How to Find Recent Ads in 2026: A Competitor Creative Discovery Workflow
A 2026 workflow for finding and tracking competitors' newest live ads — how to search official ad libraries by advertiser and filter for freshness across Meta, TikTok, and Google, why a recent ad signals intent but not success, the survival check that separates winners from noise, a weekly monitoring cadence, the honest limits of what recency can prove, and where a cross-network discovery layer replaces opening three libraries by hand.

By the AdMapix Research Team — Updated June 21, 2026
How to Find Recent Ads in 2026: A Competitor Creative Discovery Workflow
To find recent ads, search official ad libraries by advertiser name, apply a date or active-status filter, and keep a short weekly list of competitors you check on a fixed day. That much is mechanical. The harder part — the part that actually decides whether the routine is worth your time — is interpretation: a brand-new ad is not the same as a working ad, and confusing the two is how teams end up chasing competitors' experiments instead of their winners. This 2026 guide is for performance marketers and creative strategists who want a repeatable way to spot fresh competitor creatives and decide which ones actually deserve a test. After reading it you will be able to build a freshness routine across Meta, TikTok, and Google, run the survival check that separates a real signal from launch-day noise, set a weekly cadence that compounds, and know exactly what those libraries can and cannot tell you about a recent ad.

An ad library is a public, platform-run archive of the ads a brand is running or recently ran. It shows the creative and basic timing, but rarely spend or performance — which is the whole reason "recent" and "winning" have to stay separate in your head.
TL;DR — Finding and Reading Recent Ads
- The fastest way to find recent ads is advertiser-name search inside official ad libraries, filtered by country and active status, checked on a weekly cadence.
- A recently launched ad signals intent, not success. Treat survival into a second week — or repeated format variants — as the real signal that something is working.
- The survival check is the step most teams skip, and it is the one that separates inspiration from noise. Sorting by newest tells you what entered the market; watching what persists tells you what matters.
- Coverage beats loyalty to one source. Meta, TikTok, and Google each answer a different slice of "what is this competitor running now," so a freshness routine spans all three.
- Recency proves a launch, not performance. No ad library reveals spend, impressions, or conversions, so never read "new" or even "still running" as proof of profit.
- A cross-network discovery layer (such as AdMapix) fits when opening three libraries by hand becomes the bottleneck — one search across platforms, countries, and saved over time — not a replacement for the interpretation discipline.
What "Recent" Actually Tells You (and What It Hides)
A recent ad proves a competitor launched something. It does not prove the thing works. This distinction is the entire foundation of useful freshness research, and getting it wrong is the single most common way teams waste their monitoring time.
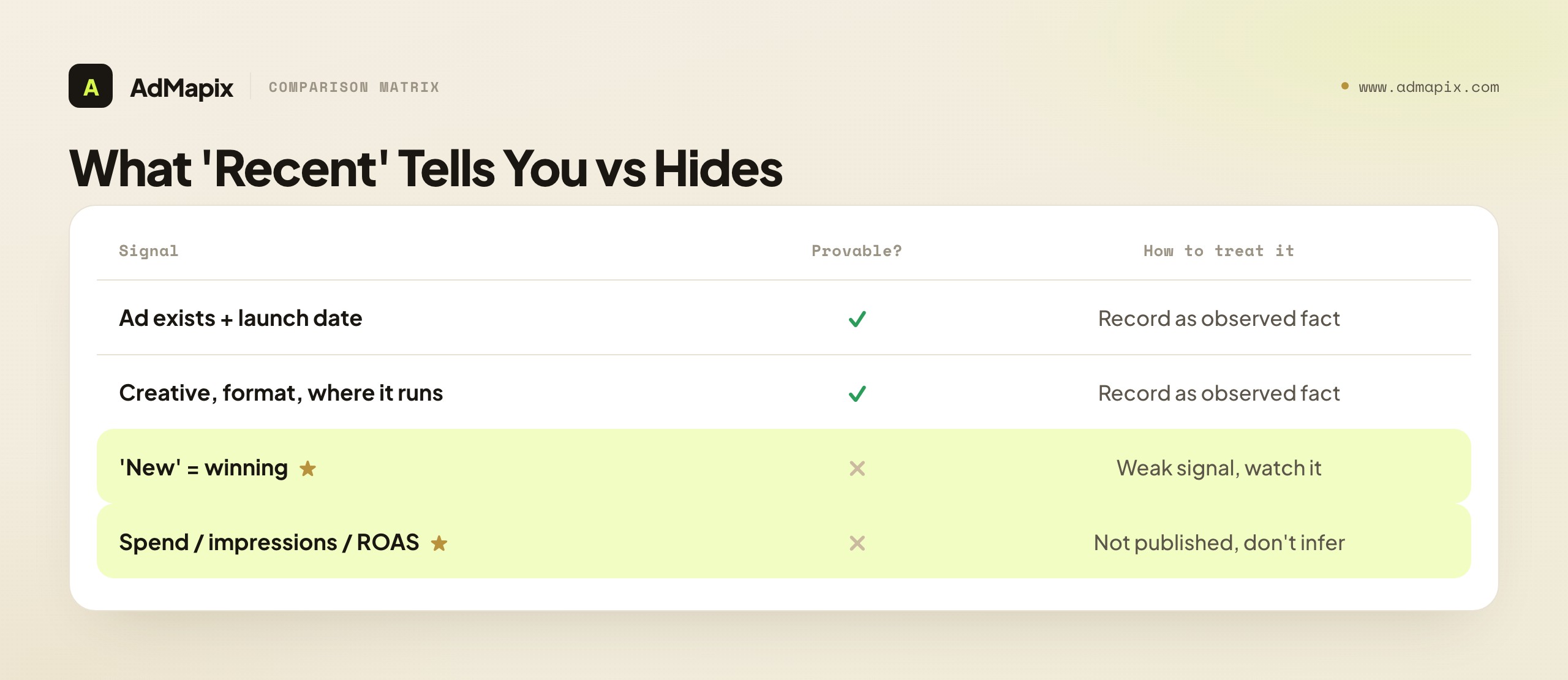
Ad libraries surface the creative and a rough start date, but most do not publish spend, impressions, or conversion data, so recency on its own is a weak signal. A brand launches ads for all kinds of reasons that have nothing to do with a creative being a proven winner: they are testing a new angle, refreshing fatigued creative, chasing a seasonal moment, or simply throwing several ideas at the wall to see what sticks. A single ad that appeared yesterday is, statistically, far more likely to be one of those experiments than a validated winner — because most ads any advertiser launches do not become winners, by the basic math of creative testing. So "this competitor launched a new ad" is a starting point for investigation, not a conclusion you can act on.
