reports honest.
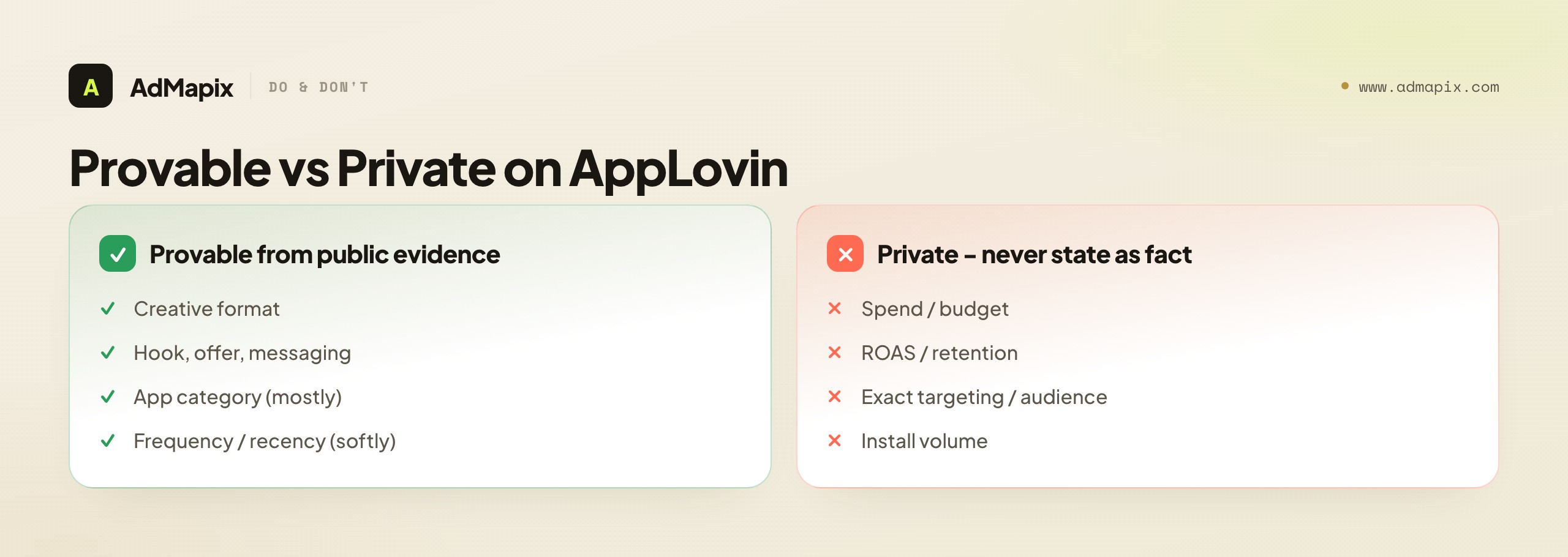
| Signal | Provable from public evidence? | Notes |
|---|---|---|
| Creative format (playable, rewarded, vertical, static) | Yes | Observable directly from the ad unit |
| Hook, offer, on-screen messaging | Yes | Capture the first 3 seconds and the CTA |
| App category & apparent market | Mostly | Inferred from store listing, language, localization |
| Frequency / recency | Yes (softly) | A repeated, recent creative survived optimization |
| Spend / budget | No | Not exposed; never estimate without account data |
| ROAS / retention / conversion | No | Performance is private to the advertiser |
| Exact targeting / audience | No | AXON decides delivery internally |
A creative you see many times is a reasonable signal that it survived the network's optimization long enough to keep serving — your strongest honest signal. But you cannot read spend, install volume, or ROAS from the creative itself, and you should never present an inferred budget or targeting guess as fact. Treat frequency and recency as your best signals, and label every spend or performance claim as an assumption unless you have account-level data. When a finding falls in a "No" row, it's a hypothesis: "this studio leans on rewarded-video playables" is supportable; "this studio spends $X" is not.
