Atria vs Foreplay: Which Creative Workflow Fits Your Team in 2026?
A workflow-first comparison of Atria and Foreplay. Atria centers on AI-assisted concept and script ideation; Foreplay centers on the swipe file — saving, tagging, sharing, and presenting ad references. Name your slowest weekly task, pick the tool that fits, and see where a discovery-and-evidence layer like AdMapix fits alongside either.
Atria vs Foreplay: Which Creative Workflow Fits Your Team in 2026?
Updated June 21, 2026.
Atria and Foreplay both live in the creative-research stage of paid social, but they solve different bottlenecks. Atria positions itself as an AI ad workflow platform built around concept and script generation. Foreplay is built around the swipe file — saving, tagging, sharing, and presenting ad references so they do not rot into dead links. If you are a creative strategist, an ecommerce operator, an agency, or a paid-social team, the right pick is decided by which weekly task slows you down most: producing ideas, or organizing and presenting references. This guide makes that call and shows where a discovery-and-evidence layer fits alongside either tool. AdMapix is our product; we include it where it genuinely fits and keep product claims separate from what public ad data can prove.
TL;DR
- Pick Foreplay when the daily job is saving, organizing, sharing, and presenting ad references for a team or client — the swipe-file workflow, with durable links and client-facing boards.
- Pick Atria when AI-assisted concepting and script ideation are closer to your real bottleneck than reference collection. Its center of gravity is generating the next concept, not storing the last one.
- The two jobs sit at opposite ends of one pipeline: idea generation is the upstream end (what should we make next?); reference management is the connective tissue (what have we seen, and can we present it?). A tool great at one is not automatically good at the other.
- Neither is a measurement tool. Keep your ad account and product analytics as the source of truth for what actually performed — both work with reference and public signals, not your metered results.
- Compare official feature and pricing pages before you commit. Both products iterate and plan names change; verify the current plan on each vendor's own pages.
- Use AdMapix beside either tool when you need cross-network competitor search, video breakdowns, and shareable reports that go past your saved boards.

What Each Tool Is Built Around
The fastest way to choose is to name the center of gravity of each product. Atria centers on AI ideation: it markets itself as an ad workflow platform that helps teams generate concepts, angles, and scripts faster. Foreplay centers on the swipe file: a persistent, taggable, shareable library of saved ads with boards and comments, built so references stay accessible and links do not expire.
That difference matters because the two jobs sit at opposite ends of the same pipeline. Idea generation is upstream — what should we make? Reference management is the connective tissue — what have we seen, and can we present it? A tool that is excellent at one is not automatically good at the other, so buying on "feature count" misses the point entirely. The feature lists will overlap; the centers of gravity will not. Your job is to find which center of gravity matches the task that actually slows your week.
| Dimension | Atria | Foreplay |
|---|---|---|
| Primary job | AI-assisted ad ideation and workflow | Saving, organizing, sharing, presenting references |
| Strongest for | Concepts, angles, scripts | Swipe files, boards, tags, client-facing decks |
| Reference library | Evaluate how it captures and reuses examples | Persistent swipe file with comments and sharing |
| Competitor context | Judge by how it turns context into new concepts | Includes competitor/brand tracking into boards |
| Link durability | Verify on the product page | Designed to prevent expired/dead ad links |
| Pricing | Plan comparison on its pricing page | Plan comparison on its site |
All feature and pricing specifics above should be confirmed on each vendor's own pages (linked in Sources) because they change without notice. Read the table as a map of leanings, not a scoreboard — the point is not which tool has more rows, but which tool's primary job matches the task you repeat most. If you spend more weekly time staring at a blank concept doc, Atria's column describes your need. If you spend more weekly time hunting for a reference you saved somewhere and could not find, or rebuilding a board for a client, Foreplay's column does.
One row deserves special attention: link durability. It sounds minor until you have lost a swipe file to a wall of expired ad links the week before a client presentation. A persistent swipe file that keeps references alive is a real operational advantage for teams whose work depends on showing examples, and it is a genuine differentiator of the swipe-file category over ad-hoc screenshot folders. If your references keep dying, that is a Foreplay-shaped problem, and no amount of AI ideation fixes it.
It is worth understanding why these two tools get compared at all, given how different their jobs are, because the answer reveals the trap. They get compared because both are sold as "creative tools for paid social," and a buyer who knows they need something in the creative-research stage sees both names and assumes they are substitutes. They are not substitutes; they are complements that happen to share a category label. The closest analogy is comparing a word processor to a filing cabinet because both are "office tools" — both are useful, most teams want both eventually, but they do entirely different things, and which one you buy first depends entirely on whether your current pain is producing documents or losing them. Atria is the word processor of this analogy (it helps you produce the new thing); Foreplay is the filing cabinet (it keeps and presents what you have). Holding that distinction makes the rest of the decision straightforward.
There is also a sequencing reality worth naming. In a mature creative operation, the natural flow is: discover what is out there, save the best of it (swipe file), ideate from it (concept tool), then test. Foreplay and Atria occupy adjacent links in that chain — save, then ideate — which is exactly why they feel comparable and yet are not interchangeable. If your chain breaks at "save and present," Foreplay is the fix; if it breaks at "ideate from what we saved," Atria is the fix. A team can genuinely need both over time, but at any given moment one link is the binding constraint, and that link is the one to spend on first.
How to Decide Between Them
Decide by naming your bottleneck first, then matching the tool to it — not the other way around. Most teams can tell within a week which of these two statements is more true: "we struggle to come up with the next concept," or "we struggle to keep, organize, and show the references we already have." The first points to Atria; the second points to Foreplay. That single sentence is most of the decision, and it is worth being honest about which one describes your actual Tuesday rather than the one that sounds more sophisticated.