The strongest reading of "recent" comes from what happens next. An ad that is still live two weeks after it launched, or one that spawns three or four small variations, is far more likely to be working than a single ad that appeared and vanished — because advertisers tend to kill what does not perform and pour budget and iteration into what does. The persistence and the iteration are the signal; the launch alone is just noise with a timestamp. This is why a date filter is a starting point, not a verdict: sort by newest to see what entered the market, then watch the same advertiser over time to see what survives. The survival check is the part most teams skip, and it is exactly the part that separates inspiration worth acting on from a feed of competitor experiments that will be gone next week.
There is a useful mental reframe here. Instead of asking "what did my competitor just launch," ask "what did my competitor launch a couple of weeks ago that is still running." The first question gives you a list of experiments; the second gives you a much shorter list of things that have survived at least one round of the advertiser's own optimization. Both are worth knowing, but they mean different things, and a freshness routine that only ever looks at the newest ads is reading the experiments while missing the survivors. The discipline of looking back two weeks to see what persisted, not just forward to what is new, is what turns recency-watching from entertainment into intelligence.
It helps to understand why the launch alone is so weak a signal, in terms of the underlying math of creative testing. Performance advertisers run portfolios of creative precisely because they do not know in advance which ones will work — that is the entire point of testing. A typical testing program launches many creatives and expects most to underperform, with a minority carrying the results; the hit rate on new creative is low by design, because if you already knew what would win you would not need to test. So when you observe a competitor's brand-new ad, the base rate says it is most likely one of the many that will not become a winner, simply because most new creatives do not. This is not pessimism about that specific ad — it is the arithmetic of a process built on testing many ideas to find a few. The launch tells you the advertiser is testing; it does not tell you they are testing something good, because they themselves do not yet know. Only their subsequent behavior — what they keep, kill, and scale — reveals their verdict, and that verdict is what you are actually after.
This base-rate logic is also why the strongest freshness researchers feel almost no urgency about brand-new ads and considerable interest in two-week-old survivors. The newness that makes an ad feel like a hot tip is, statistically, the property that makes it least proven. Inverting the instinct — treating "just launched" as "least informative" and "still running after two weeks" as "most informative" — is the single mindset shift that turns freshness research from a source of FOMO-driven noise into a source of grounded intelligence. The competitor's newest ad is the one you should care about least in terms of acting on it, and the one you should log so that you can run the survival check on it later. Logging the new, acting on the survived: that is the rhythm.
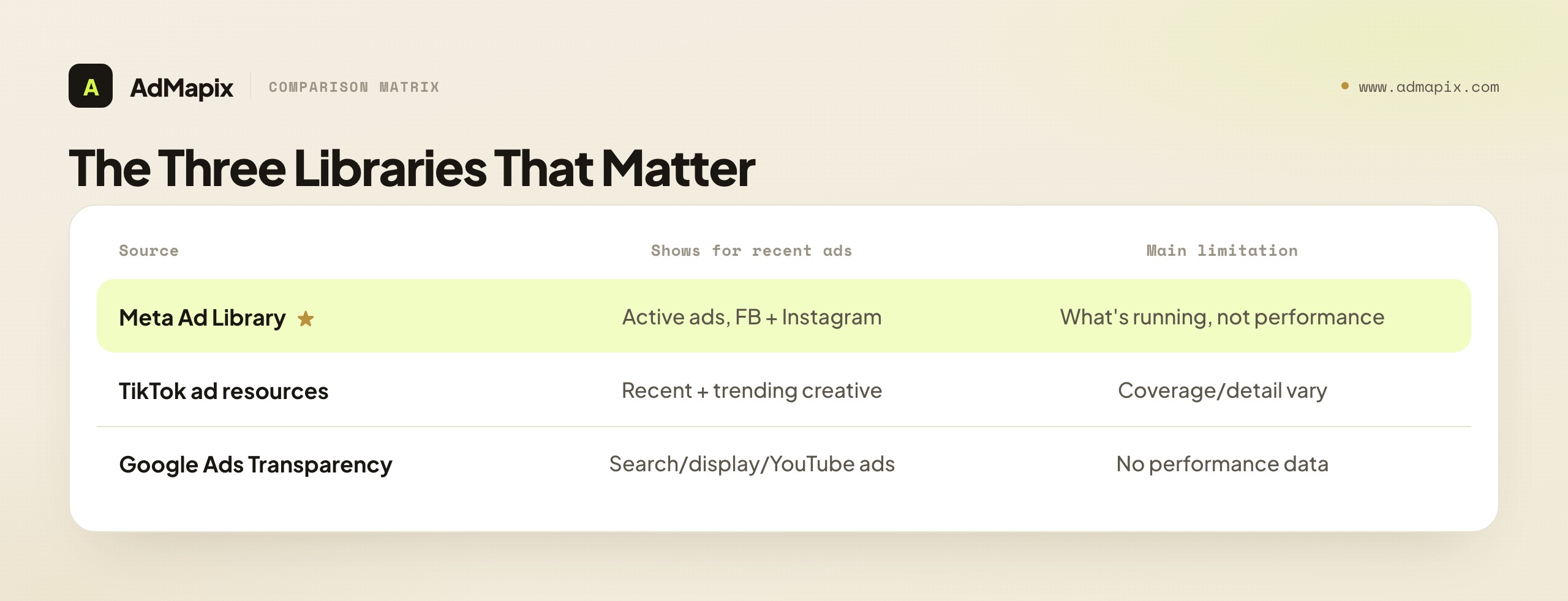
Where to Look: The Three Libraries That Matter
Start with the official, platform-run libraries because they are authoritative and free; add a cross-network tool only when switching between them becomes the bottleneck. Each library answers a different slice of "what is this competitor running now," so the goal is coverage of where your competitors actually advertise, not loyalty to one source.
| Source | What it shows for recent ads | How to filter for freshness | Main limitation |
|---|---|---|---|
| Meta Ad Library | Active and recent ads across Facebook and Instagram | Search advertiser name, set country, filter to active | Shows what is running, not spend or performance |
| TikTok ad resources | Recent ads and trending creative on TikTok | Search by advertiser or browse trending, filter by region | Coverage and detail vary; not a full spend picture |
| Google Ads Transparency Center | Recent and active ads across Google surfaces | Search advertiser, filter by region and format | Format and region rules vary; no performance data |
Meta's Ad Library is the place to start for most consumer and ecommerce competitors, because so much paid social runs through Facebook and Instagram and the library is comprehensive and free. Search the advertiser by name, set the country you care about, and filter to active ads to see what is currently running. The critical limitation to remember is that it shows you what is running and a rough timeline, but not the spend, impressions, or results behind any of it — it answers "what" and "when," never "how well."