A Worked Example: From AppLovin Creatives to a UA Test
Here's the whole workflow on a real decision. A hybrid-casual game studio's UA is stalling on AppLovin — their playables convert worse than they used to, and "research" is a folder of competitor ad screenshots no one acts on.
Official scope + set. The UA manager first confirms she's reading AppLovin's UA/AXON context, not its mediation docs, so she doesn't mistake monetization behavior for acquisition strategy. She locks the set: hybrid-casual merge games, US market, playable + video formats.
Capture + separate. Over a week she captures ~20 competitor creatives with full context — format, hook, offer, category, source, date. She keeps observation ("rewarded playable, merge-then-defend loop, loss-state framing") strictly separate from inference ("looks like they're scaling it" — labeled a guess).
Pattern. Clustering by format and hook, a pattern emerges: six competitors run playables that show a merge mechanic and a 30-second combat raid — a "merge to build, then defend" loop — while her studio's playables show only the merge. The combat layer is the convergent angle she's missing. Frequency across six advertisers makes it signal, not an anecdote.
Brief + validate. She briefs a new playable: "merge for the first 8 seconds, then trigger a 5-second raid the player must tap to defend, win-state by second 15." She builds it on her own game's real mechanic (the raid actually exists — no fake-mechanic retention trap), ships it against her control, and it lifts install rate and D1 retention. The competitor playables didn't tell her what to copy — they revealed a structure her category had converged on that her real game could honestly deliver.
