Twitter Ads Library in 2026: Where X Ads Live Now and What You Can Actually See
A complete 2026 guide to the Twitter Ads Library — why there is no product by that name, how the X Ads Repository works as a DSA transparency tool, exactly what it shows and hides, why access is EU-scoped, how to read funding-entity and reach data, how to research X competitors inside and outside the EU, how it compares to other ad libraries, the honest limits of public ad data, and where a cross-network creative tool like AdMapix fits.

Twitter Ads Library in 2026: Where X Ads Live Now and What You Can Actually See
By the AdMapix Research Team — Updated June 21, 2026
If you are searching for a "Twitter Ads Library," there is no product by that exact name — and there never was. Twitter rebranded to X, and the closest official equivalent is the X Ads Repository, a transparency database X publishes to comply with the EU Digital Services Act (DSA). It covers ads served in the EU and exposes the advertiser, the funding entity behind the ad, basic targeting parameters, impressions, reach, and ads that have been halted, with CSV export. That scope matters enormously: the repository is not a global ad-spy archive, and it will not show you spend, ROAS, or full account structure. Most people who type "Twitter Ads Library" into a search bar are carrying a mental model trained by Meta's Facebook Ad Library — a global, browse-everything feed — and the first job of this guide is to recalibrate that expectation to what X actually offers.
This guide is for paid-social managers, agencies, founders, and competitive researchers who still type "Twitter" out of habit but need the current X path and its real limits. We will explain why the "Twitter Ads Library" name no longer maps to a product, exactly what the X Ads Repository shows and hides, why access is EU-scoped, how to read the funding-entity and reach data the repository uniquely exposes, how to research X competitors both inside and outside the EU, how the repository compares to other platforms' libraries, and the honest line between what public ad data can and cannot prove. The aim is a clear, current, limits-aware research workflow — not a hunt for a global feed that does not exist. Get the model right, and X's transparency surface becomes a genuinely useful, even distinctive, competitive source rather than a dead end.
TL;DR — The Twitter Ads Library in One Screen
- There is no product literally named "Twitter Ads Library." Twitter is now X, and the official transparency tool is the X Ads Repository.
- The X Ads Repository covers ads served in the EU under the DSA — showing advertiser, funding entity, targeting parameters, impressions, reach, and halted ads, with CSV export.
- It is a compliance archive, not a spend tracker. It does not reveal budget, ROAS, bid strategy, or private account structure.
- Access is EU-scoped. For ads served outside the EU, the repository is a partial view, and you need direct observation plus a tool layered on top.
- The funding-entity disclosure is a distinctive signal — it names who is actually paying, which can reveal parent companies, agencies, or relationships other libraries hide.
- Reach is a visibility signal, not a financial one. High impressions do not mean high spend or proven ROAS; treat long-running creatives as hypotheses to test.
- AdMapix fits the layer after the source check — cross-network creative search, saved media, video analysis, and recurring reports when one EU-scoped repository view stops being enough.
Why the "Twitter Ads Library" Name No Longer Maps to a Product
The phrase persists because Meta's Facebook Ad Library trained a generation of marketers to expect a per-platform "ad library" link — type the platform name plus "ad library," get a global browser of every advertiser's creatives. X never shipped a feature with that name or that scope. The closest official source is the X Ads Repository, built specifically for DSA compliance, with a regional boundary baked in from the start.


A little history clarifies the confusion. If you remember an "ads.twitter.com" transparency page from years past, that lineage now lives under X. There were also older political and issue-ad archives, created during a period of heightened scrutiny around election advertising — but those were narrow in scope, tied to election-period rules, and never a general creative library. The general-purpose transparency surface that exists today is the DSA-driven repository, and it exists because EU regulation requires it, not because X built a marketing-research product.
So when a search for "Twitter Ads Library" sends you looking for a Meta-style browser, recalibrate: you are looking at a regulator-driven repository with a regional boundary, not an open global feed. Holding the right mental model from the start saves you from two predictable frustrations — hunting for a global view that does not exist, and misreading the repository's compliance-oriented data as if it were a marketing dashboard. The table below maps the expectation gap precisely.
| What you might expect | What X actually offers |
|---|---|
| A global, all-ads creative browser | A DSA repository limited to EU-served ads |
| Estimated spend per advertiser | No spend; impressions and reach bands instead |
| Full targeting breakdown | Basic targeting parameters disclosed for compliance |
| Bulk export of all creatives | CSV export of repository records |
| One-click competitor history | Manual search by advertiser, plus your own evidence capture |
| Worldwide coverage | EU-served ads only; elsewhere is a blind spot |
Reading that table top to bottom is the fastest cure for the Meta-trained expectation. Every row is a place where the "Twitter Ads Library" mental model overpromises relative to what the X Ads Repository actually delivers — and knowing the gap up front is what turns a frustrating hunt into a productive, scoped research session.
There is a deeper reason the expectation gap exists, worth understanding because it applies to every platform's transparency tool, not just X's. Ad libraries are built for one of two fundamentally different purposes, and the purpose determines the data. Meta's library leans toward a searchable transparency product — designed, in part, to be browsed and studied, which is why it surfaces impressions ranges on every ad globally and spend bands in the EU. X's repository, by contrast, is built almost purely as a regulatory compliance archive — its job is to satisfy the DSA's requirement that EU users can see who is advertising to them and how, not to be a marketing-research feed. That purpose difference is why X's repository is EU-bounded and compliance-shaped rather than global and research-shaped. Once you internalize that the repository was built to make X accountable to EU regulators rather than to make competitors legible to marketers, every one of its limits stops being surprising and starts being predictable. You are not using a broken marketing tool; you are using a well-built compliance tool for a purpose it was not designed for, which means you take the genuine facts it offers and supply the rest yourself.