TikTok's ad resources matter increasingly as more creative-led and short-video advertising moves to the platform, especially for ecommerce and younger-audience brands. You can search by advertiser or browse trending creative, filtered by region. The honest caveat is that coverage and detail vary, and what you can see does not amount to a full spend or performance picture — but for spotting fresh short-video angles a competitor is testing, it is the right place to look, and missing it means missing the channel where a lot of creative experimentation now happens first.
Google's Ads Transparency Center covers recent and active ads across Google's surfaces, searchable by advertiser and filterable by region and format. It is the place to catch competitors' search, display, and YouTube creative that never appears in the social libraries. Format and region rules vary, and like the others it carries no performance data. The reason to check all three rather than one is simple: a competitor's full recent-ad footprint is split across these platforms, and looking at only one shows you only the slice of their experimentation that happens to live there. Coverage of where your competitors actually advertise — not depth on one favorite source — is what makes a freshness routine complete.
A Weekly Freshness Routine That Compounds
Finding recent ads once is easy; the value comes from a routine that runs on a fixed cadence so you catch what is new and see what survives. Build the routine around a short, fixed list and a regular check, because consistency is what turns scattered browsing into a picture of how your market's creative is moving.

- Keep a short competitor list. Pick the five to ten advertisers whose creative actually informs your decisions — direct competitors and a few aspirational or adjacent brands. A list that is too long never gets checked; a focused one gets checked every week.
- Check on a fixed day. Pick one day a week and run the same searches across the libraries your competitors use. The fixed cadence is what makes the survival check possible — you can only see what persisted if you look at regular intervals.
- Sort by newest, then look back two weeks. Note what entered the market since last week, and — more importantly — note which of last fortnight's launches are still running. The survivors are your real signal.
- Save with context, not just screenshots. For each ad worth noting, record the advertiser, the launch timing, the format and angle, and a one-line read on why it matters and whether it has survived. Provenance is what lets you track survival over weeks.
- Escalate the survivors into tests. An ad that has survived two weeks or spawned variants is a hypothesis worth a real test on your own account. A launch-day one-off is a note to watch, not yet a brief.
The discipline that makes this compound is the fixed cadence plus the survival check. A team that checks erratically sees a random scatter of competitor ads with no sense of which are working; a team that checks the same list every week builds, over a couple of months, a genuine read on which competitors iterate fast, which angles keep surviving, and where the market's creative is heading. The routine is cheap — an hour a week for a focused list — and it is the difference between reacting to whatever competitor ad happened to catch your eye and systematically tracking what is actually persisting in your market. Most of the value is in steps 3 and 5: looking back to see survivors, and escalating only the survivors into tests rather than chasing every launch.
Recent vs Winning: The Survival Check in Detail
The survival check deserves its own section because it is the analytical core of freshness research, and doing it well is what separates teams that learn from competitor creative from teams that just watch it scroll by.

The logic is simple and rooted in how advertisers actually behave. A disciplined advertiser launches more ads than they keep. They test, they read their own performance data, they kill what loses, and they scale what wins. From the outside, you cannot see their performance data — but you can see the consequence of it, in what they choose to keep running and iterate on. So while a single launch tells you almost nothing, the pattern of what survives the advertiser's own culling tells you a great deal. An ad still running two weeks after launch has, in effect, passed the advertiser's internal test, because they would have killed it otherwise. An ad that spawns variations has been judged worth iterating on. These are inferences from observable behavior about unobservable performance, and they are the strongest reads a freshness routine can produce.
Read several survival signals together for the strongest inference. Longevity — still running after two weeks, a month, longer — is the baseline signal that an ad cleared the advertiser's bar. Iteration — the same core angle appearing in three or four small variants — signals the advertiser found something worth refining, which is often a stronger signal than longevity alone, because it shows active investment rather than mere persistence. Scaling across placements or regions — the same creative appearing in more countries or surfaces over time — suggests the advertiser is widening a bet that is working. When several of these line up on the same creative or angle, you are looking at the closest thing to a confirmed competitor winner that public data can give you. When none of them do — a single ad that launched and vanished — you are looking at an experiment that probably did not work, and treating it as inspiration would mean copying a competitor's failure.
The honest limit, which the next section expands, is that even a strong survival signal is an inference, not a measurement. You are reading the advertiser's behavior as a proxy for their results, and the proxy can mislead — an advertiser might keep a losing ad running out of inattention, or kill a winner for reasons unrelated to performance. So even a well-survived ad is a strong hypothesis, not a proven winner, and the only thing that proves it works for you is testing it against your own offer and audience. The survival check gets you to a much better hypothesis than the launch alone; your own test still has the final word.
What Recent-Ad Data Can and Cannot Prove
This deserves its own section because the gap between "recent" and "winning" — and between "still running" and "profitable" — is the single most misread thing in freshness research. Ad libraries prove what is running, not what is performing.