The lesson: official scope kept her from mislabeling monetization as UA; the separation discipline kept the report honest; and the convergent pattern — not any single ad — became the test her own data validated.
AppLovin Ad Research Tools, Compared
There's no single "AppLovin spy tool" with a magic library, because the library doesn't exist. Tools split by how they help you capture and analyze the creative you can observe.
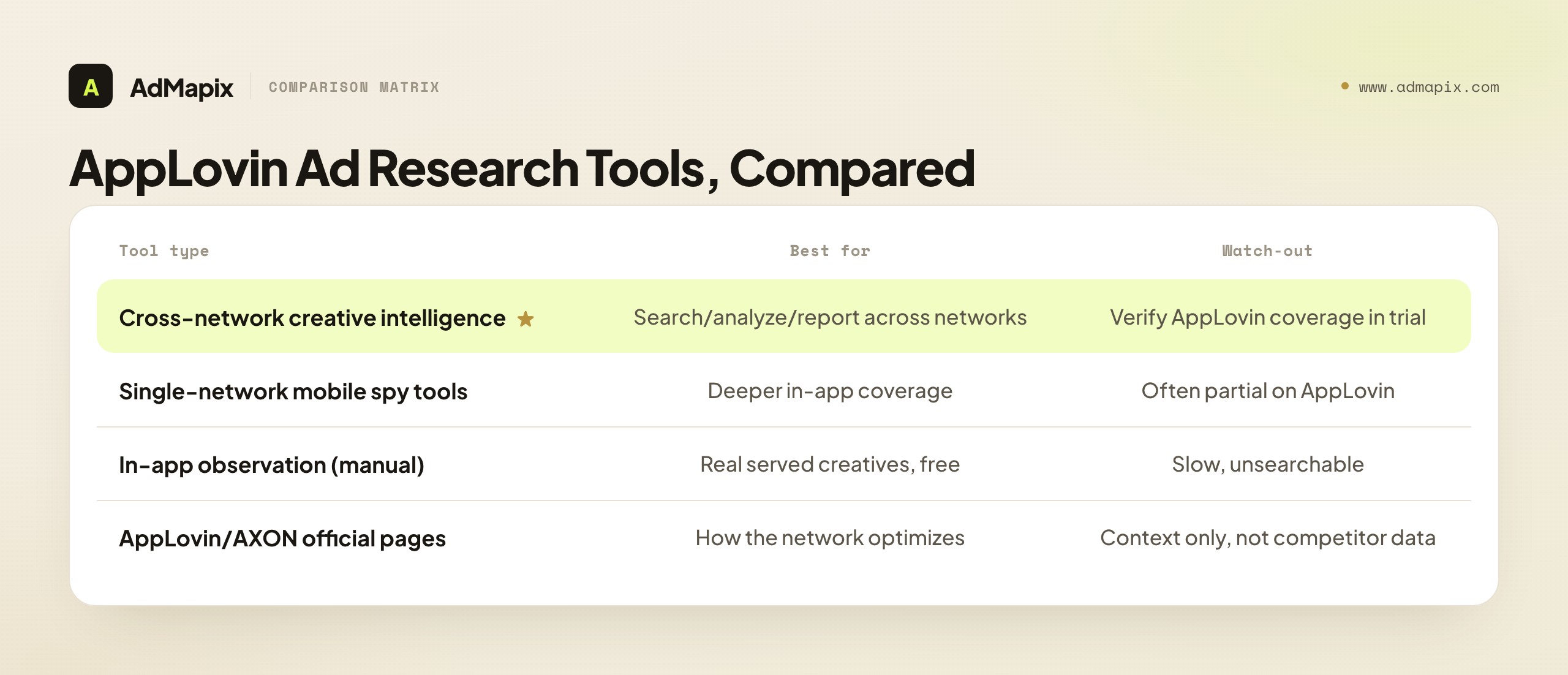
| Tool type | Best for | Watch-out |
|---|---|---|
| Cross-network creative intelligence (e.g., AdMapix) | Making captured creatives searchable, analyzable, reportable across networks | Coverage of AppLovin specifically varies — verify in trial |
| Single-network mobile spy tools | Deeper coverage of in-app networks | Often still partial on AppLovin; blind to Meta/TikTok |
| In-app observation (manual) | Seeing real served creatives free | Slow, unsearchable, only what's targeted to you |
| AppLovin/AXON official pages | Understanding how the network optimizes | Context only — not competitor data |
The honest framing: no tool gives you an AppLovin "ad library" because AppLovin publishes none. What good tools give you is a way to aggregate, search, and analyze the creatives observable across the in-app ecosystem, plus the cross-network view (Meta, TikTok, and more) that shows how the same competitor adapts a concept across surfaces. Judge any tool on its actual AppLovin and in-app coverage for your category in a trial — aggregation depth varies enormously, and a tool strong on Meta can be thin on AppLovin. For the full landscape, see best ad spy tools 2026 and marketing intelligence tools.
