AI Ad Creative Analysis Tools (2026): The Five Jobs, Best Picks & How to Use Them
A practical 2026 guide to AI ad creative analysis tools — the five distinct jobs they cover (competitor discovery, video teardown, hook scoring, brief generation, test reporting), which tool category owns each job, where AI genuinely helps versus where it overstates, an honest cost-per-decision buying framework, and a repeatable workflow that turns observed ads into a testable brief.

AI Ad Creative Analysis Tools (2026): The Five Jobs, Best Picks & How to Use Them
Updated June 21, 2026 — written and reviewed by the AdMapix Research team.
There is no single best AI ad creative analysis tool, and any guide that hands you a ranked top-ten without first asking what you are stuck on is selling you a leaderboard, not a decision. The phrase AI ad creative analysis tools describes a category that quietly bundles five very different jobs: discovering the ads competitors are running, breaking a video down into its structural parts, scoring which hooks look strongest, drafting the brief for your next creative, and reporting on whether a test actually worked. A tool that is best-in-class at one of those jobs is frequently useless at another, so the only useful question is "best for which job?" This guide maps each job to the tool category that owns it, tells you precisely where AI earns its keep and where it overstates, and gives you a repeatable workflow to turn a raw ad you observed into a brief you can test. Read it alongside our best ad intelligence tools overview, the competitor ad analysis framework, and the creative testing framework — those three flagships cover the wider landscape this guide sits inside.

One distinction runs underneath everything below, and getting it wrong is the most expensive mistake in this category. Your account analytics tells you what happened inside your own spend — your impressions, your clicks, your conversions, your ROAS. Creative intelligence shows you what is happening in the market around you — the ads other advertisers are running publicly. AI can accelerate work in both worlds, but no tool spans both with authority, and a tool that observes the market cannot tell you what converted for you. We will say this plainly throughout, because "AI" branding tempts buyers into believing a creative-analysis tool can predict performance. It cannot. It can generate a sharper hypothesis faster than you could by hand — which is genuinely valuable — but the proof always lives in your own test.
TL;DR — AI Ad Creative Analysis in One Screen
- "AI ad creative analysis" is five jobs, not one: competitor discovery, video teardown, hook scoring, brief generation, and test reporting. Match the tool to the job you are stuck on, not to a ranked list.
- AI is reliable at extracting structure — transcribing, segmenting scenes, labeling hook/pacing/proof/CTA, clustering patterns. It is not reliable at declaring "winners" without performance data behind the claim.
- No tool spans market intelligence and your account analytics. Creative intelligence shows the market; only your analytics shows what converted for you. Treat AI output as a hypothesis generator, never a result.
- Most teams need two or three categories working together — a discovery/evidence layer, a teardown layer, and a reporting layer — not one tool that claims to do everything.
- AdMapix fits the discovery and evidence layer: cross-network ad-creative search, saved media boards, structured video analysis, tagging, and recurring competitor reports. It does not show competitor spend, ROAS, impressions, or targeting — that data is not public.
- Buy on cost-per-decision, not on the length of the feature list or the polish of the AI demo. The question is how many testable briefs the tool helps you ship per month.
- Beware AI overstatement: "winning ad" scores, confident "spend estimates," and "predicted CTR" are models dressed as facts. Read the label, and validate in your own analytics.
What "AI Ad Creative Analysis" Actually Means
AI ad creative analysis is the use of machine-learning models to extract structure and patterns from ad creatives so that a human can decide what to test next. That definition matters because it draws the line precisely: the model extracts and summarizes; the human decides. Tools that blur this line — implying the AI itself decides what will win — are overselling, and the cost of believing them is real budget spent on a model's guess. Before you shortlist a single product, you have to name the job you are buying for, because the five jobs have almost nothing in common except the word "creative."
The first job is competitor discovery: answering "what ads are competitors running right now?" Here AI helps by clustering thousands of creatives, tagging them by format and theme, and grouping them so a human can navigate the volume. What AI cannot do for you is decide which advertisers and which markets actually matter — that is strategy, and it depends on context the model does not have.
The second job is video teardown: answering "how is this ad built?" AI is strong here — it can transcribe the audio, segment the video into scenes, and label the structure into hook, pacing, proof, and CTA. What it cannot judge is whether that structure fits your offer and brand, which requires human taste and product knowledge.
The third job is hook scoring: answering "which opening angles look strongest?" AI surfaces repeated patterns and outliers across a corpus of ads, which is genuinely useful for spotting what a category is converging on. But it cannot weigh brand fit, claim risk, or audience nuance — and a "hook score" with no performance data behind it is a popularity signal, not a profitability prediction.
The fourth job is brief generation: answering "what should the next creative say?" Modern language models draft concepts and variant copy quickly, which compresses the blank-page problem. The human still owns strategy, positioning, and compliance — and must treat AI drafts as raw material, not finished briefs.
The fifth job is test reporting: answering "did the creative actually work?" AI can summarize results and flag shifts across a reporting period. But the budget call — kill or scale — and the client narrative are human decisions grounded in your own analytics, which is the only place the truth about your performance lives.

The practical upshot is that "what's the best AI ad creative analysis tool" is an unanswerable question until you specify the row. A tool that nails competitor discovery may be hopeless at test reporting; a tool with a slick brief-generation feature may have a shallow discovery index. The rest of this guide treats each job as its own buying decision, then shows you how to wire the jobs together into one workflow.
Match Each Job to a Tool Category
Once you have named the job, map it to the category of tool that actually owns it. Most teams discover they need two or three categories cooperating — a discovery layer feeding a teardown layer feeding a reporting layer — rather than a single all-in-one that does each job at 60 percent. Here is the mapping that prevents you from buying the wrong instrument.
Cross-network creative search is the discovery-and-evidence layer. Its role is to let you search the ad creatives running across networks, save the ones that matter, and build a durable evidence base. You reach for it when your bottleneck is "I cannot see what is being run in my category" or "I need saved, searchable proof for a report." AdMapix lives here. Critically, this layer shows creative evidence — the ads themselves, their formats, their longevity — not competitor spend or ROAS, because that data is not public.
AI video-teardown tools are the structure-extraction layer. Their role is to turn a video into a labeled breakdown — transcript, scenes, hook, pacing, proof beats, CTA. You reach for this layer when your bottleneck is "I found a winning video but I cannot articulate why it works well enough to brief my own version." Some discovery tools include teardown; some teardown features are standalone.
Creative-scoring and pattern tools are the prioritization layer. Their role is to rank or cluster hooks and angles so you can decide what to test first. You reach for this layer when you have too many candidates and need to narrow. The caution: a score without performance data is an attention or frequency signal, not a conversion prediction — useful for prioritizing, dangerous if treated as a verdict.