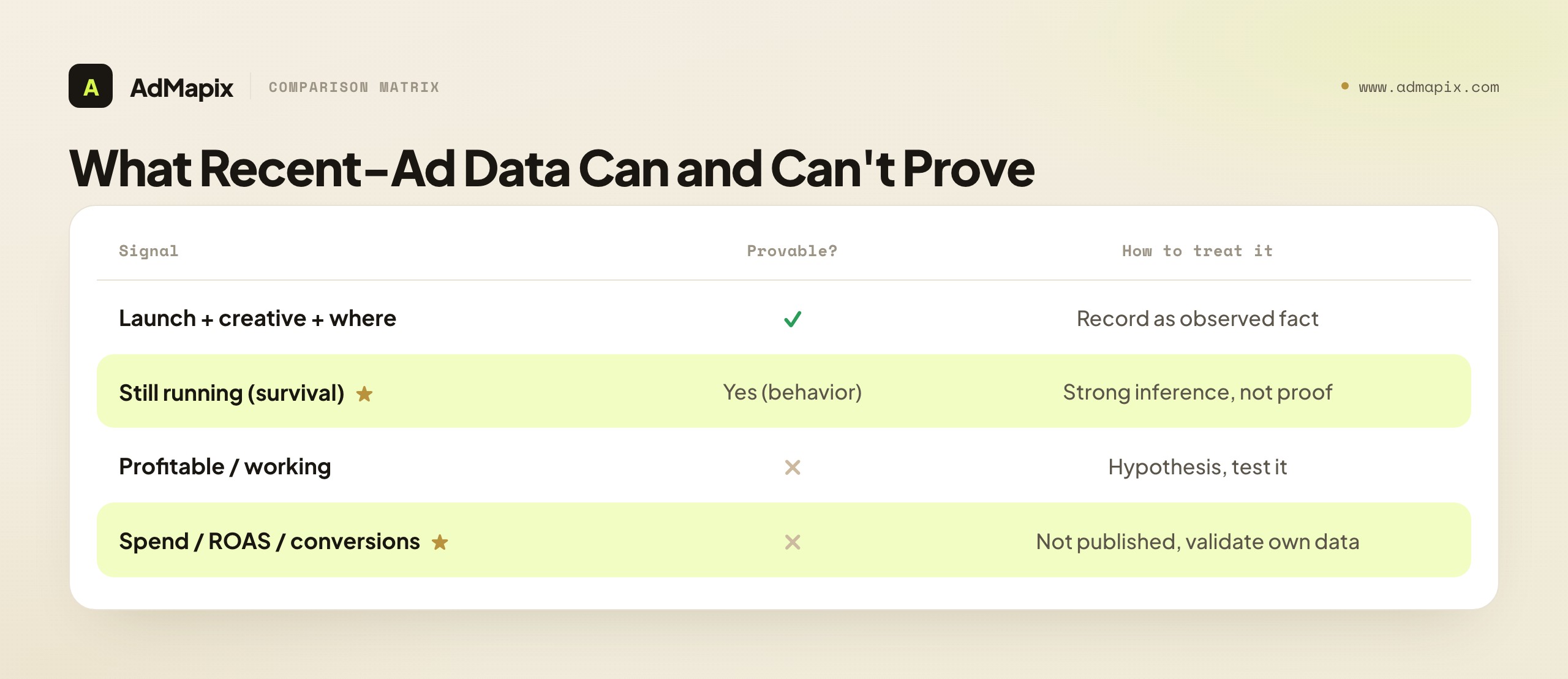
When you find a recent competitor ad, you can prove it exists, when it appeared, what the creative is, the format, and often where it runs. You cannot prove the spend behind it, the impressions, the click-through rate, the conversion rate, the return on ad spend, or whether it is profitable — none of that is published, and no ad library reveals it. The survival check strengthens your inference, but it does not cross this line: "still running after two weeks" is observable behavior, while "profitable" remains an inference you cannot confirm from the library. So even your strongest reads are hypotheses, ranked by how much survival evidence supports them, not facts about a competitor's results.
This matters most when recency tempts you to move fast. The whole appeal of freshness research is catching what is new early, and the danger is acting on "new" as if it were "proven" because it feels urgent and timely. A brand-new competitor ad is the weakest possible signal — it is one experiment among many that has not yet survived anything — and yet its newness makes it feel like a hot lead you should chase immediately. Resist that. The disciplined move is to note the new ad, then weight your attention toward what has survived, because the survivors are where the real intelligence is. Chasing every fresh launch means chasing your competitors' experiments, most of which they will abandon — you would be doing their failed testing for them, a beat behind, with your own budget.
There is also a saturation angle. The recent ads that are easiest to spot — the ones from the biggest advertisers, running widely, impossible to miss — are also the ones every other competitor watching the same brands has already seen. By the time a creative angle is unmissable across a major advertiser's recent ads, the early advantage in that angle is often gone. The edge in freshness research frequently lies in the quieter, earlier signal — the smaller competitor's surviving experiment, the angle just beginning to appear before it is everywhere. Use the routine to catch what is genuinely early and surviving, not just what is loud and recent, because loud-and-recent is what everyone else is already copying too.
Common Mistakes in Finding and Reading Recent Ads
Most wasted effort in freshness research traces back to a few avoidable errors.
- Treating "new" as "winning." A recent launch is one experiment among many, not a proven creative. The survival check — what is still running after two weeks — is the real signal, and skipping it means chasing noise.
- Checking erratically instead of on a cadence. You can only see what survived if you look at regular intervals. A fixed weekly check is what makes the survival inference possible; sporadic browsing never does.
- Watching one library and missing the rest. A competitor's recent-ad footprint is split across Meta, TikTok, and Google. Looking at one shows you only the slice of their testing that lives there.
- Reading "still running" as "profitable." Survival is observable behavior and a strong inference, but it is not a measurement of results. Even a well-survived ad is a hypothesis, not a proven winner, until you test it.
- Tracking too many competitors. A list of thirty never gets checked; a focused list of five to ten gets checked every week. Coverage of the competitors who actually inform your decisions beats a long, ignored list.
- Chasing the loudest recent ad late. The most-visible recent creative is the one everyone else has already seen. Weight quieter, earlier, surviving signals over loud, saturated ones.
- Saving screenshots without context. A recent ad with no note on its timing, format, and survival status cannot be tracked over time. Save with provenance, or you cannot run the survival check next week.
The two costliest errors are the first and the fourth: treating new as winning, and reading still-running as profitable. They share a root — collapsing the distinction between what is observable (launch, survival) and what is not (performance, profit). The discipline that prevents both is the same: separate "recent" from "winning" in your head, use survival as a strong inference rather than proof, and validate every promising pattern against your own test before you act. Hold that line and freshness research gives you a real read on your market; drop it and it becomes a fast way to chase competitors' experiments with your own budget.
Platform Nuances: How Freshness Reads Differently on Each Library
Each of the three libraries has quirks that change how you should read "recent," and knowing them prevents you from misinterpreting what you see. Treating all three identically is a common error that leads to wrong inferences.
On the Meta Ad Library, the strongest freshness signal is the active-status filter combined with how long an ad has been running, which Meta surfaces. Because Meta's library is comprehensive for paid social, it is also the best place to run the survival check — you can see an ad's start date, check whether it is still active, and watch the same advertiser's account fill with variants over weeks. The nuance is that a single advertiser may run many near-identical ads for placement or audience-split reasons that look like "variants" but are really the same creative duplicated, so read iteration as genuinely different angles or executions surviving, not just a high count of similar entries. Meta's richness is a gift for the survival check and a trap if you mistake duplication for iteration.