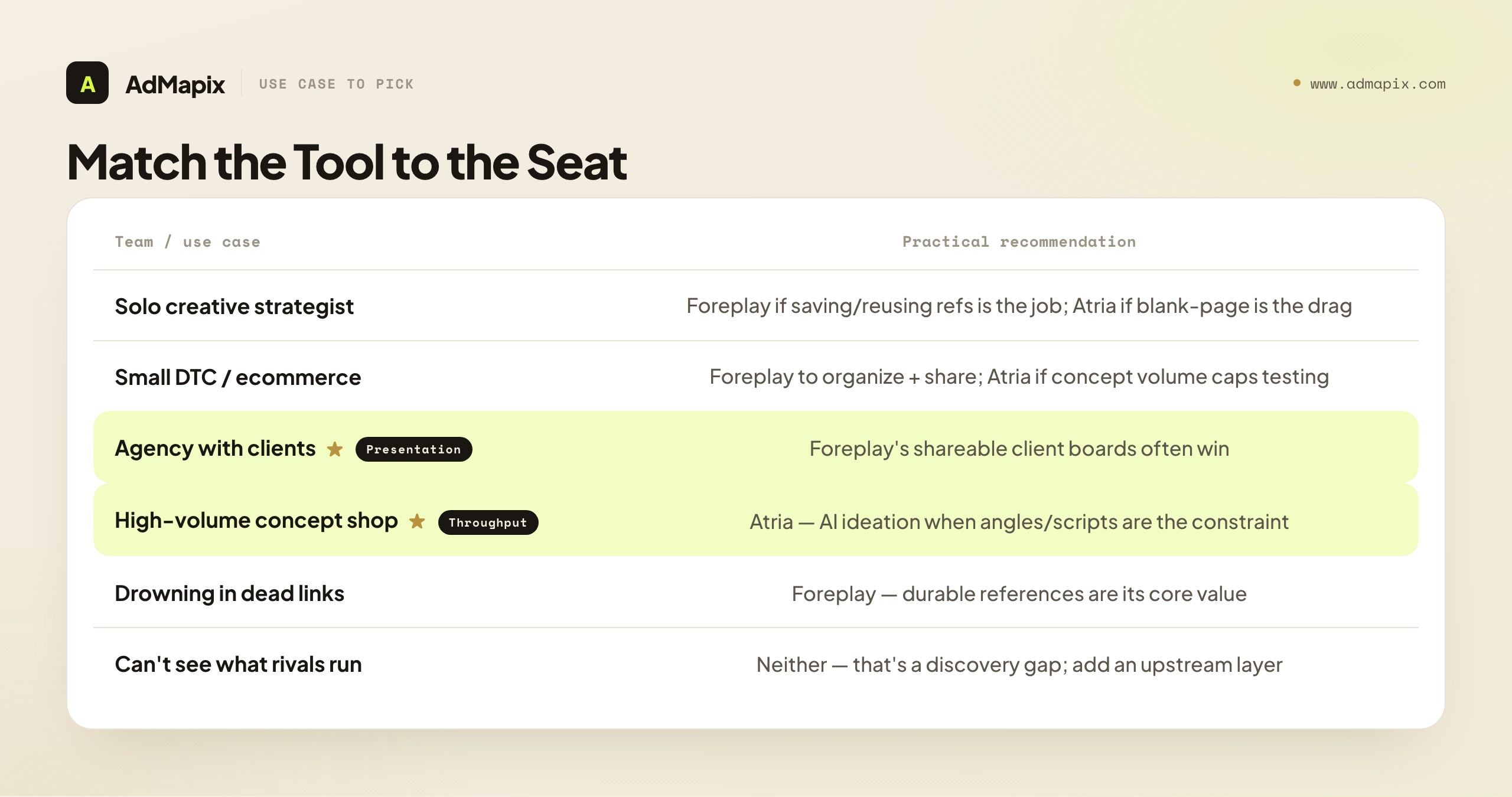
| Team or use case | Practical recommendation |
|---|---|
| Solo creative strategist | Foreplay-style swipe files are usually faster if the core job is saving and reusing references; lean Atria if blank-page concepting is the real drag |
| Small DTC / ecommerce team | Foreplay if the bottleneck is organizing and sharing references across the team; Atria if concept volume is the constraint on testing |
| Agency with clients | Foreplay's shareable, client-facing boards often win; pair with ideation when concept throughput is the limit |
| High-volume concept shop | Atria's AI ideation pays off when the binding constraint is producing the next batch of angles and scripts |
| Team drowning in dead links | Foreplay — durable, persistent references are its core value |
| Team that can't see what rivals run | Neither — that is a discovery gap; add an upstream cross-network layer |
The pattern across these rows is the same: match the tool to the seat's actual weekly task. Notice the last row, because it is the one teams most often misdiagnose. If your truest statement is neither "we can't ideate" nor "we can't organize references" but "we can't even see what competitors are running across our networks," then neither Atria nor Foreplay is your answer — you have a discovery problem, and that is upstream of both ideation and reference management. Buying a swipe file or an ideation tool on top of a discovery gap just lets you organize or ideate faster from an incomplete picture, which can be a false comfort: faster motion on the wrong inputs feels productive while quietly entrenching a blind spot. The rows above are only meaningful once discovery is solved; if it is not, that is the first row to act on, regardless of which downstream tool looks more appealing.