What the X Ads Repository Shows (and What It Hides)
The repository is a structured record of EU-served ads, not a marketing-intelligence dashboard. The discipline that makes it useful is to use it for verifiable facts, then build inference on top of those facts carefully and honestly — never confusing what the repository proves with what you are guessing.


Per X's published transparency policy, the repository discloses the advertiser, the funding entity behind the ad, targeting parameters, impressions, reach, and whether an ad was halted. You can search it and export records as CSV. What it deliberately omits is anything that would expose a competitor's economics or private account setup — because its purpose is regulatory accountability, not competitive intelligence.
| Field | Available in repository | Not available |
|---|---|---|
| Advertiser / funding entity | Yes | — |
| Creative shown | Yes (EU-served) | Ads served only outside the EU |
| Impressions / reach | Yes (bands / counts) | Exact spend or budget |
| Targeting parameters | Basic, for compliance | Full audience model / lookalikes |
| Halted-ad status | Yes | Reason graded as performance vs. policy |
| Date / flight window | Yes | Precise daily pacing |
| CSV export | Yes | Bulk creative archive |
| Account structure | — | Campaign hierarchy, bid strategy, ROAS |
The shape of this table is the whole story: the left column is auditable fact you can put in a brief; the right column is either inference you must label as such, or data you simply cannot get from this surface. Two fields deserve special attention because they are unusual among ad libraries — the funding-entity disclosure and the impressions/reach data — and the next two sections cover each.
It is also worth noting the halted-ad field, because it is a small but genuine signal that researchers often skip. The repository shows whether an ad was halted — but, crucially, not why. A halt could mean the campaign simply ended on schedule, the advertiser paused it, or X stopped it for a policy violation. The field tells you the ad is no longer running; it does not grade the reason as performance versus policy. So a halted ad is a fact (it stopped) wrapped around an unknown (why). Read it accordingly: a creative that was halted quickly after a short run might signal a policy problem or a fast-failed test, while one halted after a long, high-reach run more likely ran its natural course. Neither reading is certain, but the halted-status field, combined with the flight window and reach, lets you form a more textured picture of a competitor's creative lifecycle than the live creatives alone — another small advantage of X's relatively data-rich repository, as long as you resist the urge to assume you know the reason behind a halt.
The X Rebrand and What Happened to Ad Transparency
To use X's ad transparency well, it helps to understand the path that got us here, because the history explains both the confusing name and the current shape of the tool. Twitter spent years as one of the more scrutinized ad platforms, particularly around political and issue advertising. During periods of heightened concern about election integrity, Twitter built and then adjusted several transparency surfaces — political ad archives, issue-ad disclosures, and an ads transparency center — that came and went as the company's policies shifted. At one point Twitter banned political advertising entirely, which changed what those archives needed to cover.
Then came the rebrand. Twitter became X, ad products were renamed and reorganized, and the URLs and product names that marketers had bookmarked changed underneath them. This churn is the practical reason "Twitter Ads Library" returns no clean product: the brand changed, the products were reshuffled, and the one durable transparency surface that remains is the one EU regulation requires — the DSA-driven X Ads Repository. Regulation, not product strategy, is what keeps it stable.
The lesson for a researcher is to expect continued change and to verify the current path every time you build a workflow. X has demonstrated a willingness to rename, reorganize, and reposition its ad products repeatedly, so a guide written even a few months ago may point to a stale URL or an outdated product name. The durable facts are these: there is no global "Twitter Ads Library," the EU-scoped X Ads Repository exists because the DSA mandates it, and the right move is always to confirm the live official path on X's own transparency pages before relying on it. Treat the specific URL as something to re-verify, and the underlying model — EU compliance archive, not global feed — as the stable truth to plan around.
The Funding-Entity Disclosure: A Distinctive Signal
One field sets the X Ads Repository apart from most other ad libraries: the funding entity. The DSA requires X to disclose not just the advertiser account running an ad, but the entity actually paying for it — and those are not always the same. That gap is where the signal lives.


Why it matters for research: the funding entity can reveal relationships the advertiser name hides. An ad running under a product brand's handle might be funded by a parent company, an agency of record, or a regional subsidiary — and seeing that funding entity tells you something about how the campaign is organized and resourced that the surface creative never would. A cluster of seemingly independent brands funded by the same entity may be a portfolio play; a brand whose ads are funded by a named agency tells you they outsource their paid social, which has implications for how quickly they iterate.
How to use it without over-reading: the funding entity is a factual disclosure, so it is reliable as far as it goes — but it does not tell you the budget that entity committed, the relationship's terms, or the strategy behind it. Treat it as a structural clue (who is really behind this, and how might that shape their campaign) rather than a financial or strategic conclusion. Logged consistently across a competitor set, funding entities can map a category's ownership and agency relationships in a way few other public sources allow — a genuinely distinctive output of X's repository that most researchers overlook because they are fixated on the creative alone.