On TikTok, freshness reads differently because the platform's culture is faster and more trend-driven. Creative angles rise and fall on TikTok more quickly than on Meta, so the survival window may be shorter — an ad surviving even one week on a fast-moving trend can be meaningful, and the line between "test" and "scaled" compresses. The nuance is that TikTok's discovery is heavily driven by what is trending in organic content, so a competitor's recent ad may be riding a trend that is itself about to peak; reading a TikTok recent ad means also reading whether the trend it sits on is rising or fading. Coverage and detail also vary more than on Meta, so hold your TikTok survival inferences a little more loosely.
On the Google Ads Transparency Center, freshness reads differently again because Google spans search, display, and YouTube, and the survival dynamics differ by surface. A search ad's "freshness" matters less than its persistence, since search creative changes less often than social; a YouTube video ad behaves more like a social creative with a clear hook to study; and display creative rotates on its own logic. The nuance is to read recency in the context of which Google surface the ad runs on, because a "recent" search ad and a "recent" YouTube ad are different kinds of signal. Across all three libraries, the universal discipline holds — recent is not winning, survival is the signal — but the specific shape of "recent" and the right survival window vary by platform, and a researcher who reads them all identically will over- or under-weight signals depending on the channel.
How to Tell a Test From a Scaled Campaign
A more advanced skill within freshness research is reading whether a recent ad is an early test or part of a scaled campaign, because the two mean very different things for how you should respond. Public signals let you make a reasonable, if imperfect, inference.
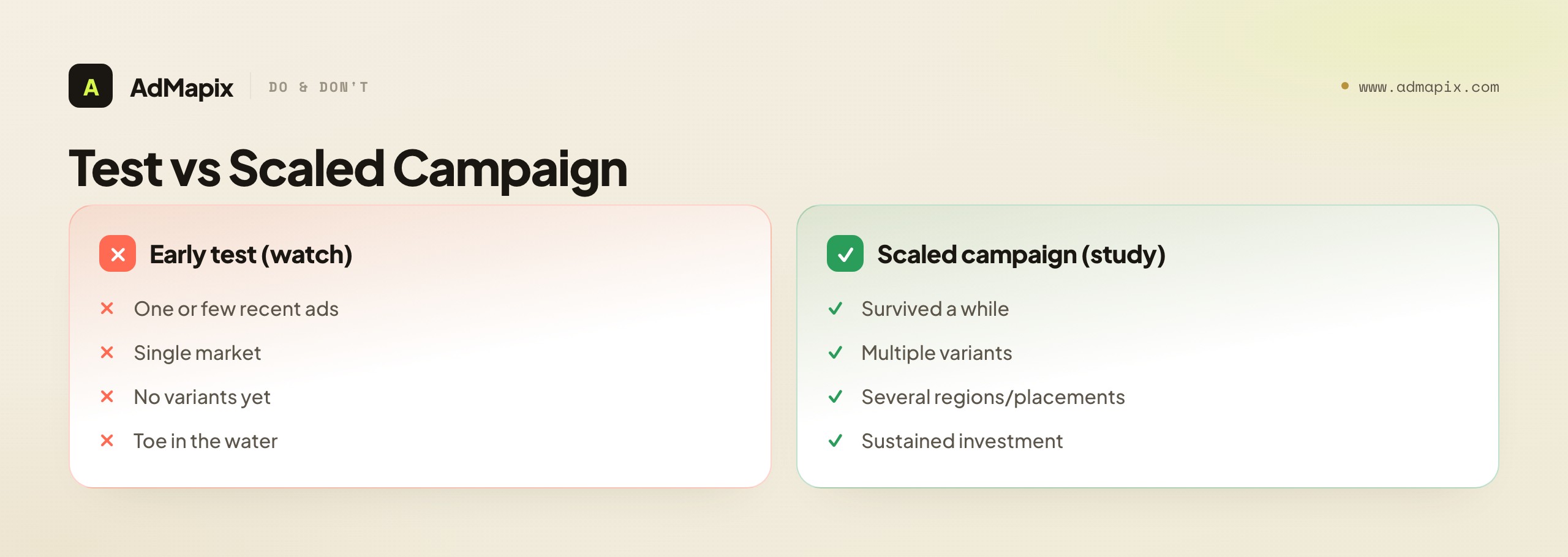
An early test usually looks like one or a few ads, recently launched, in a single market, with no variants yet — the advertiser is dipping a toe. A scaled campaign usually looks like a creative that has survived a while, appears in multiple variants, runs across several regions or placements, and is clearly receiving sustained investment. Reading which one you are looking at changes your response. A competitor's early test is an early-warning signal — they are exploring an angle, and if it works you will see it scale, so it is worth noting and watching but not yet worth reacting to. A competitor's scaled campaign is a confirmed bet — they have committed budget to something that, by the survival logic, has cleared their internal bar, and it is worth studying closely and considering as a tested hypothesis for your own account.
The practical value of this distinction is timing. If you can spot a competitor's early test and watch whether it scales, you get an early read on where the market might move — and if you have your own version ready when the angle proves out, you are not a beat behind. If you only ever notice the scaled campaigns, you are reacting to angles your competitors validated weeks ago, which is still useful but later. The freshness routine, run on a cadence, is what lets you catch the early tests and watch them mature, rather than only seeing the finished, scaled result. The caveat, as always, is that these are inferences from public behavior — you cannot be certain a single ad is a test rather than a deliberately narrow campaign — so hold the read as a probability, not a certainty, and let what happens over the following weeks confirm or revise it.
Reading Creative Velocity: How Fast a Competitor Iterates
Beyond any single recent ad, a freshness routine run on a cadence reveals something more valuable over time: a competitor's creative velocity — the rate at which they launch, kill, and iterate. Velocity is a meta-signal, and once you can read it, you understand a competitor's whole creative operation, not just their current ads.
A high-velocity advertiser launches many recent ads, kills most quickly, and iterates fast on the few that survive. Reading their library week over week, you see a churn of experiments and a thin layer of survivors that change often. This pattern signals a mature, test-driven creative program with the production capacity to feed it — a competitor who treats creative as a portfolio and learns fast. Their recent ads, individually, mean little (they launch so many), but their survivors are unusually meaningful, because they emerged from a lot of testing. With a high-velocity competitor, weight the survival check heavily and ignore the launch noise almost entirely.