It also helps to be honest about how these tools fail when mismatched. Give an ideation-bottlenecked team a beautiful swipe file and they will have a gorgeous, well-tagged library and still stare at a blank concept doc, because organizing references was never their constraint. Give a reference-bottlenecked team an AI ideation tool and they will generate plenty of angles but still lose the references they meant to show the client, because generating concepts was never their constraint. The mismatch is not subtle once it happens; the trick is to avoid it by diagnosing honestly before you buy.
A quick diagnostic that cuts through the fog: for one week, notice which moment you actually dread. Is it the moment you open a blank doc and have to invent the next angle? Or is it the moment you go looking for that great ad you saw last Tuesday and cannot find it, or you sit down to build a board for a client and half your saved links are dead? The dread is diagnostic, because people remember and avoid their real bottleneck. If the blank doc is the dread, you are an Atria team. If the lost reference is the dread, you are a Foreplay team. Most people know the answer instantly once they ask the question in those concrete terms, rather than in the abstract "which tool is better."
The seat also predicts the answer. A copywriter or concept lead whose output is the next angle tends to feel the ideation bottleneck. A creative producer, an account manager, or anyone whose job is to assemble and present what the team has gathered tends to feel the reference bottleneck. When two people on the same team disagree about which tool to buy, they are often both right about their own seat — and the resolution is to decide whose workflow is the actual constraint on the team's output right now, then buy for that seat first and the other later.
Atria's Strength: Generating the Next Concept
Atria's reason to exist is the upstream end of the pipeline — the moment you need the next concept, angle, or script and do not yet have it. When the slowest, most draining part of your week is producing ideas rather than organizing them, an AI-assisted ideation tool is built to compress that. Atria pairs ad context with AI to help you move from "we need angles" to a set of drafted concepts and scripts you can react to, faster than starting from a blank page.

The teams that benefit most are the ones whose binding constraint is concept throughput — high-volume concept shops, solo strategists feeding more spend than one brain can ideate for, and any team where the number of distinct angles they can produce per week limits how fast they can test and learn. For them, compressing the blank-page step is a direct lever on test velocity, and test velocity is a direct lever on learning. The psychological mechanism is real: starting from nothing is cognitively expensive, while reacting to a draft is cheap, and most strategists edit far faster than they originate. An ideation tool converts a generation problem into an editing problem, which is usually the faster problem.
The qualifier worth stressing is "responsibly." Faster ideation only compounds into faster learning if your testing capacity and your judgment keep pace. A solo strategist who can now generate forty concepts a week but can only test four has not removed their real bottleneck — they have moved it from ideation to selection, and the new constraint is "which four of these forty deserve the slots." So the honest case for an ideation tool is not "produce more"; it is "spend less time getting to the same number of good concepts, and reinvest that saved time in selection and iteration." Read that way, Atria's value is time returned to the strategist, which they then spend on the judgment the AI cannot provide. Teams that understand this get leverage; teams that expect the tool to replace judgment rather than free up time for it end up with a faster path to mediocre creative — the tool is a lever, and a lever multiplies whatever force you apply, including a weak one.
But Atria's value carries a hard dependency that is easy to miss: AI ideation is only as good as the context and constraints you feed it. An ideation tool fed thin or generic input produces thin, generic concepts, because a model with weak input returns the bland statistical center of what it has seen. The way to pull the output toward something briefable is to feed it strong, recent, category-relevant reference creative plus explicit constraints about your brand, offer, and audience. This is exactly why a discovery layer and even a good swipe file matter for an ideation-led team — the richer and more relevant your reference base, the better the concepts the AI drafts from it. We dig into getting useful output rather than confident filler in our AI ad creative tools guide.
The discipline to carry into Atria, or any AI ideation tool, is to treat its output as a starting point for a human brief, never as proof. The AI can cluster patterns and accelerate your first draft; it cannot tell you what will convert your audience. And beware the volume trap: because an ideation tool makes it easy to produce many concepts, it is tempting to equate volume with progress, but ten generic angles are worse than two sharp ones, because they consume production and testing capacity without teaching you anything. Keep a human editor between the AI and the test queue — the AI proposes, a strategist selects and sharpens, and only the survivors get built.
Foreplay's Strength: Keeping and Presenting References
Foreplay's reason to exist is the connective tissue of the pipeline — the swipe file. When the slowest, most annoying part of your week is saving, tagging, finding, and presenting the references you have already gathered, a swipe-file-first tool is built for exactly that. Foreplay gives you a persistent, taggable, shareable library with boards and comments, engineered so references stay accessible and links do not expire into the dead-link graveyard that ad-hoc screenshot folders become.

The teams that benefit most are the ones whose work depends on showing references — agencies presenting to clients, teams collaborating on creative direction, and any operation where the reference has to travel from the person who found it to the person who acts on it. The value here is not idea generation; it is durability, organization, and shareability. A board you can hand to a client, that will still render next month, that everyone can comment on, is an operational asset that a folder of screenshots is not. For client-facing teams especially, the polish and persistence of the swipe file is part of how the work is perceived, not just how it is stored. A client who receives a clean, durable, well-organized board experiences the agency as organized and credible; a client who is shown a folder of half-broken screenshot links experiences the opposite, regardless of how good the underlying thinking was. Presentation is not cosmetic in this context — it is part of the deliverable, and the swipe-file tool is partly a presentation tool.