Consider the concrete ways this disclosure changes a competitive read. If you discover that three "independent" competitors in your category are all funded by the same holding company, you have learned that your market is more consolidated than it appears — and that those three brands may coordinate creative, share an agency, or compete with shared resources rather than as true independents. If a scrappy-looking challenger turns out to be funded by a deep-pocketed parent, you should expect them to outlast a price war you might otherwise assume they cannot afford. If a competitor's ads are funded by a named performance agency rather than the brand itself, you can infer something about their iteration speed and in-house capability — agency-run paid social often moves on a different rhythm than an in-house team. None of these are certainties, but each is a structural hypothesis you could not form from the creative alone, and each can meaningfully change how you compete. The funding entity is the rare public field that speaks to organization and resourcing rather than just messaging — which is exactly why it deserves a column in your tracking sheet and a deliberate pass every time you research an X competitor.
Reading Impressions and Reach Without Mistaking Them for Spend
The other distinctive field is the impressions and reach data. Unlike some libraries that show no exposure data at all, the X Ads Repository discloses how widely an EU-served ad was seen — which is genuinely useful, and also genuinely easy to misread.


What reach and impressions legitimately tell you: how much visibility an ad achieved in the EU. A creative with high impressions reached a lot of people; one with low impressions did not. Combined with the flight window, this lets you distinguish an ad a competitor pushed hard from one that barely ran — a real, useful signal about where they concentrated their EU exposure.
What they do not tell you, and where most people go wrong: reach is not spend, and visibility is not performance. High impressions could reflect a large budget, or cheap inventory, or a broad-reach brand-awareness objective that optimizes for impressions over conversions — you cannot tell which from the number alone. And reach says nothing about whether the ad converted; a widely-seen ad can be a widely-seen failure. The cardinal error is to convert a reach figure into a spend estimate or a performance verdict. The number is exposure, full stop. Read it as "how much did they show this in the EU," pair it with the flight window for a sense of commitment, and never let it become a fabricated budget or a claimed win in your report.
Where reach genuinely earns its place is in relative comparison within a competitor set, not as an absolute figure. Comparing one competitor's reach to another's on similar creatives, in the same country and window, tells you who concentrated more EU exposure behind a given angle — a real, useful competitive signal. And tracking one competitor's reach over time tells you whether they are ramping or pulling back their EU presence. The trap is the absolute reading ("they reached two million people, so they spent X"); the value is the relative reading ("they put far more EU exposure behind the problem-callout angle than the feature angle, and more than their rival did"). Use reach comparatively and across time, anchor it to the flight window, and it becomes one of the more useful fields any EU ad library offers — just never let a relative signal harden into an absolute spend or performance claim.
What Public Data Can and Cannot Prove
Public transparency data proves existence and exposure, not performance or strategy. This distinction is the spine of honest competitor research, and it is worth stating plainly because the repository's relatively rich data tempts over-reading.


What it can prove. That a specific advertiser ran a specific creative, in the EU, with a disclosed funding entity, over a specific window, and roughly how widely it was seen. These are auditable facts you can build a brief on.
What it cannot prove. How much they paid, whether the ad converted, how their account is structured, their bid strategy, or what their targeting truly was beyond the basic disclosed parameters. None of that is exposed, by design.
The repetition trap, handled honestly. If you see a creative running for weeks, that suggests it is working — advertisers rarely keep running losers. But a long run can also reflect a slow review queue, a brand-awareness mandate that does not chase conversions, or simple neglect, not proven ROAS. Treat repeated creatives and long flight times as hypotheses to test, never as confirmed winners. The honest discipline is to grade every claim: fact ("this creative ran in the EU for six weeks with high reach, funded by entity X"), inference ("the long run suggests it works"), and hypothesis ("worth testing an adapted version"). Keep the three distinct and your competitive intelligence stays credible; blur them and you are presenting guesses as findings.
This grading discipline matters even more on X than on some platforms, precisely because the repository gives you more data than a thinner library — and more data tempts more over-reading. When a library shows you only the creative, you are unlikely to fabricate a spend number; there is nothing to anchor the fantasy to. But when a library hands you real reach figures and a funding entity, the temptation to spin those into a budget estimate or a strategic verdict is strong, and the resulting claim sounds authoritative because it is built on real numbers. That is exactly the trap: a confident-sounding spend figure derived from a reach number is still a fabrication, just a better-disguised one. The defense is to let each field do only the job it can: reach proves visibility, funding entity proves who paid, flight window proves duration — and none of them, alone or combined, proves spend, conversion, or strategy. The richer the data, the more disciplined the labeling has to be, because the cost of a polished-but-false claim in a competitive report is your own credibility the moment someone checks it.
How to Research X Competitors With the Repository
Start from the official source, define a tight competitor set, capture evidence consistently, then convert observations into a test — not a conclusion. Here is a workflow that produces reusable research rather than a folder of screenshots.


- Confirm the source and its scope. Open the X Ads Repository and accept up front that you are seeing EU-served ads only. If your market is the US or APAC, the repository is a partial view, and you will need observation outside it.
- Define the competitor set. Lock the advertiser group, country, category, and a date window before you start, so you are comparing like with like rather than chasing whatever surfaces.
- Capture evidence the same way every time. For each ad save: source URL, capture date, advertiser and funding entity, country, format, the creative hook or CTA, a reach/impression note, the flight window, and one line on why it matters.
- Mine the funding entities. Across your set, note which entities fund which advertisers — the ownership and agency map that emerges is one of the repository's most distinctive outputs.
- Separate observation from inference. Visible reach can support a "this angle is getting volume" hypothesis; it cannot support a spend or ROAS claim. Label each accordingly.