A low-velocity advertiser launches recent ads rarely, changes them slowly, and shows little iteration. Their library is comparatively static week to week. This signals either a small creative operation, a brand-led rather than performance-led approach, or a category where creative simply matters less. With a low-velocity competitor, each recent ad carries more weight relative to their own baseline — a rare launch from a slow-moving advertiser is more notable than one launch from a churn machine — but the absence of fast iteration also means fewer strong survival signals to read. You adjust your interpretation to their pace. The key is that velocity is always read relative to each advertiser's own baseline: a "burst" of three new ads means nothing from a churn machine and a great deal from a competitor who normally launches one a month, so the same raw count is a different signal depending on whose engine produced it.
The strategic read from velocity is competitive: a high-velocity competitor will out-iterate you on creative unless you match their pace, and their surviving angles are your best-validated hypotheses precisely because they survived heavy testing. A low-velocity competitor is more vulnerable to being out-tested, and a fast, disciplined freshness-and-testing routine of your own can win the creative race against them. Reading velocity turns the freshness routine from "what are competitors running" into "how does each competitor's creative engine actually work," which is a far deeper intelligence — and one only a consistent, cadence-driven routine can produce, because velocity is invisible in any single snapshot. For the discipline of running your own tests at pace, see the creative testing framework; for managing the fatigue that drives competitors' iteration, see ad creative fatigue analysis.

Building a Survival Log: Turning Cadence Into a Dataset
The survival check only works if you can remember what you saw last week, which means the freshness routine needs a lightweight record — a survival log. Without one, every weekly check starts from scratch and you can never actually run the survival inference, because you have no record of what an ad looked like, or whether it existed, a fortnight ago. The log is the difference between a routine that compounds and one that resets every week.
A survival log does not need to be elaborate; a simple structured record is enough. For each ad worth tracking, capture the advertiser, the date you first observed it, the platform and placement, the format and angle in one line, the mechanic or hook, and a status you update each week — newly observed, still running, iterated (with a note on how), scaled (with where), or gone. The act of updating the status each week is the survival check: an ad that moves from "newly observed" to "still running" to "iterated" over three weeks is visibly clearing the advertiser's bar in front of you, while one that moves from "newly observed" to "gone" is visibly an abandoned experiment.
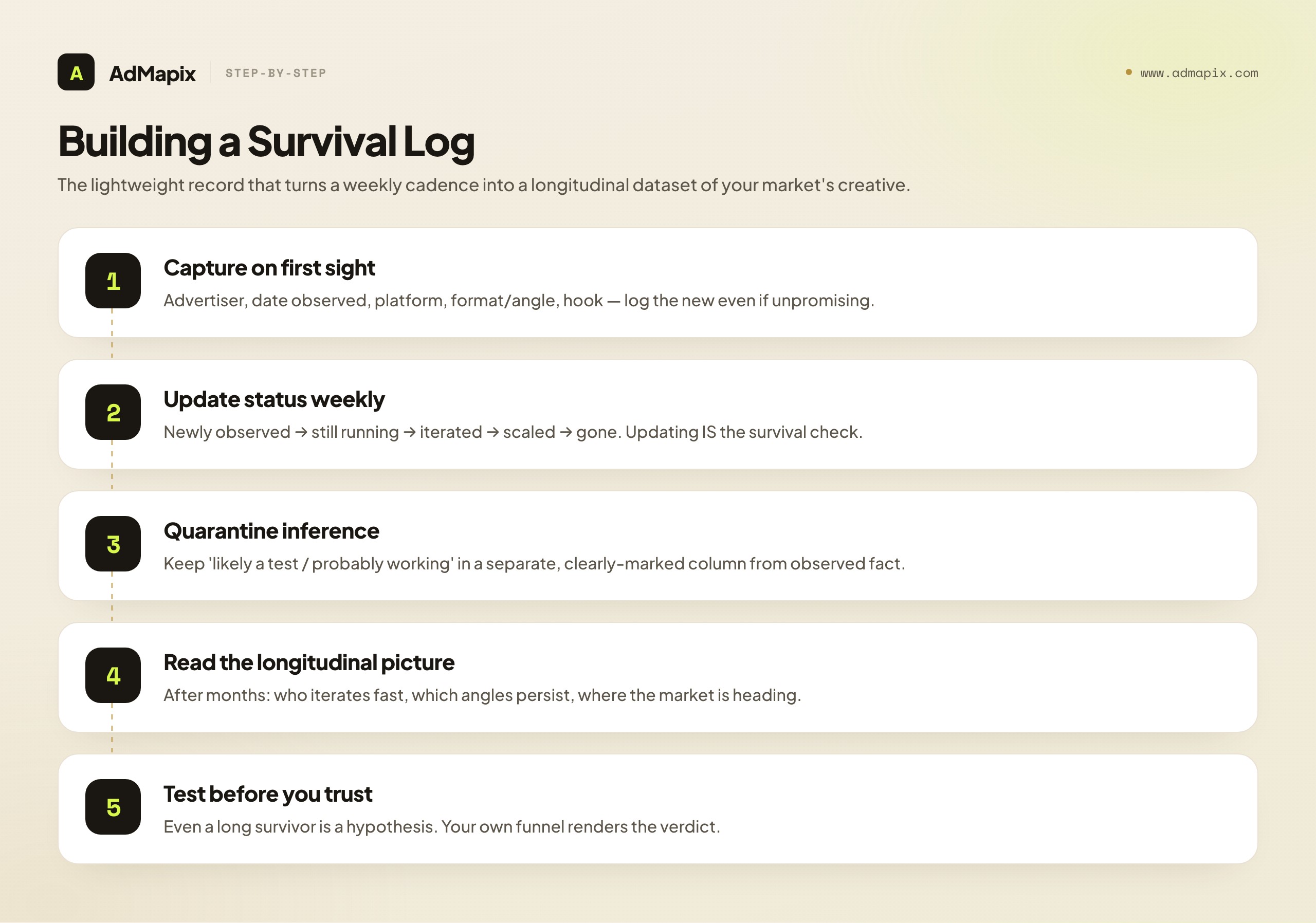
The log compounds in value in a way a folder of screenshots never can. After a couple of months, it is a longitudinal record of your market's creative — which advertisers iterate fast, which angles keep surviving across competitors, which formats are rising, and which competitors are testing into the same space you are. That longitudinal picture is genuine market intelligence, and it is impossible to reconstruct after the fact, because the libraries do not preserve the sequence of what launched, survived, and died in the way your log does. The advertisers' own culling erases the failed experiments from the live view; your log is the only place the full story — including the failures, which are themselves informative — persists.
