Atria Ad Library in 2026: What It Solves and What to Check Before You Buy
A 2026 buying-decision guide to the Atria ad library — what its AI-powered collect, summarize, and ideate stack actually does, the four criteria that decide whether it is worth paying for (channel coverage, filter speed, AI insight quality, and brief handoff), a test-before-you-buy method you can run in a trial, the honest limits of what any ad library can prove, and where it fits versus a cross-network creative-evidence layer.
By the AdMapix Research Team — Updated June 21, 2026
Atria Ad Library in 2026: What It Solves and What to Check Before You Buy
The Atria ad library is an AI-powered creative research tool that helps performance and creative teams collect competitor ads, spot patterns, and draft creative ideas. Whether it is worth paying for comes down to one practical test: does it cover the channels you actually buy, surface relevant examples in minutes, and hand those examples off into a brief your team can ship? This 2026 guide is for marketers evaluating Atria before a demo, weighing it against alternatives, or deciding whether to renew — and it focuses on the buying decision and how to test it, not on reciting a feature list. By the end you will know exactly what the Atria ad library solves, the four criteria that actually decide whether it earns its price for your team, how to test it in a trial before you pay, the honest limits of what any ad library can prove, and where a cross-network creative-evidence layer fits alongside it.
TL;DR — Evaluating the Atria Ad Library
- Judge the Atria ad library by four things, not by database size: channel coverage, filter and search speed, AI insight quality, and whether a saved ad actually becomes a testable brief.
- Do not buy on database size alone. A million ads in networks you do not run on is noise. Run three real competitor searches and try to write one evidence-backed brief before paying.
- The AI layer is the selling point and the risk. Atria's value appears only when its AI shortens the path from "here are 40 competitor ads" to "here is the angle we should test next." If it just restates what you can already see, you are paying for a nicer swipe file.
- It fits creative strategists and brand teams who live inside one or two networks and want AI-assisted ideation on top of saved ads.
- No ad library proves performance. Atria shows what competitors are running and helps you interpret it; it does not reveal their spend, ROAS, or whether an ad is profitable. Treat every insight as a hypothesis.