A Repeatable Weekly Research Loop
AppLovin creative research compounds as a habit. Here's a lightweight weekly loop that takes under an hour and builds a real asset.
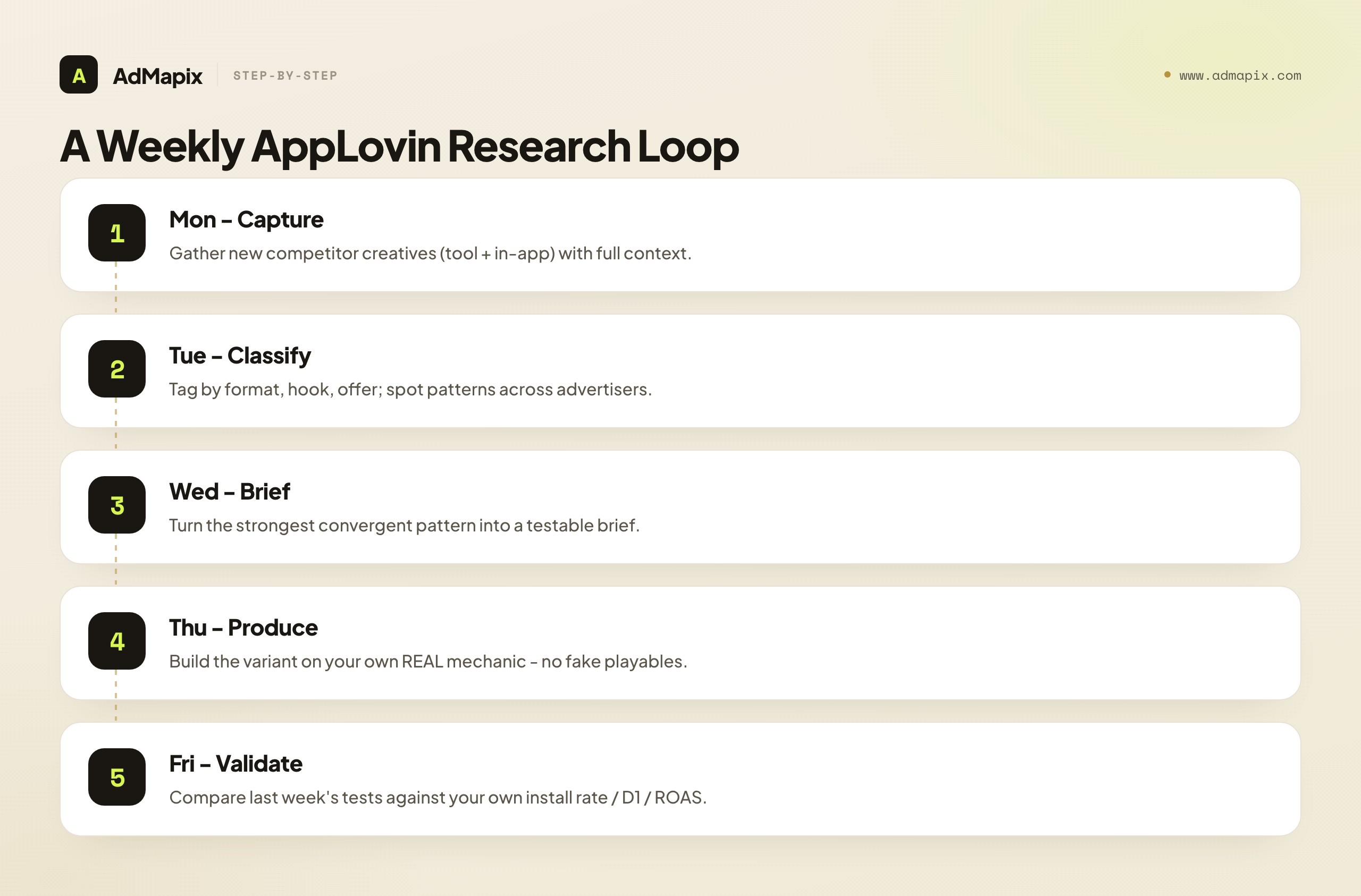
| Day / step | Action | Output |
|---|---|---|
| Monday — capture | Gather new competitor creatives (tool + in-app spot-check) with full context | Fresh, tagged evidence |
| Tuesday — classify | Tag by format, hook, offer; spot patterns repeating across advertisers | Updated format map + hook list |
| Wednesday — brief | Turn the strongest convergent pattern into a testable creative brief | A ready-to-produce concept |
| Thursday — produce | Build the variant on your own real mechanic (no fake playables) | Test-ready creative |
| Friday — validate | Compare last week's tests against your own install rate / D1 / ROAS | Promote, kill, or iterate |
Three rules: capture context every time (AppLovin gives you none automatically); keep observation and inference in separate columns (never present a spend guess as data); and always end on your own data (frequency suggests a creative survived; only your campaign proves it works for you). A team running this loop for a quarter builds a searchable history of what's serving in their category and what converted — an asset no single look matches. For the cross-platform version, see how to spy on competitors' ads in 2026.