Two things make or break a swipe-file tool, and they are what to evaluate in Foreplay specifically. The first is capture friction: saving a reference must take a second, not thirty, or the team will not do it consistently and the library will be patchy. The second is tag discipline: a tagging scheme consistent enough that you can actually retrieve references later by audience, hook, format, or proof type, and simple enough that the whole team applies it the same way. A beautiful boards UI that is slow to capture into will not get used; a fast capture flow with a chaotic tag scheme produces an unsearchable pile. The best swipe-file workflows make both fast and disciplined, and that combination — not raw library size — is what you are buying. We cover the broader swipe-file category and how to evaluate it in our MagicBrief alternative guide.
There is a social dimension to the swipe file that pure feature comparison misses, and it is decisive for whether the tool pays off: a swipe file only delivers value if the whole team uses it consistently. A library that one producer maintains and nobody else contributes to becomes a private folder with extra steps, which defeats the collaboration that justified buying it. So when you evaluate Foreplay, weight the adoption factors — is capture frictionless enough that a busy buyer will actually do it, is the tagging simple enough that everyone applies it the same way, does it fit where the team already works — at least as heavily as the feature set. The best swipe-file tool for your team is the one your team will still be using in week ten, not the one with the most impressive boards in the demo. A disciplined, shared, lightly-tagged library beats a feature-rich one that decays because the scheme was too elaborate to maintain.
A practical tip for getting tag discipline right from day one: design the smallest tag scheme that still answers the questions you actually ask. Most teams over-engineer tags at the start — a dozen dimensions nobody maintains — and end up with an unsearchable mess anyway, because elaborate schemes decay fastest. Start with three or four dimensions that map to how you brief: audience or angle, hook type, format, and proof element. That is usually enough to retrieve what you need without becoming a chore the team abandons. You can always add a dimension later when you repeatedly cannot filter for something; you can rarely recover a library tagged inconsistently because the scheme was too heavy to keep up.
The honest limit to hold here: a swipe file is not a discovery tool and not an ideation tool. Foreplay helps you keep and present what you have found and decided to save; it does not, on its own, surface what you have not yet seen across every network, and it does not generate the next concept. Many teams who buy a swipe file to fix a discovery problem end up with a beautifully organized library that still misses half of what competitors run — at which point the swipe file was never the real bottleneck. Keep the jobs distinct and the tool is powerful; conflate them and you will be frustrated that the swipe file does not do work it was never built to do.
Neither Tool Is a Measurement Tool
This is the most important section in the comparison, because the costliest mistake teams make with either tool is asking it to prove performance it cannot see. Both Atria and Foreplay work with reference and public signals — saved ads, ad context, what competitors appear to be running. Neither sees your metered performance, and certainly neither sees a competitor's.

Competitor ads are evidence of intent, not proof of performance. When you save a competitor's ad because it has been running across many variants for weeks, that is strong evidence they are investing in it and likely iterating. It is not proof it works. The public data does not reveal their spend, conversion rate, ROAS, or whether the campaign is profitable. A competitor can run a creative heavily for reasons unrelated to performance — brand calendars, internal politics, a misread dashboard, plain inertia. No tool — Atria, Foreplay, AdMapix, or any other — can see a competitor's internal numbers. Any feature or AI summary that claims to surface "winning ads" from public data alone is overselling what the data can structurally support.
This trap is sharper with a swipe file than people expect, because the act of saving an ad subtly implies it is worth emulating. A board full of carefully saved competitor ads starts to feel like a board of proven winners, when all it actually proves is that someone decided each one was interesting enough to keep. The selection bias compounds: you save the slick, confident-looking ads, which makes the board look like a collection of best practices, when slickness is not performance and a polished ad can lose money as easily as a rough one. The discipline is to treat your swipe file as a board of hypotheses to consider, not a board of answers to copy — a distinction that is easy to state and easy to forget when the board looks impressive. The same caution applies to an AI ideation tool that draws confidence from those same saved references: confident output built on a board of unproven ads is still unproven.
Why is the inference from "runs a lot" to "works" reasonable but not certain? It rests on competitor rationality: a competent advertiser kills losers and scales winners, so a creative sustained for weeks and varied many times has probably passed their internal bar. That holds often enough to be the basis of nearly all creative research. But it breaks in predictable ways — brand campaigns run on a calendar, large advertisers tolerate underperformers longer than lean teams, and some competitors simply are not optimizing well, so copying them copies their mistake. The signal is real but probabilistic, which is exactly why your own test is non-negotiable: it converts a probabilistic competitor signal into a definite answer for your audience, your offer, and your price point.
The fix is structural and simple: keep your ad account and product analytics as the source of truth for what actually performed, and use Atria and Foreplay for what they are genuinely good at — ideation and reference management. There is one genuinely reliable use of the public signals both tools surface that is easy to underrate: convergence. If several independent competitors all shift to the same format or angle in a short window, that convergence is much harder to fake than any single advertiser's choice, and it is a near-certain reason to at least test that direction. Use the data defensively first (am I the last team in my category to notice this shift?) and offensively second (which specific angle do I borrow?). The defensive read is where a lot of underrated value lives, because never being surprised by a format your whole category has already moved to is itself a durable edge. We cover this whole evidence-versus-proof discipline in our competitive analysis for paid advertising guide.
This is also the honesty test to apply to either vendor, ours included. Ask point-blank: "Can your tool — or your AI feature — tell me how a competitor's specific ad actually performed?" The correct answer is no, with an explanation of what it can show: what is running, how often it is varied, format, longevity, and how creative is evolving. If you hear "yes, we show you their winners," or an AI feature confidently labels saved ads as high-performing, the tool is overselling what the data supports, and that is a reason to trust its other claims less. A vendor honest about this boundary understands the difference between observed and inferred — the same difference your own briefs and client decks have to respect to stay credible.