- A cross-network creative-evidence layer (such as AdMapix) complements it when you need broader cross-network discovery, saved media, video-level breakdowns, and shareable reports — not a like-for-like replacement for AI ideation.
What the Atria Ad Library Actually Does
Atria positions itself as an AI platform for ad insights, inspiration, and ideation — not just a static swipe folder — and understanding that positioning is the key to evaluating it honestly. In practice, the Atria ad library stacks three jobs together: it collects competitor ads, it uses AI to summarize patterns across those ads, and it helps turn observations into creative concepts. That bundling is simultaneously the selling point and the risk, and seeing why is most of the buying decision.
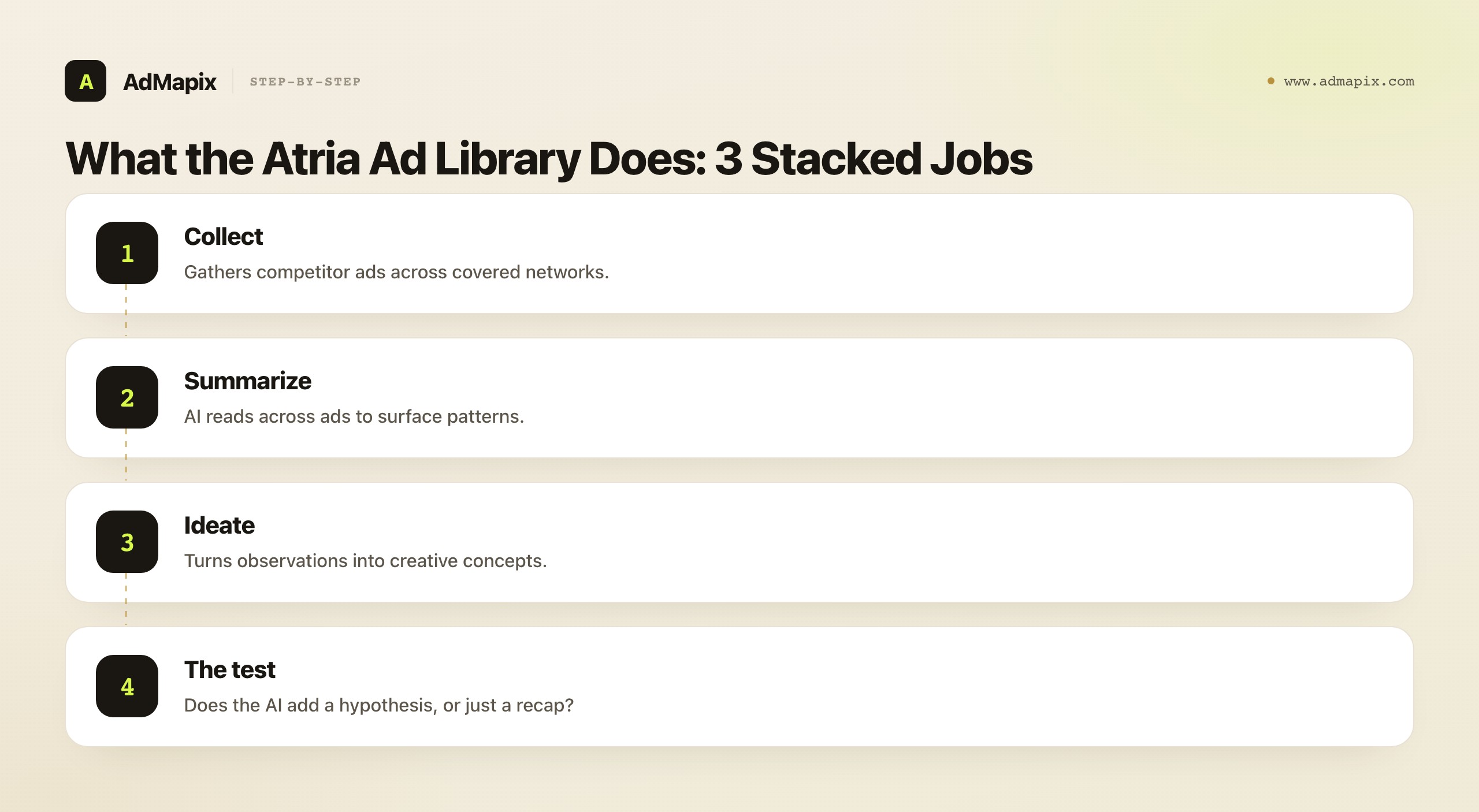
The value of the stack appears only when the AI layer genuinely shortens the path from "here are forty competitor ads" to "here is the angle we should test next." That is the promise: not just a place to save ads, but an assistant that reads across them and proposes a hypothesis you can act on. When the AI does that well, it compresses hours of manual pattern-spotting into minutes and changes what a creative researcher can get through in a week. When it does not — when the AI just restates what you can already see by looking at the ads yourself — you are paying a premium for a nicer swipe file, and a cheaper plain library would serve you as well. So the entire question of whether the Atria ad library is worth it turns on whether its AI layer adds a testable hypothesis or merely a polished recap.
This is why, before you book a demo, you should define the one weekly decision Atria has to improve. Creative research has three distinct bottlenecks, and they need different help: finding relevant examples faster, interpreting them into patterns, or producing briefs from them. A team whose bottleneck is finding examples needs coverage and filter speed above all. A team whose bottleneck is interpretation is exactly who the AI layer is built for. A team whose bottleneck is brief production needs the handoff from saved ad to usable concept to be frictionless. A tool that helps brilliantly with a step that is not your bottleneck is a cost, not a leverage point — so name your bottleneck first, and judge Atria against it rather than against its marketing page. The teams that are happiest with the Atria ad library are the ones whose actual constraint matched what the AI layer is good at; the teams that churn are usually the ones who bought it for a bottleneck it was never built to solve.