AppLovin Creative Norms by Game Genre
Because AppLovin's inventory skews toward games, the creative norms shift meaningfully by genre — and reading a competitor's ad against its genre's conventions is what separates useful analysis from a generic teardown. A loss-state hook that's table stakes in puzzle can feel wrong in a 4X strategy ad, where the promise is depth and dominance, not a quick almost-win.

| Game genre | Dominant AppLovin format | What the hook usually promises | Watch for (the trap) |
|---|---|---|---|
| Puzzle / match-3 | Rewarded playable | A satisfying solve / near-win loss-state | Fake "pull the pin" mechanics the game lacks |
| Hybrid-casual / merge | Playable + short video | "Merge to build, then defend" combined loop | Showing only half the loop |
| Hyper-casual | Short video | One satisfying mechanic in 3 seconds | Over-explaining a one-tap game |
| 4X / strategy | Vertical video | Power, dominance, alliance/server stakes | A fast-win hook that misframes a slow game |
| RPG / mid-core | Video + playable | Progression, collection, a hero power fantasy | Combat that the real game doesn't deliver |
| Idle / simulation | Video | Numbers going up, satisfying automation | Promising depth an idle loop doesn't have |
Two patterns cut across genres. First, the fake-mechanic trap is everywhere on playables — a creative that shows a mechanic the game doesn't have wins installs and destroys retention, so catalog these as a what-not-to-do rather than a model. Second, the hook must match the genre's emotional promise: puzzle sells tension-and-relief, strategy sells power-and-stakes, hyper-casual sells instant satisfaction. When you read a competitor ad, ask "does the hook fit what this genre's players actually want?" — because a structurally clever ad that misframes the genre will acquire the wrong users who churn fast. Match the hook to the genre's promise, and adapt the structure to your own game's real mechanic.
How to Brief a Test From AppLovin Research
The final, most-skipped step is turning a captured pattern into a brief a producer can actually shoot. A pattern in a spreadsheet isn't a deliverable; a brief is. Here's how to write one that survives contact with production.
State the hypothesis as a testable claim. Not "competitors use loss-state hooks" but "opening on a loss-state in seconds 0–2 will lift our playable install rate versus our current polished-gameplay opening." A hypothesis names the change, the expected effect, and the metric — so the test has a clear pass/fail.
Specify the structure, not the asset. Describe the beats to recreate on your own game: "merge for 8 seconds, trigger a 5-second raid the player taps to defend, win-state by second 15." This adapts the competitor's proven structure to your real mechanic — never reuse their footage, which is a legal risk and a creative dead end. The reusable intelligence is the skeleton, not the skin.
Set the success metric and kill condition before production. "Beat control on install rate over a 7-day test; kill if it underperforms control by 15%+." Writing the kill condition before you're emotionally invested in the creative is what keeps a borderline result from becoming a "let's give it two more weeks" graveyard. This discipline mirrors the broader ad budget and testing framework.
Cite the evidence and its confidence. Note why you're testing this — "six independent competitors run this combined-loop structure" — and label the confidence (high, because it's convergent across advertisers). This tells the team the bet is evidence-backed, not a creative's hunch, and it makes the eventual result interpretable: if a high-confidence convergent pattern fails for you, that's a meaningful learning about your game, not just a dud ad.
Honor the genre's promise. Make sure the brief's hook fits your game's genre and players. A loss-state opening that works for a competitor's puzzle game has to map to a real, satisfying moment in your puzzle game — adapting the structure to a mechanic you can honestly deliver, so the installs you win actually retain.
A brief built this way — testable hypothesis, structural beats, pre-set metric and kill condition, cited convergent evidence, genre-fit hook — is the bridge between AppLovin research and shipped, validated creative. Without it, even excellent research dead-ends in a document nobody acts on. With it, every weekly research loop ends in a producible test, and your AppLovin intelligence compounds into a creative pipeline that out-iterates competitors who only collect screenshots.
AppLovin Research for Agencies and Multi-App Portfolios
Everything above scales differently when you're researching AppLovin for several apps or clients at once, and a few adjustments make the difference between a workflow that survives contact with five accounts and one that collapses under its own screenshots.