Generative brief and copy tools are the drafting layer. Their role is to compress the blank page — turning a teardown plus a strategy into draft concepts and variant copy. You reach for this layer when production throughput, not discovery, is your constraint. Human review for positioning and compliance is non-negotiable.
Test-reporting tools are the accountability layer. Their role is to summarize what happened in your own spend and tell the story to a client or executive. You reach for this layer when the gap is "I ran the tests but cannot package the results." This layer is the one place that touches your account analytics rather than market intelligence — which is exactly why no market-intelligence tool can truthfully cover it.
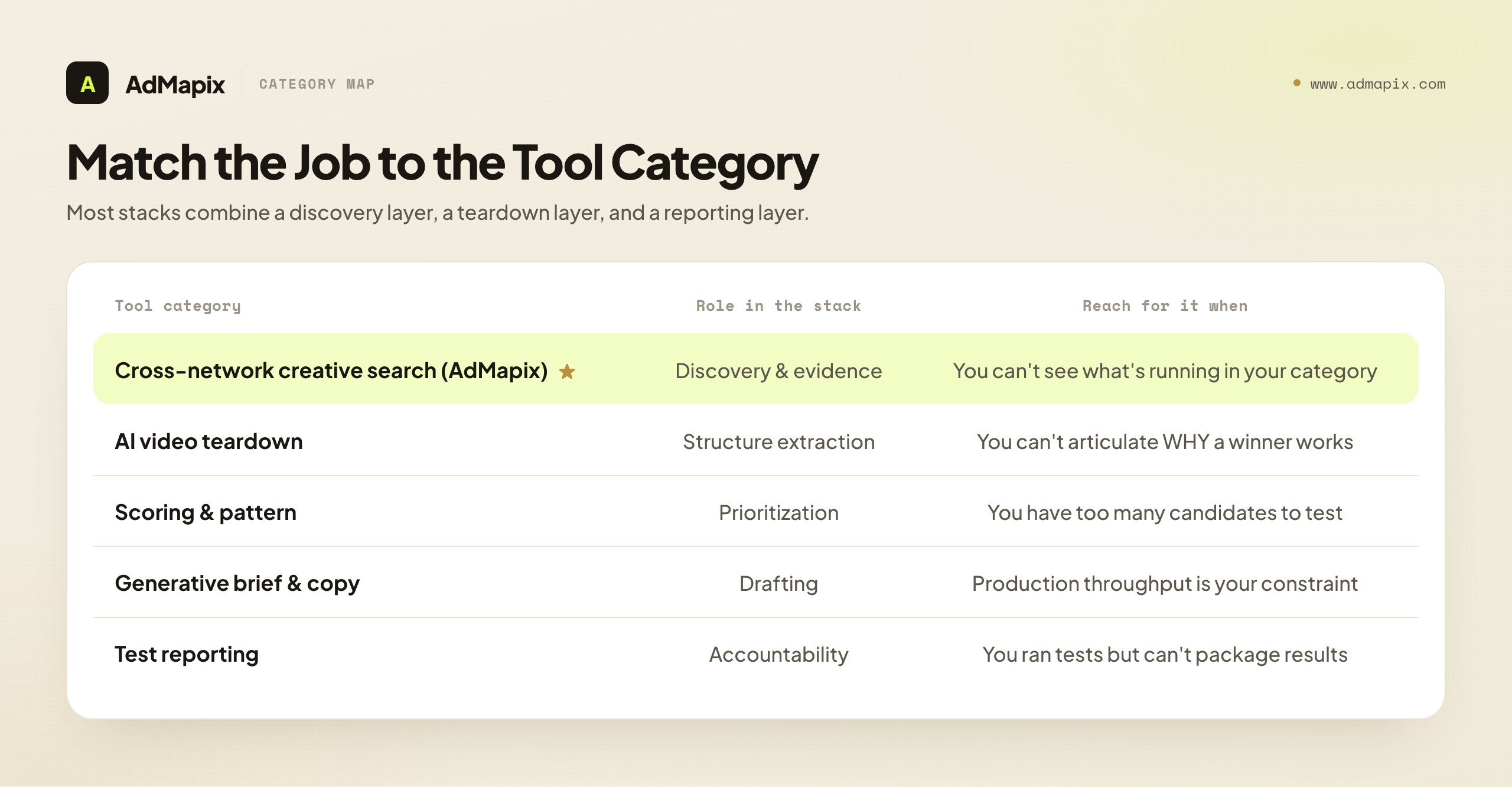
The honest takeaway: a healthy stack usually combines a discovery/evidence layer, a teardown layer, and a reporting layer, with scoring and generation slotting in where your throughput needs them. Buying one tool that claims all five and accepting mediocrity in four to get one is the most common, most expensive mistake in this category.
Where AI Genuinely Helps — and Where It Overstates
The single most valuable skill in buying these tools is reading the line between what AI does reliably and what it dresses up as more certain than it is. Vendors blur this line because "AI predicts your winning ad" sells better than "AI extracts structure faster than you can by hand." Here is the honest split, job by job.
AI is reliable at extraction. Transcribing audio, segmenting a video into scenes, labeling on-screen text, identifying format, and clustering thousands of creatives into navigable themes — these are pattern-recognition tasks modern models do well and fast. If a tool's AI claim is "we extract and organize," it is probably delivering real value, because that is squarely in the model's wheelhouse and it saves hours of manual tagging.
AI is reliable at summarization. Condensing a reporting period into "these themes rose, these fell," or summarizing a hundred competitor ads into "the category is converging on UGC testimonial hooks" — these are summarization tasks, and again models are genuinely good at them. The output is a sharper starting point for human judgment, which is exactly what a creative-analysis tool should provide.
AI overstates when it declares winners. A "winning ad" badge or a "creative score" implies the model knows what converts. Without performance data behind it — and competitor performance data is not public — that score is built on proxies: how long the ad has run, how much engagement it shows, how often the pattern recurs. Those are attention and longevity signals, not profit signals. Read the label, use the score to prioritize, and never let it stand in for a test.
AI overstates when it estimates spend. Some tools present a confident dollar figure for a competitor's spend. That number is a model — a hypothesis generated from public signals, not a measurement of a private number. We hold ourselves to this standard too: AdMapix shows creative evidence, not spend or ROAS, because those are not public, and we will never imply otherwise. Build a budget on a modeled spend figure and you have built it on someone's estimate.
AI overstates when it predicts your performance. "Predicted CTR" or "this creative will outperform" claims cross the line from market intelligence into a promise about your account. No tool that observes the public market can know how your audience will respond to your offer at your price on your landing page. That answer lives only in your analytics after your test. Treat any pre-launch performance prediction as a hypothesis to validate, never a result to bank.