Two disciplines keep a survival log honest. First, log the new even when it looks unpromising, because you cannot run the survival check on an ad you never recorded — the whole point is to look back and see what persisted, and that requires having logged it when it was new. Second, record only what is observable — launch, format, survival status, scaling — and keep your inferences (likely a test, probably working) in a separate column clearly marked as inference. Mixing observed fact and inference in the same field is how a log silently turns "still running" into "profitable" over time, which is exactly the error the whole method is built to avoid. A clean log of observable behavior, with inference quarantined and tested before it is trusted, is the quiet engine that makes everything else in freshness research compound.
Recency, Seasonality, and Reading the Calendar
A recent ad never appears in a vacuum — it appears at a moment in the calendar, and the calendar changes what "recent" means. A surge of new competitor ads in the weeks before a major shopping season is not the same signal as the same surge in a quiet month, and reading recency without reading the calendar leads to two opposite errors: mistaking a seasonal flood of experiments for a strategic shift, and mistaking a seasonal lull for a competitor going quiet.
Most advertisers raise their creative output ahead of high-demand periods — they launch many new ads to find the angles they will scale into the peak. So a spike in a competitor's recent ads in the run-up to a seasonal event is expected, and the individual launches in that spike are even weaker signals than usual, because the advertiser is testing aggressively for a moment, not necessarily shifting strategy. The survival check still applies — which of the pre-season experiments survive into the peak is the real signal — but the raw volume of new ads should be read against the seasonal baseline, not as a sudden burst of competitive intent. Conversely, a competitor launching unusually many ads in a quiet season, against the seasonal grain, is a more notable signal precisely because it is unexpected, and worth a closer look.
The calendar also changes the survival window. During a fast-moving seasonal push, ads may be launched and killed faster than usual as advertisers race to find the peak angle, so a two-week survival window might compress to one. After the season, advertisers often cull aggressively, retiring the seasonal creative, and a wave of competitor ads disappearing post-peak is normal housekeeping, not a competitor pulling back. Reading these rhythms — pre-season testing surge, in-season scaling of survivors, post-season culling — lets you interpret a competitor's recent-ad activity correctly instead of over-reacting to the calendar's normal effects. The practical move is to annotate your survival log with the season, so that when you look back you can tell a seasonal experiment from a year-round bet, and a post-season cull from a genuine retreat. Recency read against the calendar is sharper than recency read in isolation, and the difference is often the difference between a correct competitive read and a false alarm.
When a Cross-Network Discovery Layer Helps
The official libraries are authoritative and free, and for a small competitor list they are enough. The friction appears when the routine scales: opening three libraries by hand, running the same searches across each, and manually tracking survival over weeks becomes a real time cost, and that is the point where a cross-network discovery layer earns its place.

A cross-network discovery layer like AdMapix fits here, as a complement to the official libraries rather than a replacement for them. It is built for teams that want to search ad creatives across networks in one place with Search instead of opening Meta, TikTok, and Google libraries separately, save the media in Media so survival is trackable over time without manual screenshots, break down video structure and hooks with Video Analysis — the first three seconds, the proof, the CTA that a thumbnail hides — tag what they find, and turn it into a Report. The reason this is a separate layer is that the official libraries are built for looking up one advertiser on one platform, while a cross-network layer is built for monitoring a competitor set across platforms over time — the exact shape of a freshness routine that has outgrown manual checking. Compare access on Pricing once the routine repeats, or log in to run your first cross-network search.
It is honestly not the right tool if you track two or three competitors on one platform occasionally — the official Meta, TikTok, and Google libraries are free, authoritative, and entirely sufficient for that, and a discovery layer would be capacity you do not use. A cross-network discovery layer earns its place specifically when the freshness routine spans many networks and competitors, when survival has to be tracked over weeks without manual screenshots, and when findings have to become shareable reports for a team. Name the scale first: a few competitors on one platform stays in the free libraries; a broad, multi-network, tracked-over-time routine points to a layer like AdMapix — and the interpretation discipline (recent ≠ winning, survival is the signal) stays exactly the same whichever you use.

For the broader landscape, our guide to the best ad spy tools of 2026 compares the whole field by price, coverage, and use case. For the deeper monitoring picture, ad tracking for competitive research covers building a full tracking system, and tracking competitor Facebook ad spend is honest about what spend you can and cannot infer. For the AI-ideation angle on saved creative, the Atria ad library guide goes deeper.

FAQ
How do I find a competitor's recent ads?
Search the official ad libraries by the competitor's advertiser name, set your target country, and filter to active or recent ads. Start with the Meta Ad Library for Facebook and Instagram, add TikTok's ad resources and Google's Ads Transparency Center to cover those platforms, and check on a fixed weekly cadence. The mechanical part is the search; the valuable part is then watching the same advertiser over time to see which of their recent ads survive, because survival — not the launch — is the real signal.
Does a recent ad mean a competitor found a winner?
No. A recent ad proves a competitor launched something, not that it works. Most ads any advertiser launches are experiments that do not become winners, so a single fresh ad is a weak signal. The strong signal is what survives: an ad still running two weeks later, or one that spawns several variants, has effectively passed the advertiser's own internal test. Treat a brand-new ad as a note to watch, and escalate only the survivors into hypotheses worth testing on your own account.
What is the survival check and why does it matter?
The survival check is watching, over time, which of a competitor's recent ads keep running and which get iterated on. It matters because advertisers kill what loses and scale what wins, so while you cannot see their performance data, you can see the consequence of it in what they choose to keep. An ad still live after two weeks, appearing in multiple variants, or scaling across regions has cleared the advertiser's bar — the closest thing to a confirmed competitor winner public data offers. It is the step most teams skip and the one that separates signal from noise.
Which ad libraries should I check for recent ads?
Check the three that cover where most competitors advertise: the Meta Ad Library for Facebook and Instagram, TikTok's ad resources for short-video creative, and Google's Ads Transparency Center for search, display, and YouTube. Each shows a different slice of a competitor's recent-ad footprint, so checking only one shows you only the testing that happens to live there. They are all free and authoritative, which is why they are the right starting point before any paid tool.