How to Run the Trial: Same Task, Both Tools
Do not compare Atria and Foreplay on feature lists. Compare them on your real weekly task, run through each, and time it. This is the single method that cuts through marketing, because feature lists overlap and workflows do not.

Pick one real task you do every week and run it end to end through each tool. If your dominant pain is ideation, the task is: starting from reference ads, how fast do you get to a batch of distinct, briefable concepts or scripts you would actually test? If your dominant pain is reference management, the task is: starting from a set of ads you want to keep, how fast do you save, tag, organize, and produce a shareable board a teammate or client could use? Use the same inputs for both tools so you are measuring the tool, not the luck of a different sample, and score two things only: time-to-output and the quality of that output.
Run it more than once. A single session can flatter or sandbag a tool; the value of either is in repeated weekly use, not a one-off impression. Run your task across two or three sessions and watch whether the tool stays fast and useful or whether the first good result was a fluke. The tool that is consistently fast and produces output you would actually act on is the one that will save you time after the trial ends.
Watch for the common evaluation traps. The demo-data trap: vendor demos shine on hand-picked categories; run yours on your real competitors and markets. The export and share trap: a board or concept that looks complete inside the tool may be gated or strip fields when you try to share it — for Foreplay especially, test the full client-facing share round trip, including link durability over time. And the champion trap: if only the one enthusiastic person who ran the trial can get value, adoption collapses after purchase. Have at least two intended users run the task; a second, less-invested teammate reaching a useful result quickly is the strongest predictor of real adoption, especially for a tool like Foreplay whose whole value is shared team use.
Before you start, write the single sentence the trial must answer, because a trial with a written success condition ends in a clear yes or no and one without it ends in a vague impression and a purchase you half-regret. For an ideation finalist: "Can this get me from my reference ads to five distinct, briefable concepts or scripts in under thirty minutes, twice in a row?" For a swipe-file finalist: "Can this get me from a set of ads to a saved, tagged, shareable board a teammate can use — that still renders next month — in under fifteen minutes?" The sentence costs nothing and reframes the evaluation from the unanswerable "is this a good tool" to the answerable "did it do the one job I need." Keep it visible during the trial so you judge against it, not against whichever feature happened to impress you in the moment.
Score the output, not just the speed, with a fresh pair of eyes. For an ideation trial, hand the concepts to a strategist who did not run the trial: are these distinct and grounded enough to be worth a test slot, or the bland average you could have written yourself? For a swipe-file trial, hand the shared board to the teammate or account person who will actually receive it: can they find what they need and present it without you in the room? Output quality is harder to fake than speed, and the people downstream of the output will tell you the truth about it. A tool that is fast but produces output your team quietly redoes is not saving time; it is moving the work, not removing it.
Where AdMapix Fits Beside Either Tool
We will be precise about where AdMapix sits, because the whole point of this comparison is to match the tool to the job rather than oversell a product. AdMapix is an upstream discovery-and-evidence layer: cross-network competitor search, saved media, frame and hook-level video analysis, and shareable reports. It is not an AI ideation tool like Atria, and it is not a swipe-file-and-presentation tool like Foreplay. It sits before both — it is where the evidence comes from that ideation and reference management then work with.

The reason this matters is the gap the comparison keeps exposing: neither Atria nor Foreplay centers on broad cross-network discovery or frame-level video analysis. Atria assumes you have context to ideate from; Foreplay assumes you have found the references you want to save. Both are downstream of discovery. AdMapix is built for that upstream span: use Search AdMapix to find competitor creative across networks and geographies — wider than what you happen to stumble on — Media to save the strongest examples so your evidence base compounds, Video Analysis to break down hooks and first-screen structure where paid-social tests are actually won, and Reports to package patterns into something you can hand off. Then feed that evidence into Atria to ideate from a stronger source set, or into Foreplay to populate a richer, better-curated swipe file.
This is also why "Atria vs Foreplay" is sometimes the wrong question entirely. If a team is choosing between an ideation tool and a swipe file but the truth is that they systematically miss what competitors run across half their networks, neither choice fixes the real problem — they will simply ideate from incomplete context or save an incomplete set of references, which can be worse than slow, because confident work built on partial evidence is harder to question. For those teams the first investment is the discovery-and-video layer, and the ideation-versus-swipe-file decision can wait until the evidence base is solid. The honest framing is that discovery is upstream of both, and a team that has not solved discovery is not yet at the Atria-vs-Foreplay decision, even if that is the decision they think they are making.
The clean way to hold the three apart: AdMapix answers "what is actually running, across all the places it runs, and how is the video built?" Atria answers "given strong context, what concepts and scripts should we draft?" Foreplay answers "what have we saved, and can we present it durably?" Discovery, ideation, reference management — three distinct jobs in one pipeline. A team that conflates them ends up frustrated that their swipe file does not discover or their ideation tool does not keep references, when those were never the job. Knowing which job is actually slowing you down tells you which tool to reach for first, and the other two fall into place around it.
We are honest about the limits. AdMapix does not do AI concept and script generation the way Atria does, it is not optimized as a production-team swipe file with client-facing boards the way Foreplay is, it does not see competitor spend or ROAS, and we are not going to call it "free" — it is a paid product that should earn its seat against the discovery-and-video job it actually does. If your only bottleneck is blank-page concepting, Atria may be your first trial; if it is keeping and presenting references, Foreplay may be; and AdMapix is the layer that makes either one's input stronger and wider. Where another tool fits a bottleneck better, we would rather say so than sell a mismatch.