The discipline that follows from this split is simple to state: use AI to generate and organize hypotheses faster, and use your own analytics to prove or kill them. Every tool in this category is a hypothesis engine; none is a results oracle. The teams that win treat the AI output as the fast first draft of a decision, and the test as the decision itself.
The Best Picks by Job (and How to Read a Shortlist)
Because the right tool depends entirely on the job, the most useful "best picks" frame is by row, not by overall rank. For each job, here is what a strong option looks like and how to evaluate a contender without being dazzled by the AI demo.
For competitor discovery, look for search depth and freshness in your niche. The headline database size is the least informative number; what matters is whether the tool can actually search across the networks you care about and whether the index is fresh in your category and geos. A cross-network creative-search tool like AdMapix is built for this — searchable creatives, saved boards, recurring reports — and the right test is to run searches on your real competitors and see whether the results are deep and current, not whether the marketing examples impress.
For video teardown, look for structural granularity. A strong teardown tool gives you a usable breakdown — transcript, scene boundaries, identified hook, pacing notes, proof beats, CTA — not just a transcript dump. The test is whether you can build a creative brief directly from the output. If you still have to watch the video three times to brief it, the teardown is shallow.
For hook scoring, look for transparency about what the score means. A trustworthy scoring tool tells you the score is based on recurrence, longevity, or engagement — public signals — and does not imply it predicts conversion. The test is whether the vendor is honest that the score is a prioritization aid, not a profit forecast. Opaque "AI score" badges with no methodology are a red flag.
For brief generation, look for control and editability. The best generative tools produce drafts you can steer with your strategy, brand voice, and constraints — not black-box copy you have to rewrite entirely. The test is whether the first draft saves time or creates rework. And human review for compliance is mandatory regardless of how good the draft looks.
For test reporting, look for integration with your actual analytics. A reporting tool is only as good as its connection to your real spend data. The test is whether it summarizes your results accurately and produces a narrative a client will trust. Anything that reports on the market rather than your account is a different tool for a different job — do not confuse the two.

The meta-skill in reading any shortlist is to refuse to compare tools on a flat feature grid. A grid that scores everything on every feature rewards the all-in-one that does each job adequately and punishes the specialist that does one job superbly. Score instead on "how well does this do the one job I am buying it for," and let the stack — not a single tool — cover the rest.
A Repeatable Workflow: From Observed Ad to Testable Brief
Tools are only as good as the workflow you run them inside. Here is the loop that connects all five jobs into one repeatable motion, turning a competitor ad you observed into a brief you can launch. Run it weekly and the tools compound; buy them and use them ad hoc and they gather dust.
Step 1 — Discover and save. Start in your discovery layer. Search your category, your competitors, and your formats, and save the creatives that look like movers into a board. The discipline here is to save evidence, not just browse — a saved board is what later becomes a report and a brief. This is the AdMapix-shaped job: cross-network search plus durable saved media.
Step 2 — Teardown the candidates. Take the saved winners and run them through your teardown layer. For each, capture the hook (first 1.5 seconds, opening line, opening visual, emotional beat), the pacing (cut frequency, runtime, where the offer lands), the proof stack (demonstration, before/after, reviews, social proof, in order), and the CTA (exact offer framing and call-to-action words). AI does the extraction; you do the judgment about fit.
Step 3 — Score and prioritize. With a handful of torn-down candidates, use your scoring layer (or simple human judgment) to rank which angle to test first. Weight by fit with your offer and audience, not just by the AI score. Pick one or two to brief, not ten — focus beats breadth at this stage.
Step 4 — Generate the brief. Feed the teardown plus your strategy into your generation layer to draft the brief and copy variants. Then edit hard: align positioning, fix compliance, ground every proof beat in your real product and customers. The AI draft is the starting line, not the finish.
Step 5 — Test and report. Launch the creative and read your own analytics. Did it work — in conversions, not just attention? Summarize the result in your reporting layer, decide kill or scale, and feed the learning back to step one. This is the only step that touches your account data, and it is the only step that produces a result rather than a hypothesis.
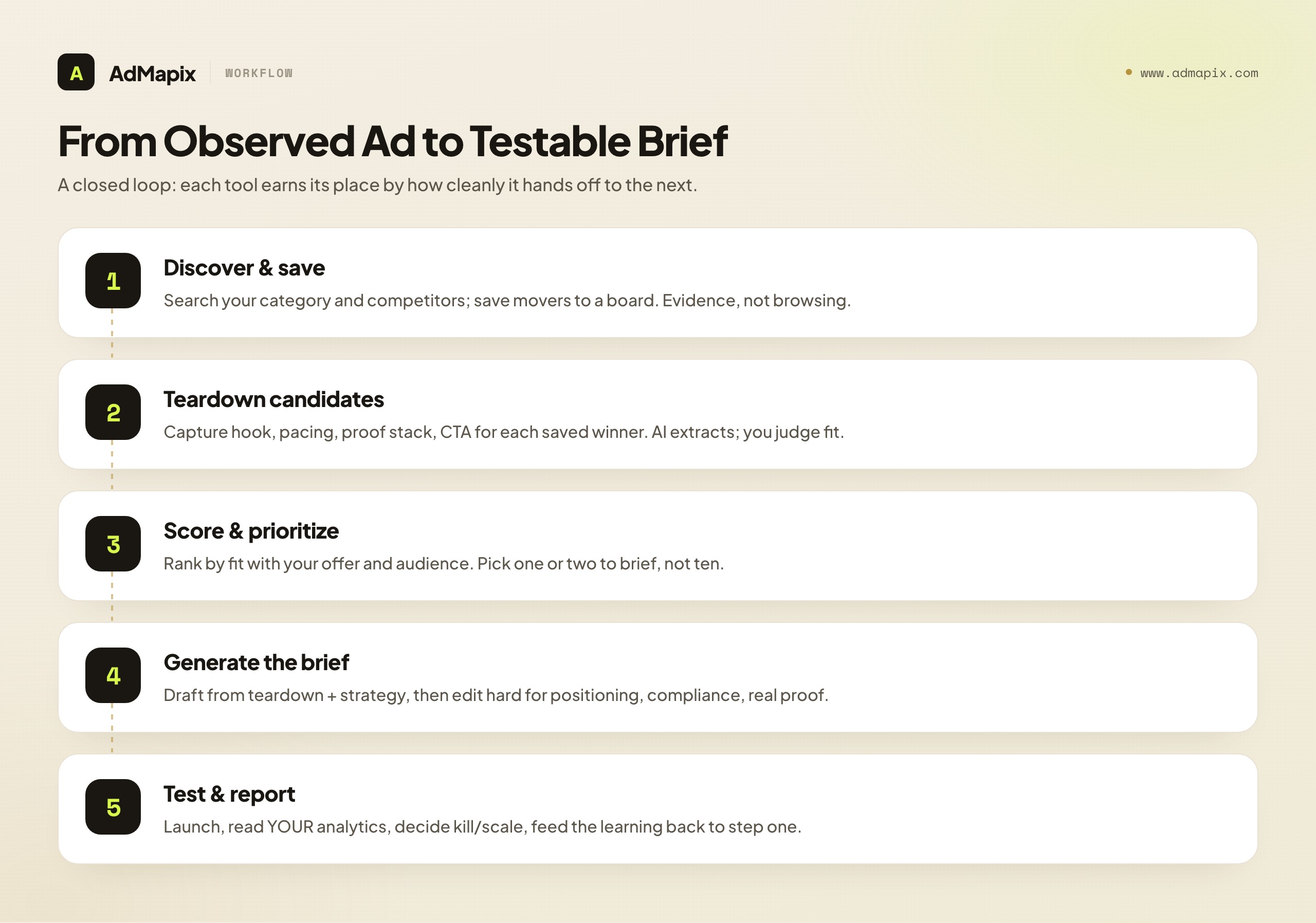
The loop is deliberately closed: discovery feeds teardown feeds scoring feeds generation feeds testing, and testing feeds discovery again. Each tool earns its place by how cleanly it hands off to the next. A tool that produces output you cannot feed forward is a dead end no matter how good its AI is in isolation.