How often should I check for recent competitor ads?
Weekly, on a fixed day, for a focused list of five to ten competitors. The fixed cadence is what makes the survival check possible — you can only tell what persisted if you look at regular intervals — and a focused list is what makes the routine sustainable, because a list of thirty never gets checked. An hour a week on a short list, run consistently, builds a genuine read on your market's creative over a couple of months; erratic browsing of a long list does not.
Can ad libraries show me how much a competitor is spending?
No. Ad libraries show the creative, the rough timing, and often where an ad runs, but they do not publish spend, impressions, click-through rate, conversion rate, or ROAS. The survival check lets you infer that a surviving ad probably works for the advertiser, but inference is not measurement, and even a well-survived ad is a hypothesis, not a proven, profitable winner. Treat recency and survival as signals to prioritize what to study and test, never as a read on a competitor's budget or results.
How do I tell a competitor's test from a scaled campaign?
Read the public signals together. An early test usually looks like one or a few recently-launched ads in a single market with no variants. A scaled campaign usually looks like a creative that has survived a while, appears in several variants, and runs across multiple regions or placements with sustained investment. A test is an early-warning signal worth watching; a scaled campaign is a confirmed bet worth studying as a tested hypothesis. These are inferences from behavior, so hold them as probabilities and let the following weeks confirm or revise the read.
Should I act on a brand-new competitor ad right away?
Usually not. A brand-new ad is the weakest signal — one untested experiment among many — and its newness makes it feel more urgent than it is. The disciplined move is to note it and watch whether it survives, then escalate it into a test only once survival evidence accumulates. Acting immediately on every fresh launch means chasing your competitors' experiments, most of which they will abandon, a beat behind and with your own budget. Weight your attention toward survivors, not launches.
What should I save when I find a recent ad?
Save the advertiser, the launch timing, the format and angle, where it runs, and a one-line read on why it matters and whether it has survived. That provenance is what makes the survival check possible — you can only track whether an ad persisted if you recorded when you first saw it and what it was. A screenshot with no context cannot be tracked over weeks, which defeats the purpose of a freshness routine; the value is in following the same ads over time, and that requires saving with enough context to recognize them again.
When do I need a tool instead of the free ad libraries?
When the manual routine becomes the bottleneck. For two or three competitors on one platform, the free Meta, TikTok, and Google libraries are authoritative and entirely sufficient. You start to need a cross-network discovery layer when the routine spans many networks and competitors, when you need survival tracked over weeks without manual screenshots, or when findings have to become shareable reports for a team. The interpretation discipline — recent is not winning, survival is the signal — stays the same; the tool just removes the friction of doing it by hand at scale.
What is creative velocity and why should I track it?
Creative velocity is the rate at which a competitor launches, kills, and iterates on ads — a meta-signal you can only see by checking their library on a cadence over time. A high-velocity competitor launches many ads and iterates fast on the few that survive, so their survivors are unusually well-validated and their individual launches are pure noise; a low-velocity competitor changes slowly, so each launch weighs more but offers fewer survival signals. Reading velocity tells you how a competitor's creative engine works and whether they will out-iterate you — deeper intelligence than any single ad provides, and worth annotating in your survival log.
How does seasonality change how I read recent ads?
The calendar changes what "recent" means. Most advertisers flood new ads before high-demand seasons to find angles to scale, so a pre-season spike is expected and its individual launches are even weaker signals than usual — the survival check (which experiments persist into the peak) still carries the real signal. A quiet-season surge, against the grain, is more notable. Survival windows also compress during fast seasonal pushes, and post-season ad disappearances are usually normal culling, not a retreat. Annotate your log with the season so you can tell a seasonal experiment from a year-round bet.
Key Takeaways
- Find recent ads by advertiser-name search in the official Meta, TikTok, and Google libraries, filtered by country and active status, on a fixed weekly cadence across the platforms your competitors use.
- A recent ad signals intent, not success. The survival check — what is still running after two weeks, iterated into variants, or scaled across regions — is the real signal of a competitor winner, and it is the step most teams skip.
- Recency proves a launch, never performance. No ad library reveals spend or results, so even a well-survived ad is a strong hypothesis to test, not a proven winner to copy.
- Run a focused, consistent routine. Five to ten competitors, checked the same day each week, with findings saved in context, compounds into a real read on your market; erratic browsing of a long list does not.
- Add a cross-network discovery layer when manual checking is the bottleneck — one search across platforms, saved and tracked over time, with reports — it complements, never replaces, the recent-versus-winning interpretation discipline.
Sources
- Meta Ad Library — the public, free archive of active and recent ads across Facebook and Instagram, searchable by advertiser (as checked June 2026).
- TikTok Creative Center — TikTok's resources for recent and trending ad creative, browsable by region (as checked June 2026).
- Google Ads Transparency Center — recent and active ads across Google surfaces, searchable by advertiser and filterable by region and format (as checked June 2026).
Library features, filters, and coverage rules change often, so confirm current details on each platform's official pages before relying on them. All links checked as of June 21, 2026. Disclosure: AdMapix is our own product, and its data scope covers cross-network ad creative search, saved media, video analysis, tagging, and reports built on public evidence — separated from claims about each platform's own library.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Playable Ad Analysis for Mobile Games: A Practical Method
A practical method for playable ad analysis in mobile games: how to reverse-engineer a competitor's playable by the job it is built to do, decode its structure beat by beat, infer which concepts are likely working, turn observations into testable briefs, and stay honest about what a public playable proves (structure and intent) versus what it never can (spend, installs, retention, ROAS).

Best Mobile Game Ad Formats Across Platforms: A 2026 UA Playbook
A platform-by-platform guide to the best mobile game ad formats in 2026: which formats do the heavy lifting on Meta, Google, TikTok, AppLovin, and Unity; why the right format depends on platform, genre, and funnel stage; a format-selection framework; a creative-testing cadence; and the honest limits of what competitor ads can and cannot tell you about which format wins.

Meta Ads Library vs Ad Intelligence Tools for Game UA (2026): Which to Use, When, and Why
A definitive 2026 comparison of the Meta Ads Library vs dedicated ad intelligence tools for mobile game user acquisition — where the free transparency library genuinely helps, the structural limits that create blind spots for game UA creative research, a side-by-side capability matrix, the exact decision criteria for when to add a paid intelligence layer, and an honest account of what neither can show.