A concrete weekly loop shows the three working together rather than competing. On Monday, run your three-to-five-competitor set in Search AdMapix across the networks and countries they actually advertise in, and pull the handful of creatives that are genuinely new or newly dominant — the signal, not everything. For the two or three that look most consequential, run Video Analysis to break down the opening seconds and offer framing, because that structural insight is the part most likely to become a testable idea. Then the hand-off forks by your downstream bottleneck: if ideation is your slow step, take that stronger, video-analyzed evidence into Atria so the AI drafts concepts from rich, current, category-specific material instead of generic context; if reference management is your slow step, push the strongest examples into Foreplay to build a curated, durable, shareable board. Either way the upstream layer raises the ceiling on what the downstream tool can produce, because both ideation and a swipe file are bounded by the quality and breadth of the evidence they start from.
If you are mapping the whole landscape rather than just these two tools, our Atria alternative guide diagnoses the five common bottlenecks and which category fixes each, and our Atria vs MagicBrief comparison covers the other major contender — MagicBrief leans more toward creative analytics and briefing, where Foreplay leans more toward the swipe file and presentation, a distinction worth knowing if you are weighing all three. Once you know your slow step, compare seats on Pricing or start from Login.
Common Buying Mistakes in an Atria-vs-Foreplay Decision
The failure modes in this specific comparison are predictable, and naming them up front saves you from the most common wrong turns. These are the mistakes we see teams make when they pit an ideation tool against a swipe-file tool.

Buying a swipe file to fix an ideation problem. This is the most common mismatch. A team that struggles to come up with the next concept buys Foreplay because it is well-known and beautifully organized — and ends up with a pristine library and the same blank concept doc. Organizing references was never their constraint. If your slow step is producing ideas, a swipe file does not fix it.
Buying an ideation tool to fix a reference problem. The mirror mistake. A team that keeps losing references and rebuilding boards buys Atria for its AI, and ends up generating plenty of angles while still losing the references they meant to show the client. Generating concepts was never their constraint. If your slow step is keeping and presenting references, an ideation tool does not fix it.
Comparing them on feature count or library size. The two tools optimize opposite ends of the pipeline, so a feature tally is almost meaningless. A bigger inspiration set does not help if your bottleneck is durable, shareable boards, and a slicker boards UI does not help if your bottleneck is blank-page concepting. Compare on the task your team repeats, not the catalog.
Skipping the discovery question. Both tools assume you have already found what you need — Atria assumes you have context to ideate from, Foreplay assumes you have references to save. If you cannot see what competitors run across your networks, neither fixes that. Diagnose discovery before choosing between these two, or you will ideate and organize faster from an incomplete picture.
Expecting either to measure performance. Both work with reference and public signals, not your metered results. Choosing based on "which has better data" misframes the decision if you actually mean "which explains my results" — neither does, and neither is supposed to. Your account analytics own that job.
Letting one champion decide. If only the enthusiastic person who ran the trial can extract value, adoption collapses after purchase — especially for Foreplay, whose value is shared team use, and a swipe file nobody else maintains is just a private folder. Trial with at least two intended users.
A Practical Decision Path
If you remember nothing else, remember the order of operations: name the slow task, then pick the tool, then trial it on your real work.
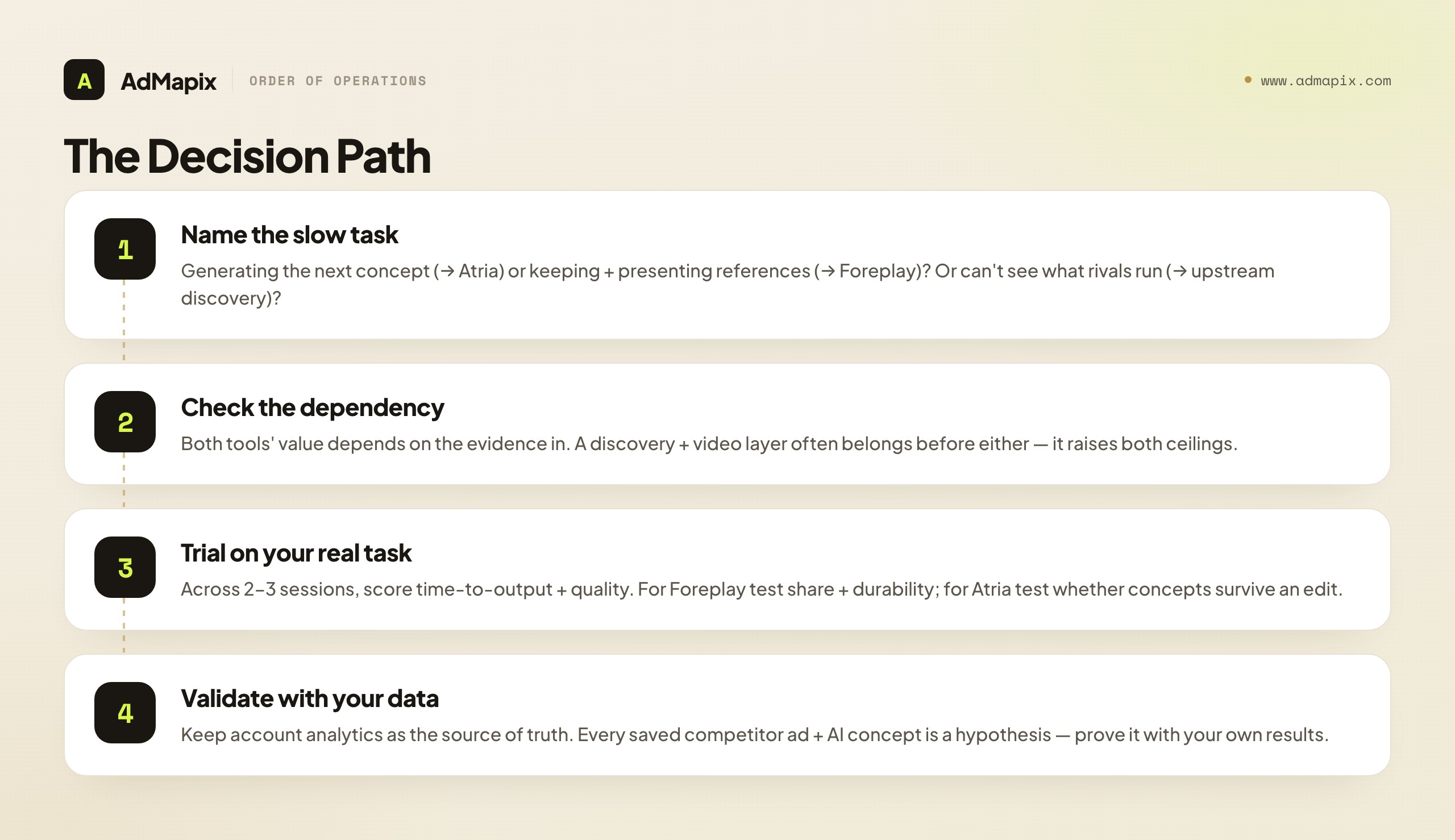
Start by naming whether your dominant weekly pain is generating the next concept or keeping and presenting references. Be honest and specific — "we're slow at creative" is not a diagnosis. If the blank concept doc is your enemy, you lean Atria. If lost references, dead links, and rebuilding boards for clients are your enemy, you lean Foreplay. If "we can't even see what competitors run across our networks" is the truest statement, your real first problem is discovery, and that is the upstream layer, not a choice between these two.