It is worth being precise about why the bundling of three jobs is a risk and not just a feature, because that framing is what protects you from overpaying. When a tool bundles collection, interpretation, and ideation, you pay one price for all three, and the price is set by the most valuable component — the AI. If your bottleneck is only collection (you just need ads in one place), you are buying the AI you do not need at the price it commands. If your bottleneck is only interpretation, the bundling is efficient because the AI is exactly the part you want. So the bundling is great value for the team whose constraint sits in the middle of the stack and poor value for the team that only needs the ends. This is the deeper reason "name your bottleneck first" is the whole decision: it tells you whether the bundle's price is aimed at the part you actually need. A team that buys the full collect-summarize-ideate stack to solve a problem that a plain swipe file would have solved is not getting a bad tool — they are getting a good tool aimed at the wrong job, at a price that assumes they need all of it.
There is also a maturity dimension worth naming. The AI ideation layer is most valuable to a team that already has a disciplined creative process and wants to go faster — they know how to read competitor structure and write briefs, and the AI compresses the time. It is least valuable, and sometimes actively misleading, to a team with no process, because such a team is prone to take the AI's output as a finished answer rather than a hypothesis to refine, and an AI that hands an inexperienced team confident-sounding conclusions can entrench bad decisions faster than manual research would. The Atria ad library, like any AI ideation tool, amplifies the process you already have rather than substituting for one you lack. If your creative process is strong, the AI makes it faster; if it is weak, the AI makes its weaknesses faster too. That is not a knock on the tool — it is a reason to be honest about your own maturity when judging whether the AI layer will be leverage or a liability.
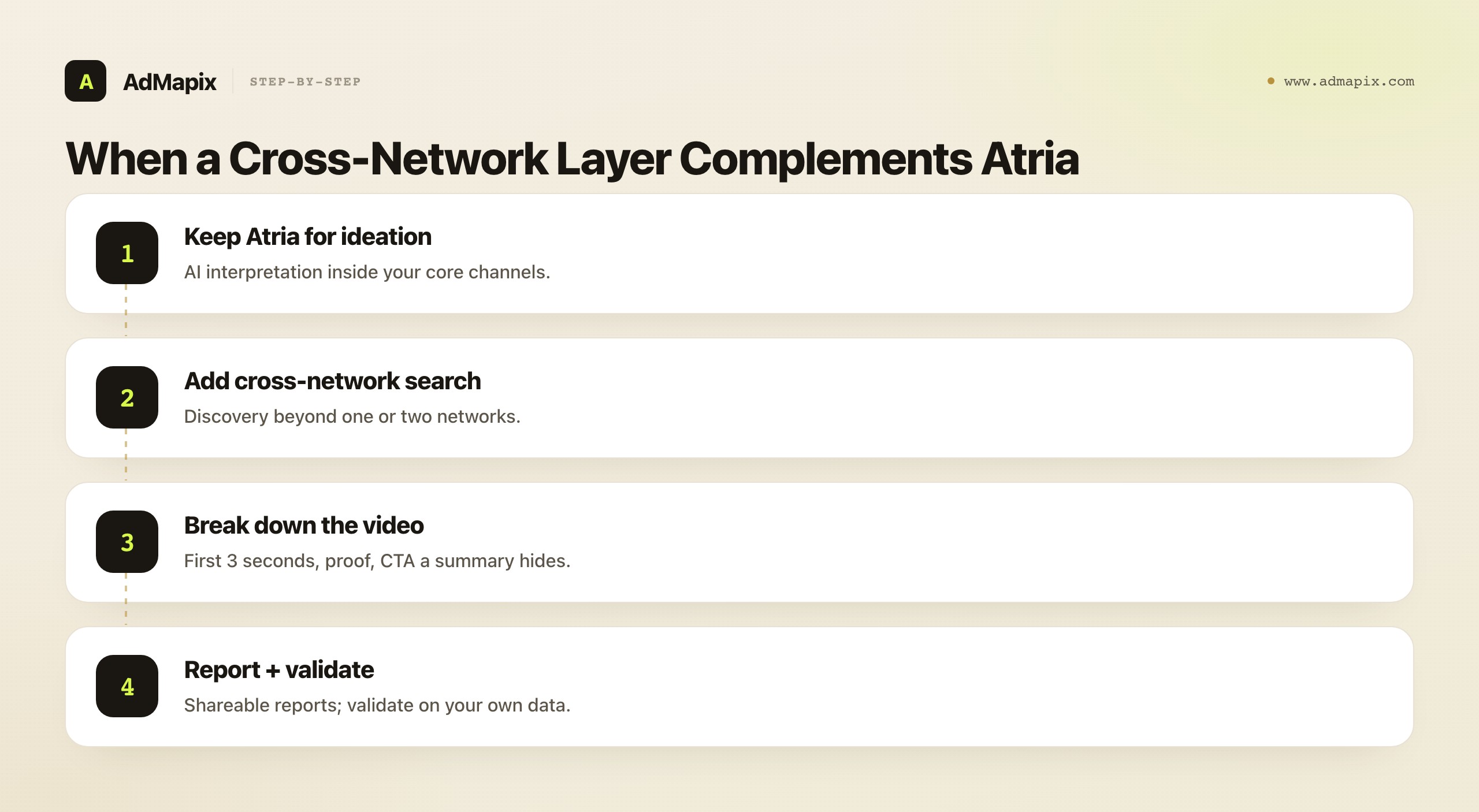
The Four Things to Check Before You Buy
Judge the Atria ad library against the bottleneck in your own creative process, not against a feature page. The four criteria below map directly to where teams lose time, and each one is something you can actually test in a trial rather than take on faith.

| Criterion | What to test | Good signal | Bad signal |
|---|---|---|---|
| Channel coverage | Do they index the networks, countries, and formats you buy? | Your core channels and recent ads are present | Strong on one network, thin everywhere else you spend |
| Search and filters | Can you find hooks, offers, and formats in minutes? | Three competitor searches return recent, diverse ads | You scroll for relevance instead of filtering to it |
| AI insight quality | Does the AI add a hypothesis, not just a recap? | Summaries name patterns you can test | Generic descriptions of what the ad shows |