- Turn findings into a test. Convert the evidence into a creative hypothesis, a hook list, a landing-page note, or a recurring competitor brief — a decision, not a conclusion presented as fact.
The discipline lives in steps three through six: consistent capture, the funding-entity map, honest labeling, and a shipped output every time. Do that across a quarter and you build a longitudinal read of how a category's X advertising evolves — something no single repository search can give you.
Researching X Competitors Outside the EU
Because the repository is EU-scoped, a large share of competitive activity — US, UK, APAC, and beyond — sits in a blind spot, and you need other legitimate methods to research it. This is where the practical work for most non-EU advertisers actually lives.

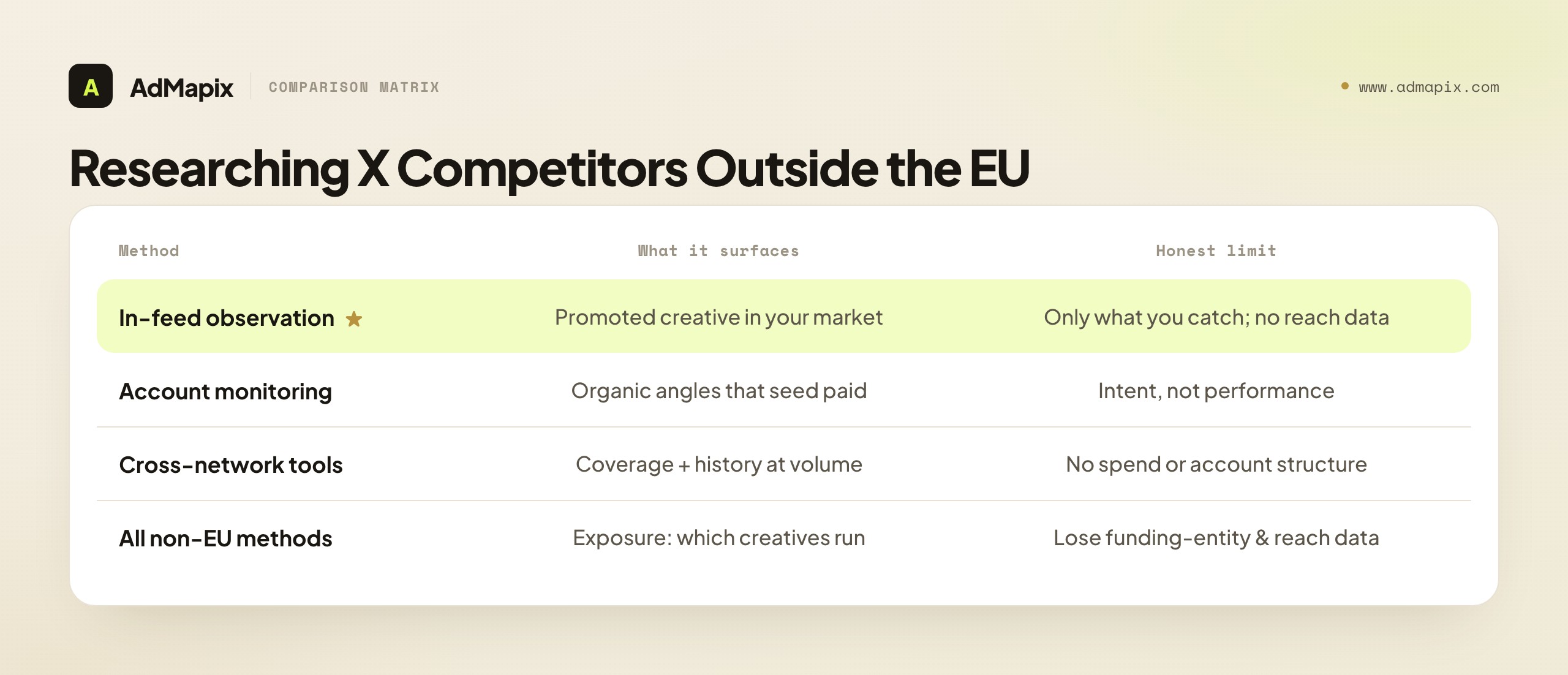
Direct in-platform observation. Promoted posts and ads are labeled in the X feed and search. Browsing the topics and following the accounts your buyers do surfaces the promoted creative competitors are actively running in your market. Log the advertiser, the creative, the context where it appeared, and the date — building your own evidence record where the repository has none. Do this from a clean or research-focused account that mirrors your buyer's interests rather than your own, because X personalizes the feed and ads heavily; researching from your own trained account shows you the ads X thinks you want, not a representative sample of what competitors run to your buyers.
Account and post monitoring. A competitor's own X presence often seeds or overlaps their paid creative. Watching their organic posting tells you which angles they believe in, which complements the promoted creative you catch in-feed.
Cross-network ad-intelligence tools. Tools that catalog promoted creative across networks and regions give you coverage the EU-only repository lacks, plus history and search at volume. They are the scalable path once manual in-feed observation stops keeping up.
The honest limit on every non-EU method. None of these reveals spend, ROAS, targeting, or account structure — the same boundary that applies to the repository applies to every observation method. What they reveal is exposure: which creatives a competitor runs and how persistently. For non-EU research you also lose the repository's funding-entity disclosure and its reach data, so your view is creative-only and your confidence should be correspondingly lower. State that limitation in any non-EU competitor report rather than implying the same rigor you get from the EU repository.