Then check the dependency: whichever you lean toward, its value depends on the evidence going in. Atria's concepts are only as good as the context and constraints you feed it; Foreplay's swipe file is only as valuable as the references you discovered to save. This is why a discovery-and-video layer often belongs in the stack before either — it raises the ceiling on both. Decide whether your current evidence base is rich enough or whether the upstream layer is the real first investment.
Next, trial your finalist on your real weekly task across two or three sessions, scoring time-to-output and output quality, not feature count or library size. For Foreplay specifically, test the share-and-durability round trip, and have a second teammate actually use the shared board; for Atria, test whether the concepts survive a strategist's edit rather than just counting how many it produced. Verify current coverage and pricing on the plan you would actually buy, on the seat count you will really need.
Finally, keep your account analytics as the source of truth, and treat every saved competitor ad and AI concept as a hypothesis to validate with your own results. Do that, and "Atria vs Foreplay" stops being a feature debate and becomes a clear workflow question: which slow task are you fixing, and which tool removes it. The few minutes you spend naming that task before you open a pricing page are the cheapest, highest-leverage minutes in the whole process.
The deeper lesson is that Atria and Foreplay are not really rivals in the way the "versus" framing suggests — they are specialists for adjacent links in one creative chain, and the comparison only resolves once you have located your own broken link. A team whose constraint is ideation and a team whose constraint is reference management will make opposite choices and both be right, because they are solving different problems. The wasted-money version of this decision is the team that picks based on which brand they had heard of, or which had the slicker demo, and then discovers months later that the tool is excellent at a job they were never slow at. Most wasted spend in this category is not a bad tool; it is a good tool bought to fix the wrong link in the chain. Diagnose the link first, and the tool choice becomes obvious — and far cheaper to get right.
FAQ
Should I choose Atria or Foreplay?
Choose by your slowest weekly task. Pick Atria when generating the next concept, angle, or script is the bottleneck and you want AI-assisted ideation. Pick Foreplay when saving, organizing, sharing, and presenting references is the bottleneck — the swipe-file workflow with durable links and client-facing boards. They sit at opposite ends of the same creative pipeline: ideation is upstream, reference management is the connective tissue. Name which task actually slows your week, and the choice follows.
Can AdMapix replace Atria or Foreplay?
Not exactly — it sits upstream of both. AdMapix is a cross-network discovery, video-analysis, and reporting layer; it supplies the evidence that ideation (Atria) and reference management (Foreplay) then work with. It is not an AI concept generator like Atria and not a production-team swipe file with client boards like Foreplay. Many teams use AdMapix to find and analyze competitor creative across networks, then feed that stronger evidence into whichever of the two tools matches their downstream bottleneck.
Is Atria's AI ideation reliable?
It is reliable as a starting point, not as proof. AI ideation is only as good as the context and constraints you feed it — strong, relevant input produces useful concepts; thin input produces generic ones. The AI can cluster patterns and accelerate your first draft, but it cannot tell you what will convert your audience; only your test can. Treat Atria's output as a hypothesis generator, keep a human editor between it and the test queue, and feed it a rich, well-discovered reference base so the concepts are not generic.
What makes Foreplay's swipe file different from a screenshot folder?
Persistence, organization, and shareability. A swipe-file tool keeps references alive so links do not expire, lets you tag and retrieve them consistently, and produces boards you can share and present — including to clients. A screenshot folder does none of that reliably; it decays into dead links and unsearchable images. If your work depends on saving references and showing them later, that durability and structure is the core value, and it is what you are evaluating in Foreplay.