Cost-Per-Decision: The Only Buying Math That Matters
Pricing in this category is noisy — feature lists, seat counts, AI-credit limits, and demo polish all compete for your attention. Cut through it with one metric: cost-per-decision. Estimate how many real decisions a tool helps you make per month — competitors mapped, winners saved, briefs shipped, tests launched, reports delivered — and divide the cost by that number. The headline price is the least informative figure on the page.
This reframe does something important: it forces you to value the tool by its output into your workflow, not by its input feature count. A tool with fewer features that ships you three extra testable briefs a month is cheaper, in cost-per-decision terms, than a feature-rich platform that nobody on the team opens. The graveyard of marketing software is full of expensive all-in-ones bought on feature lists and abandoned because they did not fit anyone's actual loop.
It also exposes the AI-credit trap. Many AI-branded tools meter generation by credits, and the demo makes generation feel central. But if your bottleneck is discovery, not drafting, you are paying for credits you will not use while under-serving the job you actually have. Map your real bottleneck to the right job first; then price the tool that owns that job. Buying generation credits to solve a discovery problem is the most common misfire in this category.
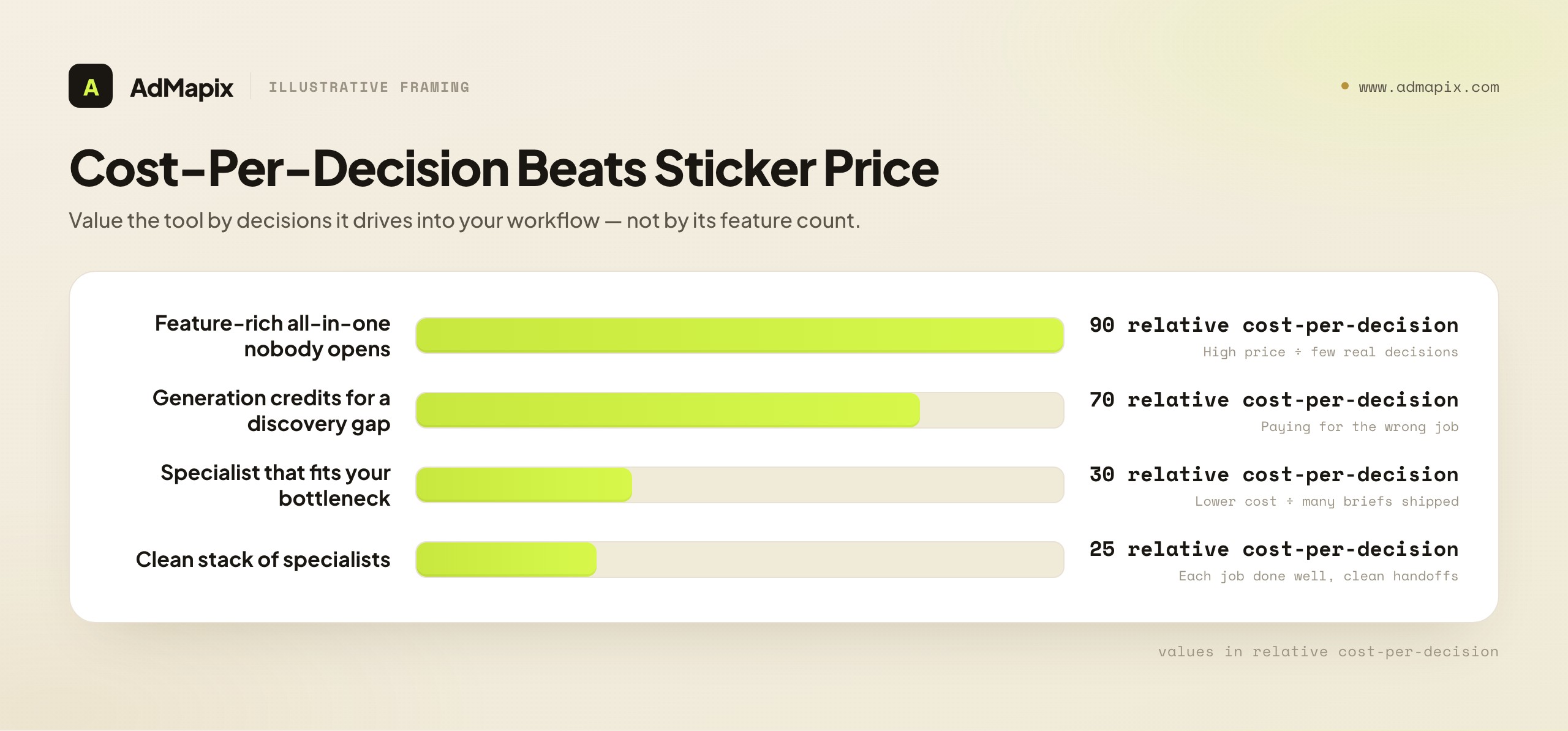
A final pricing discipline: trial on your real work, never the demo. The demo is engineered to dazzle; your category may be thin where the demo is rich. During any trial, run your actual competitors, your actual formats, and your actual reporting need, and count the decisions the tool drives for you. Cost-per-decision computed on your own usage is the only number that predicts whether the subscription will pay off.