| Brief handoff | Does a saved ad become a script, angle, or test? | Saved ads export into a usable concept | Insights stay trapped in screenshots |
Channel coverage is the gating criterion, because a tool that is thin where you spend fails on day one regardless of its other strengths. Do not ask "how many ads does it have" — ask "does it return recent, relevant ads for the specific networks, countries, and formats I actually buy on." Run that test before anything else in a trial, because no AI brilliance compensates for not having the ads you need to see. A library that is deep on one network and thin everywhere else you spend is the wrong tool for a multi-channel team, no matter how good its summaries are.
Search and filter speed is where teams quietly lose hours. The test is concrete: run three real competitor searches and time how long it takes to get from the search to recent, diverse, relevant ads. A good library filters you to relevance — you specify the hook, offer, or format you want and it surfaces it. A weak one makes you scroll through volume hoping to spot relevance, which is the swipe-file problem with a search box bolted on. If finding examples is your bottleneck, this criterion is the one that matters most, and it is easy to test directly.
AI insight quality is the criterion that decides whether you are buying an AI platform or an expensive library, and it is the hardest to evaluate but the most important for Atria specifically. The test is whether the AI adds a hypothesis you can test, not a recap of what the ad shows. "This ad shows a product demo with a discount" is a recap — you could see that yourself. "This advertiser keeps pairing a problem-agitation hook with a social-proof close across their winning-looking ads, which is a structure worth testing against our current creative" is a hypothesis — it names a pattern and points at an action. Push the AI hard in a trial on your real competitors and judge which kind of output it gives. If it consistently produces hypotheses, the AI layer is earning its premium; if it produces recaps, you are paying for polish.
Brief handoff is the criterion that determines whether the research ever becomes a result. The test is whether a saved ad turns into a script, an angle, or a test brief your team can actually ship, or whether insights stay trapped in screenshots that die in a folder. The whole point of the collect-summarize-ideate stack is to end in a shippable concept; if the handoff is frictionless, the tool compounds your output, and if saved ads just accumulate, you have bought a more expensive way to hoard screenshots. Test the full path in a trial — search, save, interpret, and try to produce one real brief — because that end-to-end run is the truest measure of whether the tool fits your workflow.
Why Database Size Is the Wrong Way to Compare
The most common buying mistake is comparing ad libraries by database size while ignoring relevance, and it is worth a section because the instinct is so strong and so wrong. "Biggest library" is a marketing metric that sounds decisive and decides nothing.