There is a clever partial workaround worth knowing for global brands: a competitor that advertises in both the EU and your non-EU market often runs related creative across regions. So even when you cannot see their US ads in the repository, their EU ads — which you can see, with funding entity and reach — frequently rhyme with what they run elsewhere, because brands rarely invent a wholly separate creative strategy per region. The EU repository thus becomes a lens onto a global advertiser's creative thinking, not just their EU activity: read their EU angles, funding structure, and reach, and you have a reasonable basis for inferring the shape (though not the specifics) of their broader strategy. This is inference, not observation, so grade it as such — "their EU creative suggests a problem-led global positioning" is a hypothesis, not a fact about their US campaigns. But for a global competitor, the EU window is more useful than its regional boundary first implies, precisely because creative strategy tends to travel across the borders the repository does not.
A Worked Example: Researching One X Advertiser
Principles land harder applied, so here is a composite walkthrough of researching one competitor — a mid-market SaaS brand, call it "Rival Co" — that advertises on X and serves the EU, so the repository covers them.
Confirm scope and find them. You open the X Ads Repository, search Rival Co, and confirm you are seeing their EU-served ads. You note immediately that this is the EU slice only — Rival Co also runs heavily in the US, which the repository will not show, so you flag that this view is partial.
Read the funding entity first. Before the creatives, you check who funds the ads — and here the repository earns its keep. Rival Co's ads are funded not by Rival Co directly but by a named parent holding company you had not connected to them. That single disclosure reframes your competitive picture: Rival Co is part of a larger portfolio, which suggests deeper resources and possibly shared creative or agency relationships with sibling brands. You log the funding entity and make a note to check whether other brands in your category share it.
Read the creatives and reach. You work through the EU creatives, capturing each one's hook, format, flight window, and reach. Two patterns emerge: a problem-callout angle running with high reach across a long window, and a newer feature-led angle with lower reach that just launched. The high-reach, long-running creative is your highest-priority study target — but you label it carefully: high EU reach plus a long run suggests it is working, it does not prove a budget or a conversion rate.
Separate fact from inference. Your notes distinguish three grades cleanly. Fact: Rival Co ran a problem-callout creative in the EU for eight weeks with high reach, funded by parent entity X. Inference: the long run and high reach suggest it is a winner worth emulating. Hypothesis: a problem-callout angle adapted to our ICP will beat our current feature-led creative. None of it claims a spend figure or a ROAS, because the repository cannot supply those.
Ship one output. You write a one-paragraph brief: "Rival Co is parent-funded (portfolio play), leads in the EU with a high-reach problem-callout angle running 8+ weeks, and is testing a newer feature-led angle. Hypothesis: test a problem-callout creative for our own ICP against our current feature-led control; separately, audit whether sibling portfolio brands share the funding entity and creative." That brief — built from the repository's funding-entity and reach data, every claim graded — is real competitive intelligence, not a screenshot pile, and none of it required a number X hides. Notice how much of the value came from the funding entity, a field most researchers never look at: the single most strategically useful thing you learned about Rival Co was not in their creative at all, but in who pays for it.
Building X Research Into a Weekly Workflow
A one-time repository search is competitive guessing; a standing weekly loop is competitive intelligence. Here is a rhythm a paid-social team can run, blending the EU repository with in-feed observation for non-EU coverage.
- Pick one narrow question. Not "what is everyone doing on X," but "which angle are my top five rivals leading with in the EU this month, and who funds them." A scoped question is answerable in a session.
- Sweep the repository for your EU set. Search each competitor, note new creatives, reach shifts, new funding entities, and halted ads. Log only what changed week over week — you are tracking deltas, not re-inventorying.
- Catch non-EU activity in-feed. For competitors who run outside the EU, browse your buyers' topics and the rivals' accounts to catch promoted creative the repository misses, logging it with lower confidence.
- Update the funding-entity map. Maintain a running map of which entities fund which advertisers across your category — over weeks this becomes a genuine ownership-and-agency picture.
- Grade and ship. Label each finding fact/inference/hypothesis, and end with one output: a hook to test, a brief, or a watchlist update.
Run that loop weekly and the value compounds. You build a longitudinal read of how a category's X advertising evolves, a funding-entity map few competitors bother to assemble, and a steady stream of graded, testable hypotheses — all from a free EU repository plus disciplined in-feed observation. The discipline, as always, is the weekly cadence and the honest grading: deltas over snapshots, hypotheses over conclusions.
A note on how X's cadence compares to other platforms, because it shapes how often you really need to look. X advertising, especially in B2B and brand categories, tends to evolve more slowly than the daily creative churn of TikTok or Meta performance campaigns — so a weekly repository sweep is comfortably enough to catch every meaningful change, and you are not racing a fatigue clock. Use the CSV export to make each weekly sweep fast: pull the records, diff them against last week's, and you spot new creatives, reach shifts, and new funding entities in minutes rather than clicking through every ad. That export-and-diff habit is what makes the weekly loop sustainable past the second week — the friction that kills most research cadences is the manual re-inventory, and the CSV removes it. Pair the slower X cadence with the export efficiency, and a thorough weekly X competitive sweep can take a fraction of the time the same depth would demand on a faster-moving, no-export platform.
How the X Ads Repository Compares to Other Libraries
A researcher working across platforms should know how X's repository stacks up against the other major transparency surfaces — because the differences tell you which platform to lean on for which question.