Honest Limits Every AI Creative-Analysis Tool Shares
This section is the one buyers skip and later regret, so we make it explicit. Every tool in this category — AI-branded or not, AdMapix included — runs on public data plus a model on top. That boundary defines what any of them can truthfully tell you, and no amount of AI changes the boundary.
What they can genuinely deliver: the ads advertisers are running publicly, structural breakdowns of those ads, clustered patterns and themes, drafted briefs and copy, and summaries of your own test results. That is real, useful, time-saving evidence and acceleration.
What none of them can confirm: a competitor's true ad spend, real ROAS, actual impressions, or audience targeting and bids. Those numbers are not public, full stop. The European Union's Digital Services Act ad transparency rules and platform surfaces like the Meta Ad Library and Google's Ads Transparency Center have expanded what is publicly visible about ads — which is exactly the creative evidence these tools index — but they do not expose private performance. When a tool shows a "spend" number or a "predicted CTR," it is a model, not a measurement. Read the label.
This applies to AdMapix without exception, and we say it directly: AdMapix is searchable cross-network creative evidence — saved ad examples, structured video breakdowns, tagging, and recurring competitor reports. It cannot show you a competitor's spend, ROAS, impressions, or targeting, and the AI it uses extracts and organizes evidence rather than predicting your performance. The deepest limit of all, true for every tool here: even perfect evidence cannot tell you what converts for you. That answer lives only in your own analytics after your own test. Every AI creative-analysis tool is an input to a hypothesis; your test is the proof.

Common Mistakes Buying and Using These Tools
A handful of recurring mistakes account for most of the wasted money and disappointment in this category. Name them and you avoid them.
Mistake 1 — Buying for the leaderboard, not the job. The most common error is reading a "top AI creative tools" list and buying the number one, without naming which of the five jobs you are stuck on. The fix is to identify your bottleneck first, then buy the tool that owns that job.
Mistake 2 — Trusting AI scores as verdicts. A "winning ad" badge or a creative score feels authoritative, but without performance data it is a proxy for attention or longevity, not profit. Use it to prioritize candidates; never let it replace a test.
Mistake 3 — Confusing market intelligence with your analytics. Teams buy a creative-intelligence tool expecting it to tell them what will work in their account. It cannot — it shows the market, not your results. Keep the two worlds distinct and let your analytics own the performance question.
Mistake 4 — Paying for generation when discovery is the gap. AI-credit pricing tempts buyers toward generation features they do not need. Match the spend to the job: if you cannot see what competitors run, buy discovery, not drafting.
Mistake 5 — Buying an all-in-one to avoid a stack. One tool that does five jobs at 60 percent feels simpler than three specialists, but it under-serves every job. A clean stack of specialists that hand off well beats a mediocre monolith almost every time.
Mistake 6 — Skipping the closed loop. Buying the tools but not running the discover-to-test loop means the tools never compound. The value is in the repeatable weekly motion, not in any single feature.
Avoid these six and you will either buy the right tool for the right job or correctly decide your current stack already covers it — both good outcomes.
How AI Actually Reads a Video Ad (and Why That Matters)
To buy these tools well, it helps to understand — at a working level, not a technical one — what an AI model is actually doing when it "analyzes" a video ad. The mechanics explain both where the value is real and where the marketing runs ahead of the capability, and once you see the pipeline you stop being impressed by the wrong things.
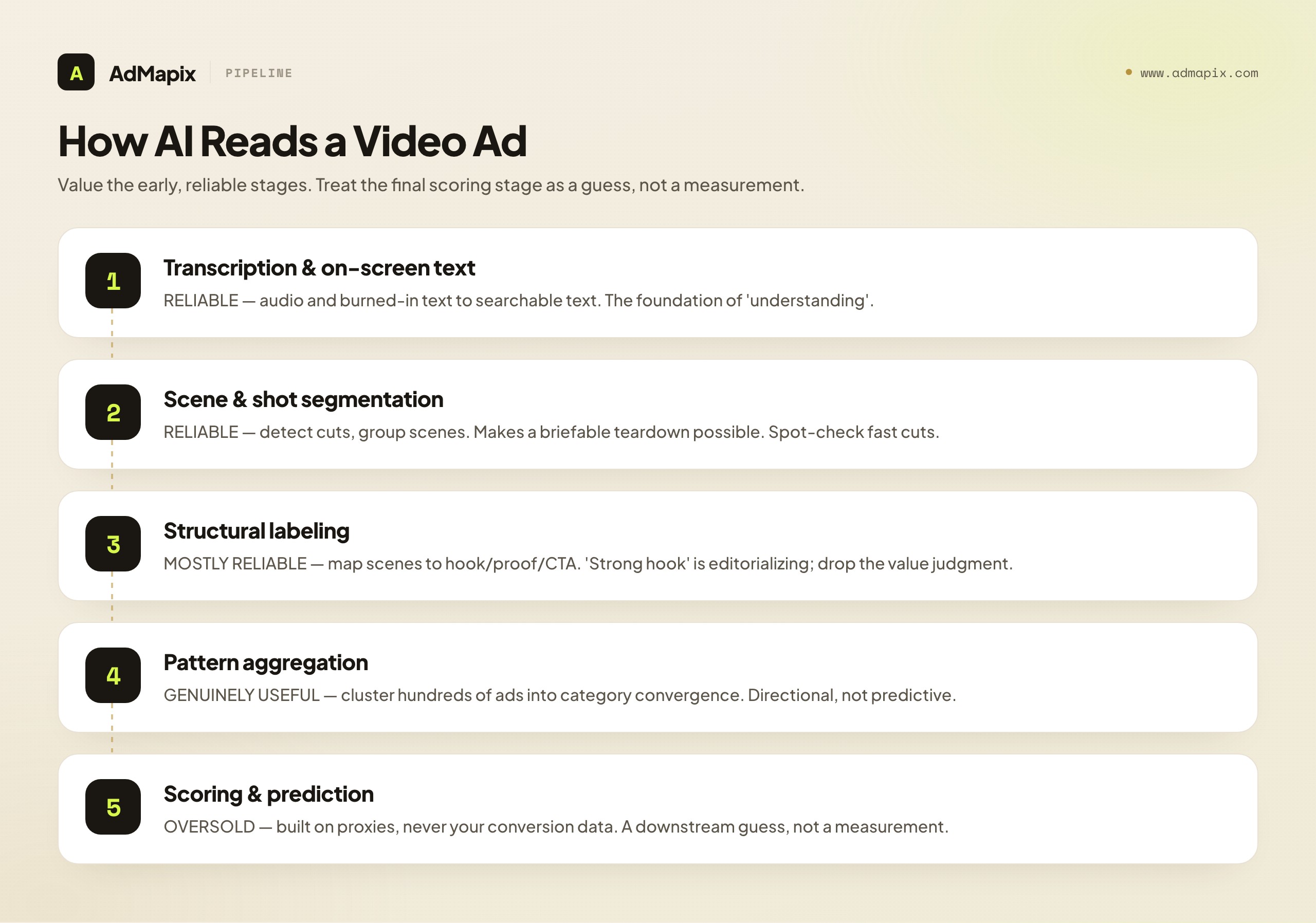
The first stage is transcription and on-screen text recognition. The model converts the audio to text and reads the words burned onto the screen. This is mature, reliable technology, and it is genuinely useful: a searchable transcript of a competitor's ad lets you find every creative in your saved set that uses a particular claim, hook, or phrase. When a tool says its AI "understands" the ad, the foundation is usually this — turning audio and pixels into searchable text. Value here is real and you should weight it.