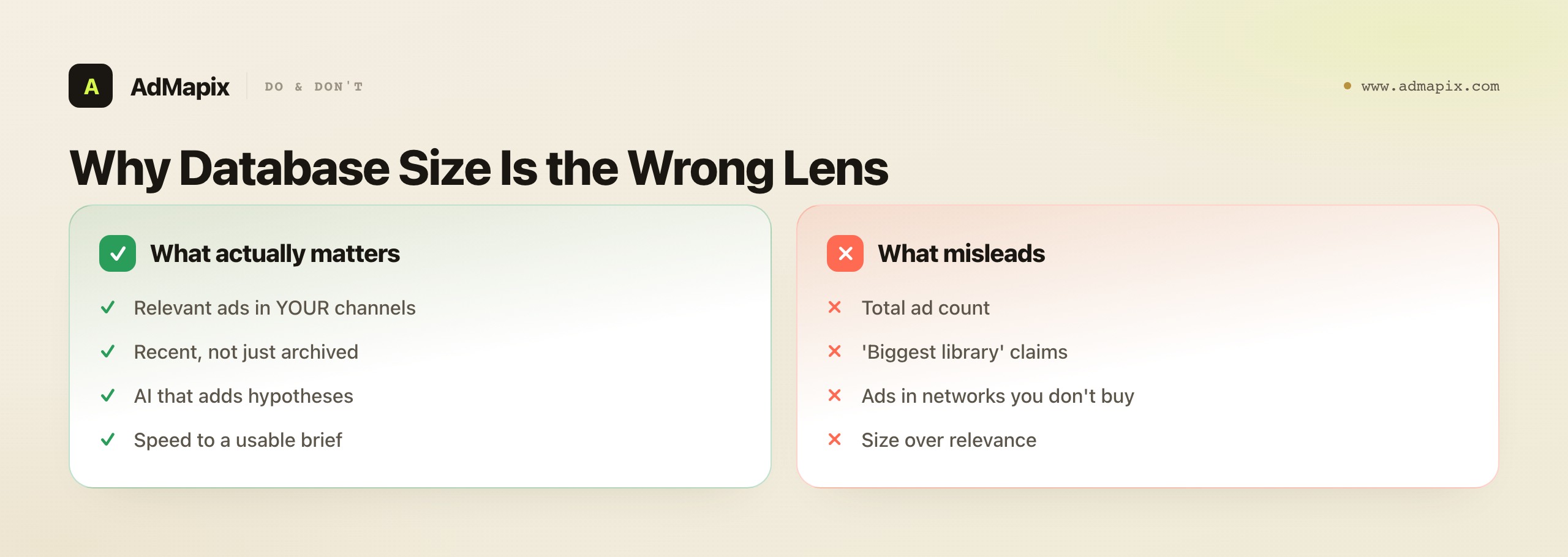
Here is why size misleads. A library with ten million ads, of which a few thousand are in the networks, countries, and verticals you actually buy on, is functionally smaller for you than a library with two million ads that happen to be concentrated where you work. Relevance, not raw count, determines how useful a library is to a specific team, and relevance is local — it depends entirely on your channels and your verticals, which no global ad count captures. When a vendor leads with database size, they are answering a question that does not determine your outcome, and a buyer who picks on that number is optimizing the wrong variable. The right question is never "which has more ads" but "which returns more relevant, recent ads for my specific situation, faster" — and the only way to answer it is to run your own real searches in a trial, not to compare headline numbers on pricing pages.
There is a second reason size is the wrong lens for the Atria ad library specifically: Atria's pitch is not "the most ads" but "the best AI-assisted interpretation and ideation." A team that evaluates Atria on database size is judging it on the dimension it does not compete on while ignoring the dimension it does. If Atria's AI layer genuinely turns saved ads into testable hypotheses faster than you could manually, that is its value, and it is worth more than a larger library that hands you raw ads with no interpretation. Conversely, if the AI does not add that interpretation for your use case, no amount of library size redeems it. Evaluate Atria on what it claims to be — an interpretation-and-ideation layer — and the size question mostly falls away. The two real questions are "does it cover my channels" (a relevance question, not a size one) and "does its AI add testable hypotheses" (the dimension it actually competes on).