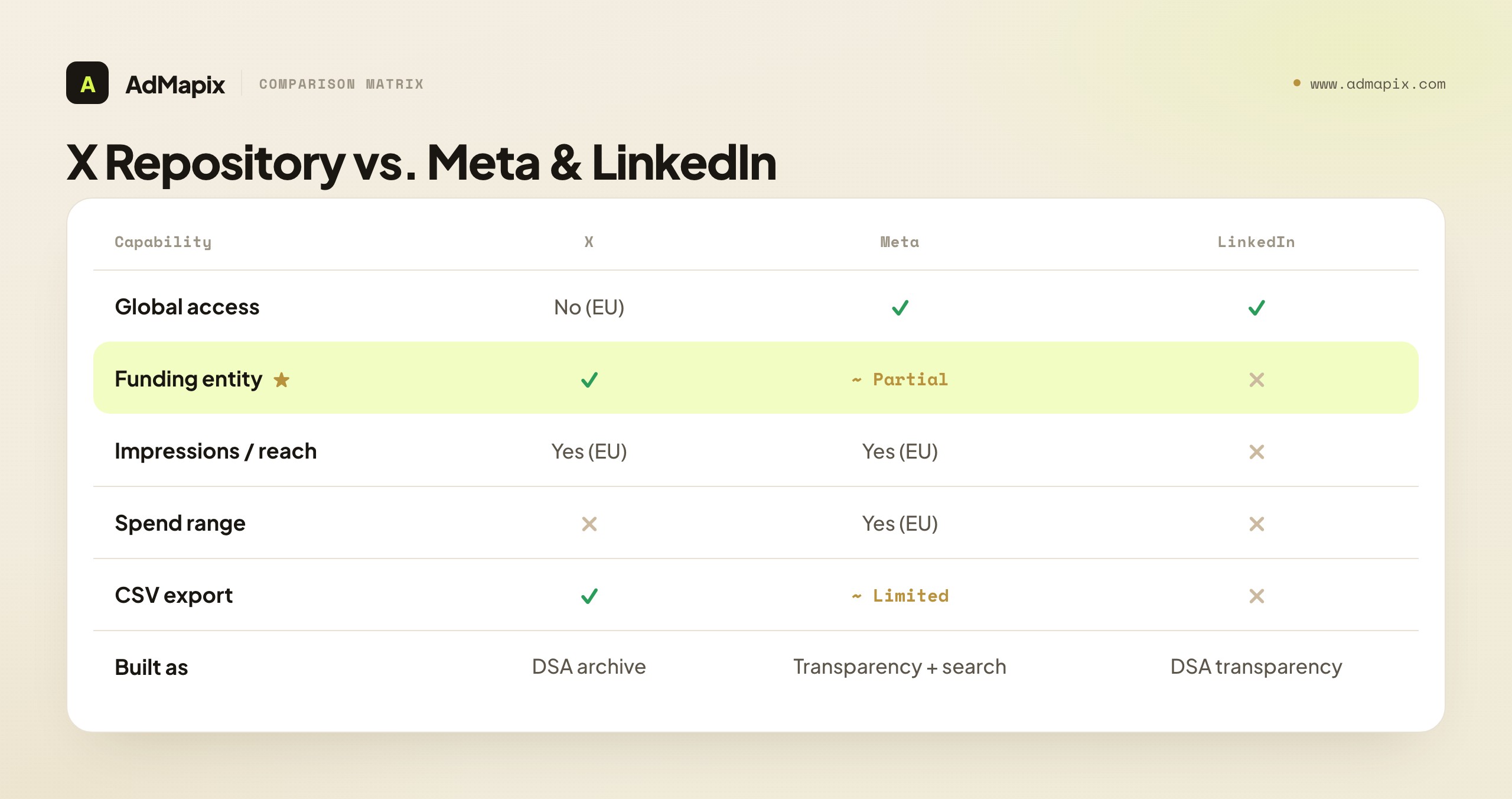
| Capability | X Ads Repository | Meta Ad Library | LinkedIn Ads Library |
|---|---|---|---|
| Global access | No (EU-served) | Yes | Yes (no spend) |
| Creative & advertiser | Yes | Yes | Yes |
| Funding entity | Yes (distinctive) | Partial | No |
| Impressions / reach | Yes (EU) | Yes (EU ranges) | No |
| Spend range | No | Yes (EU only) | No |
| Targeting disclosure | Basic (EU) | Broad (EU) | Broad (EU) |
| CSV / data export | Yes | Limited | No |
| Built as | DSA compliance archive | Transparency + search | DSA-driven transparency |
The summary: X's repository is EU-scoped like LinkedIn's and Pinterest's, but exposes more structured data within that scope — funding entity, reach, and CSV export are real advantages over LinkedIn's thinner surface, though it lacks Meta's global reach and spend bands. The practical reading: use Meta's library when you need global coverage and a spend proxy, use X's repository when you need EU funding-entity and reach data on a competitor (and value the CSV export for analysis at volume), and accept that for non-EU X activity you are back to in-feed observation. No single library wins everywhere; match the surface to the question and the region.
The CSV export deserves a specific note, because it is an underused advantage. Most ad libraries force you to capture evidence by hand — screenshot, paste, transcribe — which caps how much you can analyze. The X repository's CSV export lets you pull structured records and analyze them at volume: sort by reach, group by funding entity, filter by date, and spot patterns across dozens of ads that you would never see clicking through one at a time. For a researcher willing to work in a spreadsheet, this turns the repository from a browse-one-ad-at-a-time tool into a small dataset you can actually query. Want to know which funding entity backs the most high-reach creatives in your category, or how a competitor's EU reach trended across a quarter? The CSV makes that a sort-and-filter operation rather than a manual tally. It is the kind of capability that rewards the disciplined analyst and goes completely unused by the casual screenshotter — and it is a concrete reason to prefer the official repository over eyeballing the feed when your competitors do serve the EU.