The second stage is scene and shot segmentation. The model detects cuts and groups the video into scenes, which is what makes a structured teardown possible. Instead of a wall of footage, you get "scene one: problem agitation, zero to two seconds; scene two: product reveal, two to five seconds," and so on. This is where a teardown tool becomes briefable — you can see the shape of the ad, not just its words. The reliability is good, though edge cases (fast-cut UGC, transitions) can trip segmentation, so spot-check rather than trust blindly.
The third stage is structural labeling. The model maps the segmented scenes onto a creative grammar — hook, agitation, proof, offer, CTA — using patterns learned from large corpora of ads. This is more interpretive than transcription, and it is where helpfulness and overreach start to blur. Labeling a scene as "the hook" is usually right; labeling it as "a strong hook" is the model editorializing on thin evidence, because strength is a function of conversion the model cannot see. Take the structural map and leave the value judgment to your test.
The fourth stage is pattern aggregation across many ads. This is the layer that turns one teardown into a category insight: the model clusters hundreds of structurally-labeled ads and reports "the category is converging on testimonial-led hooks with on-screen captions." This is summarization at scale, and it is one of the most genuinely useful things AI does in this domain, because no human can hold a hundred ads in their head at once. The output is a high-quality map of where creative energy is flowing — directional, not predictive.
The fifth and most-oversold stage is scoring and prediction. Some tools add a model that assigns a "creative score" or "predicted performance." Now look back at the pipeline: the inputs to that score are transcripts, scene structure, labels, and public signals like longevity and engagement. None of those inputs is your conversion data, because that does not exist until you test. So the score is a model built on proxies, and however sophisticated, it cannot escape the fact that it has never seen the one variable that matters — what happens when your audience meets your offer. Understanding the pipeline makes this obvious: the score is a downstream guess, not an upstream measurement.
The practical lesson is to value the early, reliable stages — transcription, segmentation, labeling, aggregation — and to treat the final scoring stage as a prioritization aid at most. A tool that is excellent at the first four stages and honest about the fifth is doing real work. A tool that leans its whole pitch on the fifth stage is selling the least trustworthy part of the pipeline as the headline.
Building a Stack Without Overpaying: Three Realistic Configurations
Because the right answer is usually a stack, the practical question is which stack, at what spend, for what stage of business. Here are three realistic configurations, from lean to full, so you can locate yourself rather than over-buying. None requires all five jobs to be tooled — some jobs can be done by hand until volume justifies a tool.
The lean solo configuration. A solo operator or a small DTC brand refreshing creative occasionally does not need five tools. The minimum viable stack is one discovery/evidence layer plus the free official ad libraries, with teardown done by hand and briefs drafted in a general-purpose AI assistant. At this stage your bottleneck is almost always discovery — knowing what to test — so put your single paid dollar into the layer that solves that, and do the rest manually. The cost-per-decision math at this scale favors one well-chosen tool over a stack, because your decision volume is low and a stack would sit idle.
The growth-team configuration. A growth team running multiple channels and refreshing creative weekly has the volume to justify a real stack. The configuration that fits is a discovery/evidence layer (cross-network search, saved boards, recurring reports), a dedicated teardown layer (so briefing keeps pace with testing), and a reporting layer wired to your analytics (so results get packaged without a Friday-afternoon scramble). Scoring and generation can stay manual or lightweight until throughput demands them. At this stage the handoffs between tools matter more than any single tool's feature depth, because the team is running the closed loop weekly and friction at the seams is the real tax.
The agency configuration. An agency owing clients recurring competitive reports and a steady creative pipeline needs the fullest stack, with one addition the other configurations can skip: reporting depth. The agency deliverable is the report, so the discovery layer must produce saved, exportable evidence, and the reporting layer must turn it into a client-trusted narrative. Generation earns its place here too, because production throughput across multiple clients is a genuine constraint. The agency is also the configuration most exposed to the honesty risk — clients ask "what is the competitor spending?" and the agency must be disciplined enough to say "that is not public; here is the creative evidence and here is what our tests showed," rather than passing off a modeled number as fact.