The core change is structure for reuse across accounts. A solo studio can keep a loose pattern library; an agency running AppLovin research for six game clients needs the library tagged so a hook discovered for Client A's match-3 is instantly findable when Client B launches a match-3 of their own. Tag by genre and mechanic first, client second — because creative patterns transfer by genre, not by account. The merge-then-defend playable that's converging across hybrid-casual advertisers is relevant to every hybrid-casual client you have, and a genre-first taxonomy surfaces it for all of them at once.
The second adjustment is making the research a billable deliverable, not invisible labor. For agencies, the AppLovin research is part of what the client pays for, so it should leave a visible artifact: a monthly per-client creative-intelligence report showing the genre's converging hooks, the format map, the fatigue read, and the specific tests you briefed from it. That report does triple duty — it justifies the retainer, it aligns the client on creative direction, and it becomes the institutional memory that makes next month's research faster. A folder of screenshots is invisible labor; a dated, structured report is proof of work that renews contracts.
The third is separating shared genre intelligence from account-specific signals. Some findings (a genre-wide hook convergence) apply to every client in that genre; others (a specific competitor a single client cares about) are account-bound. Keep the shared layer reusable and the account layer scoped, so you're not re-researching the same genre convergence for every client while still giving each client the competitor-specific read they came for.
The honest scaling limit: at portfolio scale, manual screenshotting across AppLovin and the other in-app networks for many clients simply doesn't hold together — which is precisely where a tool that makes captured creatives searchable, cross-network, and reportable stops being a convenience and becomes the only way the workflow survives more than a couple of accounts.
Common Mistakes
- Expecting a complete public ad library. AppLovin is an optimization network, not a transparency archive; plan for evidence capture, not a download button.
- Confusing mediation and acquisition. What an app shows to monetize its own users answers a different question than what it runs to acquire new ones. Mislabeling this corrupts the whole set.
- Treating official pages as competitor data. AppLovin and AXON pages describe how the network behaves; they are context, not a rival's creative set.
- Judging every format the same way. A playable and a 15-second video have different jobs; one scoring rubric flattens both.
- Inferring spend or ROAS. Visible creatives carry no budget or revenue data; stating one is fabrication, and the fastest way to lose a CMO's trust.
- Saving assets with no context. Without source, date, format tag, and a why-it-matters note, the example can't be reused or trusted later.
- Copying fake-mechanic playables. A playable showing a mechanic the app doesn't have wins installs and tanks retention — note it as a what-not-to-do, don't replicate it.
When to Use AdMapix
AdMapix fits once you're past one-off curiosity and into recurring competitive creative research — after you've read the official context and started collecting real creatives. It's built for mobile UA teams, game marketers, creative strategists, and agencies who need captured ads to become searchable, analyzable, and reportable. Use Search AdMapix to widen discovery across networks in your category, Media to keep examples searchable with your own tags, Video Analysis to break down video and playable-style structure, and Reports to turn a pattern into a team- or client-ready output. Compare access on Pricing, and create an account from Login when scattered screenshots start costing you time.
It is not the right tool if you only need to glance at a single ad once, or if you expect it to reveal a competitor's AppLovin spend, targeting, or private account data. No public tool can do that, and AdMapix doesn't claim to — it gives you cross-network creative search, saved media, video analysis, tagging, and reports, and it leaves private campaign metrics where they belong: private.
FAQ
Does AppLovin have a public ad library?
No. AppLovin does not publish a public competitor ad library where you can look up every creative a given advertiser is running. Its official site and AXON pages describe its products and capabilities, which you should treat as context, not competitor data. To research creatives, you build your own evidence workflow from ads you can observe — which is exactly what "AppLovin ad intelligence" means.
What is an AppLovin ads spy tool, then?