Common Mistakes With the Twitter/X Ads Library
The failure modes are predictable, which makes them avoidable. Naming them is the cheapest insurance against a misread.


- Expecting a Meta-style global library. The X Ads Repository is EU-scoped under the DSA; do not treat it as worldwide coverage, and do not assume a competitor's absence means they do not advertise.
- Reading reach as spend. High impressions are not a budget figure and say nothing about return on ad spend. Reach is exposure, full stop.
- Ignoring the country boundary. Results shift by country and date; an EU-only view will miss campaigns served elsewhere entirely.
- Overlooking the funding entity. The funding-entity disclosure is one of the repository's most distinctive signals, and most researchers ignore it in favor of the creative — leaving real ownership intelligence on the table.
- Treating long-running creatives as proven winners. Flight time is a signal, not a verdict — confirm with your own tests.
- Searching "Twitter Ads Library" and giving up when no product appears. The product exists under a different name and model — the X Ads Repository — so recalibrate rather than concluding X has no transparency at all.
- Skipping documentation. Screenshots scattered in chat are not research; save URL, date, scope, funding entity, and rationale so the finding is reusable later.
When to Use AdMapix
AdMapix is for the layer that begins after the official source check — when one EU-scoped repository view and a folder of screenshots stop being enough. It is built for paid-social teams, agencies, and founders who need cross-network ad creative search, saved media, video analysis, tagging, and recurring reports across more than one platform and region.


It directly fills the gaps the EU-scoped repository leaves: coverage beyond the EU (so non-EU X activity, and other networks entirely, are in view), cross-network consolidation (X alongside Meta, LinkedIn, TikTok, and more in one workspace), video breakdown (so the hook and pacing of a video ad are captured, not just a thumbnail), and saved, taggable, reportable evidence (so research compounds instead of rotting in a screenshot folder). Use Search AdMapix to widen discovery beyond a single repository, Media to store creative evidence with context, Video Analysis to break down hooks and pacing in video ads, and Reports to turn scattered notes into a repeatable deliverable. Compare workflow access on Pricing, and create an account from Login when manual screenshotting starts costing more time than it saves.
It is explicitly not the right tool if your only need is verifying one advertiser's EU-served ads for a compliance or legal check — for that, the official X Ads Repository alone is the correct and sufficient source, and AdMapix does not replace it. And like every honest public tool, AdMapix does not expose competitor spend, ROAS, or account structure that no external source can see; its value is cross-network coverage, history, video breakdown, and workflow, not private data. The repository is the official, regional source of record; AdMapix is the broader research layer you add when one region's compliance archive stops covering your real competitive need.
The pairing works because the two tools answer different questions cleanly. The X Ads Repository answers "for this advertiser's EU ads, who funded them, how widely were they seen, and are they still running" — authoritative, official, EU-bounded facts. A cross-network tool answers "across X and every other network my competitor uses, in every region, what creative are they running and how is it built" — broader, deeper on creative, but without the repository's official funding-entity and reach disclosures. Used together, you get the best of both: the repository's authoritative EU facts as your anchor, and the cross-network layer's breadth and creative depth for everything the repository cannot reach. The mistake is treating them as competitors — the repository as a worse version of a spy tool, or a spy tool as a replacement for official compliance data. They are complements, and a mature X research practice uses the official source for what it authoritatively proves and a broader tool for everything beyond its regional and creative-workflow limits.
Putting It Together: Recalibrate, Then Research
The whole guide reduces to one move made before you search: recalibrate the expectation. There is no "Twitter Ads Library"; there is the X Ads Repository, an EU-scoped DSA compliance archive that exposes advertiser, funding entity, reach, targeting parameters, and halted status, with CSV export — and nothing about spend, ROAS, or account structure. Hold that model and the repository becomes a genuinely useful tool used within its limits; expect a global Meta-style feed and you will only be frustrated.
From there the workflow is straightforward: confirm the EU scope, define a tight competitor set, capture evidence consistently, mine the distinctive funding-entity and reach data, label every claim by its evidence grade, and turn findings into tests rather than conclusions. For non-EU activity, fall back to in-feed observation and a cross-network tool, and lower your confidence to match the thinner data. Do that, and you extract real, honest competitive signal from X — the funding-entity map and EU reach data that few researchers bother to read — instead of giving up because the famous "ads library" name returns no product. The name is legacy; the research is very much alive, if you know where it actually lives.
FAQ
Is there still a Twitter Ads Library?
No. Twitter rebranded to X, and there was never a feature literally named "Twitter Ads Library." The closest official source is the X Ads Repository, a DSA-compliance database covering ads served in the EU. Outside the EU, X does not publish a comparable open creative archive, so for non-EU markets you rely on in-feed observation and third-party tools.
What does the X Ads Repository actually show?
It shows the advertiser, the funding entity behind the ad, basic targeting parameters, impressions, reach, the flight window, and whether an ad was halted, for ads served in the EU. You can search it and export records as CSV. It does not show spend, ROAS, bid strategy, or full account structure — it is a compliance archive, not a marketing dashboard.