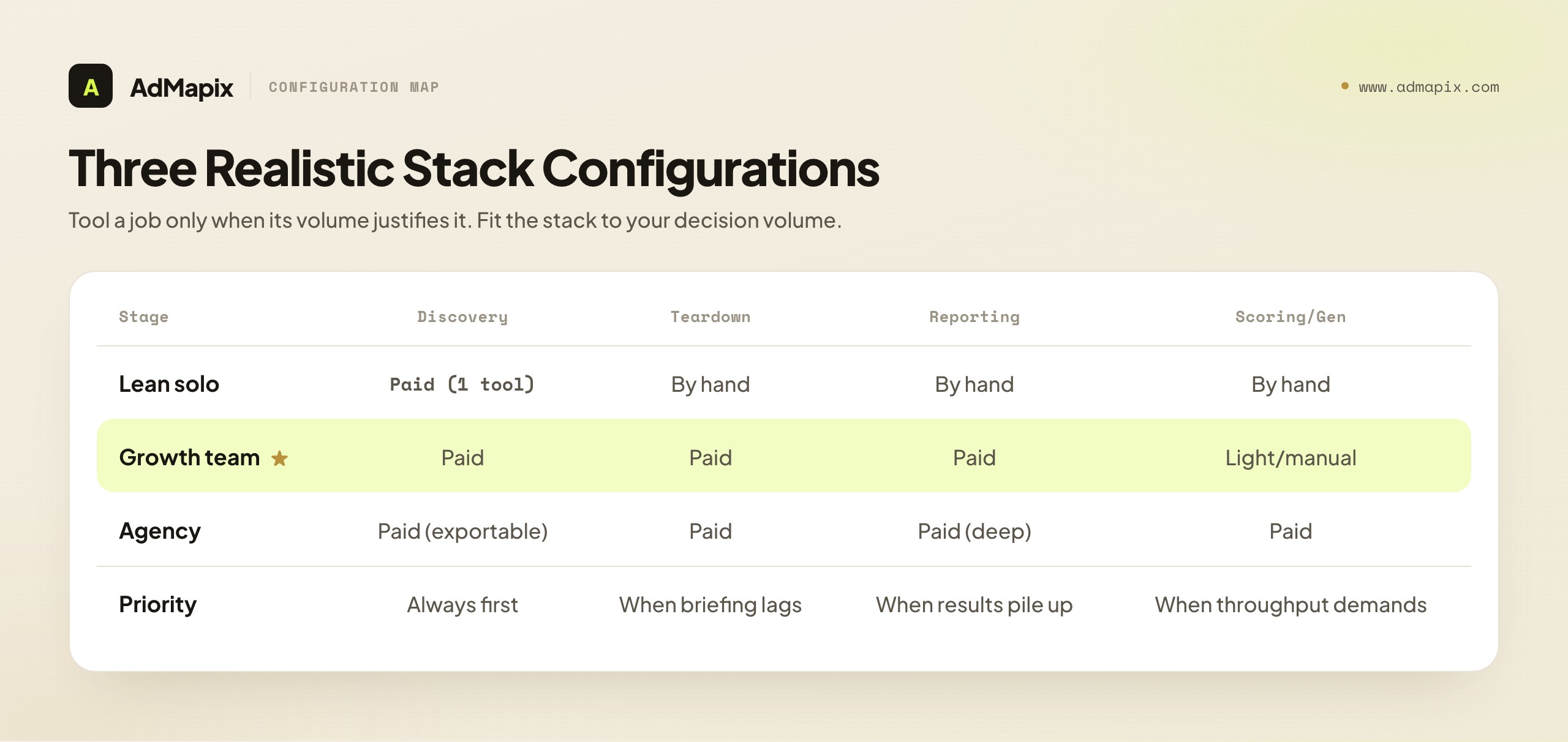
Across all three configurations, the same principle holds: tool a job only when its volume justifies it, prioritize clean handoffs over feature depth, and compute cost-per-decision on your real usage. The lean operator who buys an agency stack wastes money on idle tools; the agency that runs a lean stack drowns in manual assembly. Fit the configuration to your decision volume, and revisit it as you grow.
A Worked Example: From Competitor Ad to Launched Test
Abstract frameworks land better with a concrete walk-through, so here is the full loop run once on a realistic scenario — names and specifics generalized, but the motion exactly as you would run it. Say you run growth for a DTC sleep-supplement brand and you want your next creative test.
You start in the discovery layer. You search your category and a handful of competitors you watch, filtering for video formats on the networks you actually buy. Three creatives stand out as movers — they have been running a while and recur across your competitor set. You save all three to a board labeled with the week and the test theme. You have not decided anything yet; you have gathered evidence.
You run the three through the teardown layer. The AI transcribes each, segments the scenes, and labels the structure. Reading the output, you notice a pattern the aggregation layer confirms across a wider set: the strongest-recurring structure opens with a relatable problem in the first two seconds ("3 a.m. and still awake?"), moves to a demonstration of the product in a nightly routine, stacks two proof beats (a review screenshot and a "sold out twice" social-proof line), and closes with a guarantee-led CTA. The AI gave you the structure; your judgment confirms it fits your offer, because you actually have the guarantee and the reviews to back it.
You score and prioritize. Of the three, two fit your brand and one makes a claim you cannot substantiate without compliance risk, so you drop it. Between the remaining two, you pick the routine-demonstration angle because it maps cleanest to your product's actual use and you can shoot it authentically. One angle, briefed properly, beats three half-briefed.
You generate the brief. You feed the teardown and your strategy into the generation layer, which drafts a brief and three copy variants. Then you edit hard: you swap the generic proof beats for your real review and your real "sold out" moment, you tune the CTA to your actual guarantee wording, and you specify the hook precisely — opening line, opening visual, the two-second problem beat. The AI saved you the blank page; your editing made it launchable and compliant.
You test and report. You launch the creative against a control and read your own analytics — not engagement, but conversions and cost per acquisition. It beats the control modestly, so you scale it and log the learning: problem-first hooks with a real guarantee outperform your previous benefit-first openers. That learning feeds next week's discovery, and the loop closes. Notice what produced the result: not the AI score, not the competitor's longevity, but your own test. Everything upstream was a faster, sharper hypothesis; the test was the proof.

The walk-through makes the whole guide concrete. Each tool did exactly its job and handed off cleanly: discovery gathered evidence, teardown extracted structure, scoring narrowed to one bet, generation drafted the brief, and your analytics delivered the verdict. No single tool did everything, no AI predicted the outcome, and the only certainty came from the test. That is what good use of AI ad creative analysis tools looks like in practice — fast hypotheses, honest limits, and a closed loop that compounds.
Measuring Whether the Tools Are Actually Working
A subscription is a cost; the question is whether it is paying back. Most teams never measure this, which is how expensive tools quietly survive without earning their keep. Here is a lightweight way to hold any AI creative-analysis tool accountable, so you renew on evidence rather than habit.
Track briefs shipped per month, before and after. The clearest output of a discovery and teardown layer is testable briefs. Count how many real briefs your team shipped in the three months before the tool and the three months after. If the number did not move, the tool is not doing the job you bought it for, regardless of how impressive its AI feels in a demo. Output into the workflow is the only honest measure.
Track time-to-brief. Even if brief volume is flat, the tool may be earning its place by cutting the time each brief takes — from a half-day of manual teardown to an hour. Time saved is real value, especially for a stretched team. Measure it: pick a few briefs and honestly log how long discovery-to-brief took with and without the tool. A tool that halves time-to-brief is worth keeping even at flat volume.
Track the hit rate of tool-sourced tests. Of the tests that originated from the tool's discoveries, what fraction beat your control? You will not get a clean signal in a single month — creative testing is noisy — but over a quarter a pattern emerges. If tool-sourced tests win at a rate no better than your old gut-driven ones, the tool is not improving your hypothesis quality, only your speed. That may still be worth it, but you should know which value you are buying.
Watch for the idle-tool signal. The loudest accountability signal is usage. If the team stopped opening the tool after the first month, no feature list will save the subscription. Pull the usage data; a tool nobody opens has a cost-per-decision of infinity. Cancel it, learn what bottleneck you actually have, and redirect the spend to the job that is genuinely stuck.