It's a way to collect, tag, and analyze the creatives served across the AppLovin/AXON network — video, playable, rewarded, and static — plus the offers and app categories behind them. It helps you find repeated formats and hooks in your category and turn them into tests. It does not expose budgets, ROAS, targeting, or any private campaign data, because no honest tool can read those from a creative.
Can I see how much a competitor spends on AppLovin?
No. Spend, install volume, and ROAS are account-level data that no public spy tool can read from a creative. You can observe which creatives repeat and look recent — which suggests they survived AXON's optimization — but treat any budget or performance figure as an assumption unless you have first-party data. Presenting a spend guess as fact is fabrication.
Is this the same as the Meta or TikTok ad libraries?
No. Meta has a full public ad library and TikTok a partial one; AppLovin is a mobile optimization network with no public archive of every active ad. You build your own evidence set by capturing creatives and context over time, instead of querying an official database. That's the core difference that shapes the entire AppLovin research workflow.
What's the difference between monetization and acquisition creatives?
Monetization (AppLovin's MAX/mediation side) is what an app shows inside itself to earn from existing users; acquisition (AXON) is what it runs across networks to win new users. They answer different questions, so don't treat the ads you see while playing a competitor's game as that game's user-acquisition strategy — those are other advertisers' monetization ads, not the game's own UA.
What signals are actually worth capturing?
Capture creative format (playable, rewarded video, vertical video, static), the first-3-second hook, the offer or CTA, the app category and apparent market, plus the source URL and date. These are observable, repeatable, and enough to build a format map and a hook list you can test against. Add a one-line "why it matters" note so the example stays reusable months later.
How do I read a playable ad I can't download?
Playables are interactive HTML5, so you usually can't save the file — record the interaction in writing instead. Note the first tap (does it get a finger on screen in 2 seconds?), the tutorial framing (real loop or simplified/fake?), the friction-to-reward ratio (taps to the satisfying payoff), and the end-card handoff to the store. That written teardown survives even though the playable itself doesn't, and it's enough to brief your own version.
How is AppLovin ad research different from Facebook ad research?
On Facebook you search a public library and can see impression ranges and longevity. On AppLovin there's no library at all, so you capture observable creatives yourself, you get no impression or date data automatically, and frequency/recency become your only soft performance signals. The discipline of capturing context and never inferring spend matters even more on AppLovin, because the platform gives you less to work with.
How often should I run AppLovin creative research?
A weekly 30–60 minute loop suits most mobile UA teams: capture new creatives, classify patterns, brief a test, and validate last week's results. High-spend studios and agencies may go twice weekly; pre-launch teams might do a focused one-time dive on 3–5 category leaders. Match the cadence to how fast you ship new creative.
Where does AdMapix fit in AppLovin research?
AdMapix fits after the official-context check and creative collection. It makes captured creatives searchable, lets you tag them by format, hook, and category, breaks down video and playable structure, and turns recurring patterns into reports across networks. It doesn't replace the official AppLovin context and doesn't provide private campaign metrics — it organizes the public creative evidence you gather into a workflow you can repeat.
Getting Started: Your First AppLovin Research Sweep
If this is your first structured AppLovin research session, here's the minimum viable version you can run today — no tooling budget required to start.
First, pick three to five category leaders in your exact genre and region. Don't boil the ocean; a tight set produces sharper patterns than a broad one. Write them down, because consistency across weeks is what builds the pattern library.
Second, gather a starting sample of creatives. Combine whatever cross-network tool you have access to with a short in-app observation session: install your competitors' apps and a couple of adjacent ones on a clean device, play until rewarded and interstitial slots serve ads, and screen-record the competitor creatives that appear. Aim for 15–20 creatives in the first sweep — enough to see a pattern, not so many you stall.
Third, tag each one with the full context — format, first-3-second hook, offer, app category, source, date, and a one-line why-it-matters note. This is the step that feels optional and isn't; an untagged creative is a memory, not evidence. Keep observation and any spend/performance guess in separate columns from the start, so the habit is baked in.