Is the X Ads Repository free, and do I need an account?
The X Ads Repository is a public transparency surface published for DSA compliance, so it is accessible as an official source of record. Always confirm the current access path on X's official transparency pages, since X has changed naming and product paths repeatedly since the rebrand — verify before building a workflow on it.
Can I see how much a competitor spent on X ads?
No. The repository discloses impressions and reach, not budget. Any spend figure you see elsewhere is a third-party estimate, not an official number. Treat reach as a visibility signal — how widely an ad was seen in the EU — not a financial one, and never convert a reach figure into a spend claim in a report.
What is the funding entity, and why does it matter?
The funding entity is the party actually paying for an ad, which the DSA requires X to disclose and which is not always the same as the advertiser account. It can reveal parent companies, agencies of record, or regional subsidiaries behind a brand's ads — a distinctive ownership signal most other libraries do not expose. Logged across a competitor set, funding entities map a category's ownership and agency relationships.
How do I research X competitors outside the EU?
The repository will not cover them, so you rely on direct in-feed observation plus a tool that captures and organizes what you see. Save the creative, date, format, context, and hook, then compare patterns across advertisers rather than guessing at hidden metrics. Note that outside the EU you lose the funding-entity and reach data, so your view is creative-only and your confidence should be lower.
How does the X Ads Repository compare to the Meta Ad Library?
Meta's library is global and adds EU spend bands; X's repository is EU-scoped but exposes the funding entity and reach with CSV export, which Meta does not surface the same way. Use Meta's for global coverage and a spend proxy, and X's repository for EU funding-entity and reach data on a competitor. Neither shows true spend, ROAS, or account structure.
Does a long-running X ad mean it is working?
Not necessarily. A long flight time suggests an ad is performing — advertisers rarely keep running losers — but it can also reflect a slow review queue, a brand-awareness mandate that does not chase conversions, or neglect. Treat repeated creatives and long runs as hypotheses to test against your own account, never as confirmed winners, and label them as inferences in any report.
What should I capture from each X ad I research?
Capture the advertiser and funding entity, the creative and its hook or CTA, the format, the country, the reach/impression note, the flight window, the source URL, and the capture date — plus one line on why it matters. Provenance and the funding entity are what make an example comparable next month and defensible in a brief. Tag consistently so a folder becomes a sortable dataset.
Where does AdMapix fit relative to the official source?
AdMapix sits after the source check. Once you have confirmed what the X Ads Repository shows for EU ads, AdMapix helps you search creatives across networks and regions, save and tag examples, analyze video ads, and turn the evidence into recurring reports — work the EU-scoped compliance repository was never designed to do. It does not replace the repository for a single-advertiser EU compliance check, and it does not expose private spend or account data.
Key Takeaways
- Search "X Ads Repository," not "Twitter Ads Library" — the latter is a legacy phrase with no matching product.
- Treat the repository as EU-scoped compliance data: trustworthy for advertiser, funding entity, creative, reach, and halted status; silent on spend and ROAS.
- Mine the distinctive funding-entity disclosure to map a category's ownership and agency relationships — a signal most researchers overlook.
- Read reach as visibility, not spend, and convert long-running or repeated creatives into hypotheses to test, never assumed winners.
- For non-EU activity, fall back to in-feed observation and a cross-network tool, lower your confidence to match, and layer a search-save-report workflow on top only when one regional repository stops covering your real research need.
Related Reading
- Facebook Ads Library 2026: Official URL, Filters & Competitor Ads Guide — the deep dive for Meta's global, spend-rich transparency library.
- LinkedIn Ads Library in 2026: How to Find Competitor Ads and What It Shows — the B2B counterpart, another EU-scoped surface with the same transparency-vs-performance boundary.
- Pinterest Ads Library in 2026: The Ads Repository, Its Limits, and How to Research Promoted Pins — another DSA repository with region-locked access.
- Ad Spy Tools by Channel: Meta, TikTok, Google, YouTube, Native — how the transparency surfaces and tools compare across platforms.
- How to Spy on Competitors' Ads in 2026 (30-Min/Week Workflow) — the cross-channel weekly workflow X research plugs into.
Sources
Official sources checked as of June 21, 2026. X naming, repository scope, and disclosed fields can change, so verify the current official path before relying on any workflow.
- X Ads transparency policy — X states that its DSA Ads Transparency Center is the X Ads Repository for ads served in the EU, including advertiser, funding entity, targeting parameters, impressions, reach, and halted ads.
- X Ads Repository — the official search and CSV-export entry point for repository research.
- X Business advertising — the official entry point for X ad formats, campaign goals, and setup.
- EU Digital Services Act overview — the regulation behind the X Ads Repository and its EU scope.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Ad Hook Examples in 2026: 7 First-3-Second Patterns (with UGC Breakdowns)
A complete 2026 library of ad hook examples organized into seven repeatable patterns — problem, proof, objection, comparison, curiosity, offer, and transformation — with UGC hook breakdowns, platform-by-platform differences for TikTok, Meta, and YouTube, an industry-by-industry hook map, a hook-testing workflow that ships variants, the metrics that actually grade a hook, and a worked teardown that turns a competitor opener into a running test.

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.
Outbrain Ad Spy Tool in 2026: Native Ad Research for the Open Web
How to research Outbrain native ads from public evidence in 2026 — what a spy tool can and cannot prove, how to decode headline-and-thumbnail hooks, advertorial landing paths, retargeting trails, and how to turn patterns into testable native campaigns.