Run this measurement quarterly and your stack stays honest. Tools that earn their place by shipping more briefs, faster, with a better hit rate, you keep and expand. Tools that coast on demo appeal, you cut. That discipline — renewing on output, not on impression — is what separates a deliberate creative-analysis stack from a drawer of half-used subscriptions.
FAQ
What are AI ad creative analysis tools?
They are software tools that use machine-learning models to extract structure and patterns from ad creatives so a human can decide what to test next. The category spans five distinct jobs — competitor discovery, video teardown, hook scoring, brief generation, and test reporting — and a tool that is excellent at one job is often weak at another. AI in this context reliably extracts and summarizes (transcribing, segmenting, labeling, clustering); it does not reliably predict what will win, because competitor performance data is not public and your own performance only shows up in your analytics after a test.
Which AI ad creative analysis tool is best?
There is no single best tool, because "analysis" is five jobs. The right answer is "best for which job?" For competitor discovery and saved creative evidence, a cross-network creative-search tool like AdMapix fits. For video teardown, you want structural granularity. For hook scoring, transparency about what the score means. For brief generation, editability and control. For test reporting, integration with your real analytics. Most teams combine two or three categories rather than relying on one all-in-one, because an all-in-one tends to do each job adequately rather than any job superbly.
Can AI predict which ad will win?
No, not for your account. AI can surface which ads have run longest, gathered the most engagement, or follow recurring patterns — those are attention and longevity signals from public data. It cannot know how your audience will respond to your offer at your price on your landing page, because that depends on your specific context and only appears in your analytics after you launch. Any "predicted CTR" or "winning ad" claim made before your test is a hypothesis to validate, not a result to bank. Treat AI output as a fast first draft of a decision; treat your test as the decision.
Do these tools show competitor ad spend or ROAS?
No. Competitor ad spend, ROAS, real impressions, and audience targeting are not public, so no tool — AI-branded or not, AdMapix included — can truthfully show them. Some tools present modeled spend estimates generated from public signals; read the label, because an estimate is a hypothesis dressed as a fact. Public transparency surfaces like the Meta Ad Library, Google's Ads Transparency Center, and EU DSA disclosures expose the creative evidence — the ads themselves — not private performance. Use any modeled number as directional signal at most, and confirm what works in your own analytics.
How is AI creative analysis different from my account analytics?
They answer different questions and neither replaces the other. Your account analytics tells you what happened inside your own spend — your impressions, clicks, conversions, and ROAS — and it is the only source of truth about what works for you. AI creative analysis shows you what is happening in the market around you — the ads competitors run publicly and how they are structured. AI can accelerate work in both worlds, but a market-intelligence tool cannot tell you your results, and your analytics cannot tell you what the market is testing. A complete picture needs both, kept distinct.
What does AdMapix do in this category?
AdMapix sits in the discovery-and-evidence layer. It provides cross-network ad-creative search, saved media boards, structured video analysis, tagging, and recurring competitor reports — the raw evidence and organization that feed the rest of the workflow. The AI it uses extracts and organizes creative evidence rather than predicting your performance. Crucially, AdMapix does not show competitor spend, ROAS, impressions, or targeting, because that data is not public, and it will never imply it does. It is the searchable evidence base you build briefs and reports on, not a results oracle.
Where does AI genuinely help in creative analysis?
In extraction and summarization. AI reliably transcribes audio, segments video into scenes, labels on-screen text and formats, clusters thousands of creatives into navigable themes, and summarizes a reporting period into rising and falling patterns. These tasks are squarely in the model's wheelhouse and save hours of manual work, turning a wall of ads into an organized, navigable starting point for human judgment. The value is speed and organization, not prediction — and that value is real.
Where does AI overstate in creative analysis?
In four places: declaring "winning" ads (a proxy for attention or longevity, not profit), estimating competitor spend (a model, not a measurement), predicting your performance (impossible from public market data), and implying the AI itself decides what to test (it extracts; you decide). The pattern is the same each time — a model output dressed up as a certainty. Read the label, use AI scores to prioritize rather than to verdict, and validate every prediction in your own analytics before you bet budget on it.
Do I need several tools or can one do everything?
Most teams need two or three categories working together rather than one tool that claims all five jobs. An all-in-one typically does each job at about 60 percent, while a stack of specialists — a discovery/evidence layer, a teardown layer, and a reporting layer, with scoring and generation slotted in by throughput need — does each job well and hands off cleanly. The exception is a very small operation running one channel with rare creative refreshes, where a single adequate tool may be enough. Buy for your bottleneck, and let the stack cover the rest.
How should I budget for AI creative-analysis tools?
Use cost-per-decision, not the sticker price. Estimate how many real decisions a tool drives per month — competitors mapped, winners saved, briefs shipped, tests launched, reports delivered — and divide cost by that number. This values the tool by its output into your workflow rather than its feature count, and it exposes the AI-credit trap (paying for generation when discovery is your gap). Trial on your real competitors and formats, never the demo, and count the decisions the tool drives for you. The tool with the lowest cost-per-decision for your bottleneck wins, regardless of headline price.
Related Reading
To turn this guide into a working stack, read it next to our best ad intelligence tools overview and the advertising intelligence guide for the wider landscape. Use the competitor ad analysis framework to run the discovery-to-brief loop, the ad creative database to build the searchable evidence layer, and the creative testing framework to close the validation loop in your own analytics — the only place the truth about your performance lives.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Ad Optimization Best Practices: The 2026 Performance Playbook
The definitive 2026 guide to ad optimization best practices — a high-output creative production system, statistically honest A/B testing, budget governance and pacing rules, the metrics that matter, structured account hygiene, an optimization cadence, and an FAQ that settles the hard questions performance teams keep arguing about.

Pathmatics Alternative in 2026: Ad Spend Intelligence vs. Creative Workflow
A complete 2026 buyer's guide to choosing a Pathmatics alternative — why teams look past Pathmatics (now Sensor Tower), what it actually measures, a layered comparison of spend-intelligence suites versus creative-workflow tools across coverage, data type, price, and fit, who should choose which, a practical migration plan, the honest limits of estimated spend, and where a lighter cross-network creative tool like AdMapix fits.

Moat Alternative in 2026: Ad Verification vs. Creative Intelligence
A complete 2026 buyer's guide to choosing a Moat alternative — why teams look past Oracle Moat, what Moat actually does (viewability, invalid traffic, brand safety), the critical split between the ad-verification layer and the creative-intelligence layer, a layered comparison across coverage and fit, who should choose which, a practical migration plan, the honest limits of public creative data, and where a creative-research tool like AdMapix fits.