Does saving competitor ads tell me how they performed?
No. Saving an ad records that it ran, not how it performed. Public and reference signals show what is running and how often it is varied, which signals investment — but they do not reveal spend, conversion rate, or ROAS. A competitor can run a creative heavily and still lose money on it. Use saved competitor ads to form hypotheses about what to test, then validate with your own campaign results. No tool can see a competitor's internal performance data.
Which is better for an agency?
Agencies often lean Foreplay, because the recurring need is saving, organizing, and presenting references in shareable, client-facing boards with durable links — exactly its center of gravity. But many agencies pair it with an ideation tool when concept throughput is the constraint, and with an upstream discovery layer so their boards are built on broad cross-network evidence rather than what they happened to find. The right answer is still bottleneck-first: presentation and references point to Foreplay; blank-page ideation points to Atria; discovery points to the upstream layer.
Do I still need analytics if I use these tools?
Yes. Neither Atria nor Foreplay is a measurement tool for your own performance. Your ad platform's reporting and your attribution stack remain the source of truth for what your campaigns actually did. These tools handle ideation and reference management from public and reference signals; your account analytics handle metered performance. Keep the two in separate lanes and read them together — when your own data and the competitive view point the same way, that alignment is a strong signal for your next test.
How do Atria and Foreplay compare to MagicBrief?
All three live in the creative-research stage but with different centers of gravity. Atria leans AI ideation (concepts and scripts). Foreplay leans the swipe file (saving, presenting, durable references). MagicBrief leans creative analytics and shared briefing. Foreplay and MagicBrief overlap on the reference side, but Foreplay emphasizes the swipe-file and presentation workflow while MagicBrief emphasizes analytics and briefing. See our Atria vs MagicBrief comparison and Atria alternative guide to place all three.
Where does video analysis fit between these two?
Neither Atria nor Foreplay centers on frame-level video analysis — it is upstream of both. For paid social, breaking down a competitor's video hook, pacing, and first-screen structure is often where the most testable insight lives, and a tool built for ideation or reference saving is not built for that teardown. If video is where your category competes, a discovery-and-video layer belongs in the stack before either tool, feeding both the structural insight they then ideate from or save.
How often should I review competitor creative?
A weekly or biweekly cadence works for most teams, matched to your creative production rhythm. The goal is to catch format shifts and new angles early enough to test them before they are exhausted, not to watch competitors constantly. Save the strongest evidence so each review builds on the last — this is exactly where a durable swipe file helps — and end every review with a concrete test recommendation. Cadence plus a saved, well-organized evidence base is what turns ad-watching into a compounding advantage.
Key Takeaways
- Atria leans AI ideation (concepts, angles, scripts); Foreplay leans the swipe file (saving, organizing, sharing, presenting references with durable links). Pick by your slowest weekly task.
- The two sit at opposite ends of one pipeline: ideation is upstream, reference management is the connective tissue. A tool great at one is not automatically good at the other.
- Link durability and shareable, client-facing boards are Foreplay's real operational edge; concept and script throughput is Atria's real edge.
- Neither is a measurement tool. Keep account analytics as the source of truth; both work with reference and public signals only.
- Saved competitor ads and AI concepts are hypotheses, not proof. No tool sees competitor spend or ROAS. Validate with your own results.
- AdMapix sits upstream of both: cross-network competitor discovery and frame-level video analysis that strengthen and widen the evidence base either tool then works from.
Sources
Official pages checked as of June 21, 2026. Pricing, product names, and availability can change, so verify the current plan before purchase or migration.
- Atria — positions itself as an AI-powered ad workflow platform built around concept, angle, and script ideation.
- Foreplay — positions itself around the swipe file: saving, organizing, tagging, and sharing ad references with durable links and boards.
- MagicBrief — positions itself around competitor tracking, creative analytics, and shared briefing for performance teams.
- Meta Ad Library and TikTok Creative Center — public ad-transparency surfaces that creative tools index; they show what is running, not how it performed.
Disclosure: AdMapix is our own product. We include it as the upstream discovery, video-analysis, and reporting layer that feeds ideation and reference tools, and we are explicit about where Atria or Foreplay fits a bottleneck better. We do not describe AdMapix as free, and we do not claim it (or any tool) can see competitor spend or performance, because no public tool can.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Semrush Ad Intelligence Alternative in 2026: PPC Research or Creative Evidence?
A 2026 decision framework for choosing a Semrush ad intelligence alternative — when PPC keyword and spend research wins, when competitor creative and video evidence wins, how AdClarity fits, a fair-trial method, and how to build a two-layer stack.

Moat Alternative in 2026: Ad Verification vs. Creative Intelligence
A complete 2026 buyer's guide to choosing a Moat alternative — why teams look past Oracle Moat, what Moat actually does (viewability, invalid traffic, brand safety), the critical split between the ad-verification layer and the creative-intelligence layer, a layered comparison across coverage and fit, who should choose which, a practical migration plan, the honest limits of public creative data, and where a creative-research tool like AdMapix fits.

Pathmatics Alternative in 2026: Ad Spend Intelligence vs. Creative Workflow
A complete 2026 buyer's guide to choosing a Pathmatics alternative — why teams look past Pathmatics (now Sensor Tower), what it actually measures, a layered comparison of spend-intelligence suites versus creative-workflow tools across coverage, data type, price, and fit, who should choose which, a practical migration plan, the honest limits of estimated spend, and where a lighter cross-network creative tool like AdMapix fits.