Fourth, look for one convergent pattern. Don't try to extract ten insights from your first sweep — find the single clearest thing multiple competitors are doing that you aren't. That's your first test. A format gap ("they all run playables, we run static") or a hook convergence ("six of them open on a loss-state") is enough to brief one test.
Fifth, write one brief and ship one test. Use the structure from the briefing section above — testable hypothesis, structural beats adapted to your real mechanic, pre-set metric and kill condition. One shipped, validated test from your first sweep is infinitely more valuable than a beautiful research document that never becomes a creative.
Then repeat weekly. The first sweep is the hardest because you're building the muscle and the library from scratch; by week three the loop takes under an hour and the pattern library starts doing the heavy lifting. The studios that win on AppLovin aren't the ones with the fanciest tools — they're the ones who turn this loop into a standing habit and let the compounding library out-iterate competitors whose research is occasional and unstructured.
Related Reading
- Mobile app ad spy tool — the broader cross-network app method
- Mobile game ad spy tool — the games-specific deep dive
- Best ad spy tools 2026 — the full tool landscape
- Marketing intelligence tools — the wider stack
- Paid ads competitor research — the broader competitor workflow
- How to spy on competitors' ads in 2026 — the cross-platform SOP
Sources
Official sources checked as of June 21, 2026. Mobile ad-network products, names, and documentation change over time, so verify the current official path before building a recurring workflow.
- AppLovin official site — describes AppLovin's marketing technologies for acquiring, monetizing, and measuring.
- AXON by AppLovin — describes AXON's role connecting advertisers with users across a large daily-active audience.
- How AppLovin shows ads — explains that AXON AI powers advertising recommendations by predicting likely engagement.
- AppLovin MAX (mediation) — the monetization/mediation side, distinct from user acquisition.
Bottom Line
An AppLovin ads spy tool can't hand you a competitor's campaign, because AppLovin publishes no public ad library — and any tool claiming to reveal AppLovin spend or targeting is guessing. What works is a disciplined ad-intelligence workflow: read the official scope, capture observable creatives with full context, separate what you can prove (format, hook, offer, frequency) from what you can't (spend, ROAS, targeting), and turn convergent patterns into UA test briefs your own data validates.
Score each format on its own rules, keep mediation and acquisition strictly separate, and never present an inferred budget as fact. Do that, and "AppLovin ad intelligence" becomes a repeatable creative pipeline instead of a screenshot folder — the part of UA that, on an AI-optimized network, actually decides who wins.
When scattered screenshots across networks start costing you time, start with AdMapix Search, keep examples searchable in Media, and break down structure in Video Analysis — built for exactly this job.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Ad Hook Examples in 2026: 7 First-3-Second Patterns (with UGC Breakdowns)
A complete 2026 library of ad hook examples organized into seven repeatable patterns — problem, proof, objection, comparison, curiosity, offer, and transformation — with UGC hook breakdowns, platform-by-platform differences for TikTok, Meta, and YouTube, an industry-by-industry hook map, a hook-testing workflow that ships variants, the metrics that actually grade a hook, and a worked teardown that turns a competitor opener into a running test.
Outbrain Ad Spy Tool in 2026: Native Ad Research for the Open Web
How to research Outbrain native ads from public evidence in 2026 — what a spy tool can and cannot prove, how to decode headline-and-thumbnail hooks, advertorial landing paths, retargeting trails, and how to turn patterns into testable native campaigns.

Agency Ad Intelligence Tools in 2026: Turning Competitor Research Into Client Reports
A 2026 guide to ad intelligence for agencies — how to standardize competitor research across a client portfolio, the fixed capture field list and weekly workflow that survive staff turnover, how to structure a recurring client report, white-label and deliverable considerations, using competitor research to win new business and prove retainer value, the cross-client pattern advantage only agencies have, team roles and scaling, packaging research as a billable service, and the public-data.