How to Run a Real Trial Before You Pay
The single best thing you can do before buying the Atria ad library is run a structured trial against your own situation, because thirty minutes of real testing tells you more than any demo or feature comparison. Here is exactly how to run it so you get a decision, not just an impression.
Start by writing down, before you open the tool, the one weekly decision you need it to improve and the bottleneck behind it — finding, interpreting, or producing. This is your evaluation lens; without it, you will be charmed by whatever the tool demos well rather than judging it on what you need. Then run the coverage test first: search three to five real competitors you actually track, in your real networks and countries, and check whether the library returns recent, relevant ads. If it comes up thin here, stop — coverage is the gate, and no other strength compensates for missing the ads you need to see.
If coverage passes, test the filter speed and the AI in one motion. Take one of those competitors and try to get from "show me their ads" to "here are the three hooks or angles they keep using" as fast as possible, using the filters and the AI summaries. Time it, and judge the AI's output on the recap-versus-hypothesis test: did it name a pattern you can act on, or describe what you already saw? Then close the loop by trying to produce one real brief — an angle, a script direction, or a test concept — from what you found, and notice how much friction that handoff carried. A tool that took you from real competitors to a shippable brief in one short session, on your channels, is demonstrating exactly the value it would provide every week. A tool that returned thin coverage, made you scroll for relevance, recapped instead of hypothesized, or trapped insights in screenshots has shown you its limits before you paid for them.
The discipline that makes this trial decisive is testing the whole path on your real situation, not sampling features in isolation. Many tools demo beautifully on a curated example and disappoint on your actual competitors and channels; a few are the reverse. The only way to know which you are dealing with is to run your real searches and try to produce your real output. Verify current plans, trial terms, and limits on Atria's pricing page before you commit, since these change, and treat the trial — not the demo — as the real evaluation. The demo shows you the tool at its best; the trial shows you the tool at your job.
A few specifics make the trial sharper. First, pick competitors at different scales — one high-volume advertiser with many ads running and one thinner one — because the AI's interpretation quality often varies with how much creative it has to read across. A tool that produces good hypotheses for a high-volume advertiser but only recaps for a thin one is telling you something about where it will and will not help, and your real research includes both kinds of competitor. Second, deliberately try to break the coverage by searching a network or country at the edge of where you spend, not just your core — because the gaps that hurt are usually at the edges, and a tool can look fully covered on your main channel while being thin on the secondary one you also need. Third, time yourself honestly and compare against your current process: if the tool gets you to a brief faster than you do today, that delta is the value; if it does not, the AI premium is not buying you speed where you need it.
Finally, involve the person who will actually use it daily in the trial, not just the person making the purchasing decision. Creative tools live or die on daily-use texture — whether the filters feel fast, whether the AI output is trusted by the strategist who has to act on it, whether the brief handoff fits how the team already works. A tool that the buyer finds impressive in a demo but the daily user finds frustrating in practice will not get used, and an unused subscription is the most expensive outcome of all. The trial is your one chance to surface that mismatch before you pay, so put the tool in the hands of the people whose weekly workflow it has to improve, and weight their verdict heavily. Their lived reaction over a few real sessions is worth more than any feature comparison or demo impression.
What the AI Ideation Can and Cannot Write For You
A specific question worth addressing, because it is where expectations of AI ideation tools most often misalign with reality: what can the AI layer actually produce, and where does the human still have to do the work? Getting this right prevents both over-reliance and under-use.
The AI is genuinely good at the convergent parts of creative research — reading across many ads to find what recurs, naming the structures and patterns, and drafting a first-pass concept or angle from them. These are tasks where the input is a body of existing creative and the output is a synthesis, and AI excels at synthesis across a corpus faster than a human can. So "summarize the hooks this advertiser keeps using," "draft three angle directions based on the patterns across these saved ads," and "what structure do the competitors' apparent winners share" are tasks the AI can genuinely accelerate. Used here, the AI is doing real work that compresses hours into minutes, and that is its legitimate value.
Where the AI is weaker is the divergent and judgment-laden parts — the creative leap to a genuinely novel angle that no competitor is running, the brand-voice nuance that makes a concept feel like yours rather than a remix, and the strategic judgment of which hypothesis is worth your limited testing budget given everything you know about your audience and offer that the AI cannot see. The AI can hand you a strong, derivative starting point built from what already exists; the distinctive creative and the strategic prioritization are still human work. This is not a flaw to hold against the tool — it is the correct division of labor. The teams that get the most from AI ideation use it to clear the convergent work fast so their human creativity has more room for the divergent work, rather than expecting the AI to do the whole job. Expecting the AI to produce the breakthrough creative leads to bland, derivative output and disappointment; using it to accelerate the synthesis so you can spend your energy on the leap is exactly the leverage it offers. Calibrate your expectations to "fast, strong starting points" rather than "finished, original creative," and the AI ideation layer becomes a genuine multiplier instead of a letdown.
What an Ad Library Can and Cannot Prove
Before you lean on any insight the Atria ad library surfaces, separate what it can prove from what it cannot — because the line between observable creative and inferred performance is exactly the line between credible research and guesswork, and an AI layer can blur it if you are not disciplined.
Provable from an ad library: the creative itself — the hook, the format, the copy, the offer angle — the advertiser, and often the run dates and the landing destination. These are observable facts you can record and build on. Not provable: the spend behind the ad, the click-through rate, the conversion rate, the return on ad spend, the targeting, or whether the campaign is profitable. None of that is in the library, because advertisers do not publish it, and no ad library — AI-powered or not — can infer it reliably. This matters for Atria specifically because the AI layer is so good at producing confident-sounding summaries that it is easy to read an AI insight as if it carried performance data it does not have. When the AI says "this advertiser's top creative is a problem-agitation hook," remember that "top" is its inference from visible signals, not a measurement of the advertiser's actual results — the AI can identify a pattern, but it cannot see the spend or ROAS behind it any more than you can.
So treat every insight, including the AI's, as a hypothesis. "This structure repeats across the advertiser's ads" is a strong, testable observation — strong because repetition is a meaningful signal, but still an observation about what is running, not proof of what is winning. The AI's value is in spotting and articulating these patterns faster than you could manually, not in knowing which ones convert. Validate every borrowed pattern against your own ad account and conversion data before you scale spend behind it. The teams that get the most from an AI-assisted library are the ones who use it as a hypothesis generator and keep their own performance data as the judge of truth; the teams that get burned are the ones who read an AI summary as if it were a verdict on a competitor's profitability it could never actually measure. The AI accelerates the research; your own numbers still decide what worked.
There is a specific way AI-powered libraries can quietly amplify a classic research error: the longevity-and-frequency trap. The AI, reading across an advertiser's ads, may flag a creative as a likely winner partly because it has been running a long time or appears across many placements — and those are exactly the signals a human researcher over-trusts too. But longevity and frequency are weak proxies for performance: an ad can run for months at a loss while an advertiser tries to fix the surrounding economics, and frequency reflects budget and strategy as much as success. When the AI elevates a long-running, frequently-placed creative to "top" status, it is making the same inference you might, with the same limits — it cannot see whether that ad is actually profitable, only that it persists. So the AI's confidence about which creative is "winning" inherits the weakness of the visible signals it reads, and should be held to the same skepticism. A long-running ad the AI flags is a reasonable place to look, not a proven winner to copy.
This connects to the saturation caution that applies to all competitor research and that an AI can inadvertently push you toward. The patterns the AI most readily surfaces are, by construction, the ones that appear most across the corpus — the loud, frequent, widely-run structures. But the loudest patterns are often the most saturated, the ones every competitor (and every other Atria user looking at the same advertisers) has already noticed and is already copying. The early advantage in those patterns is frequently gone. The disciplined use of an AI library is therefore to look past the most-obvious surfaced pattern toward the quieter, earlier signals — the structure appearing on one or two advertisers but not yet everywhere, the angle that is gaining but not yet dominant. The AI is excellent at finding what is common; the edge often lies in what is emerging, and that requires reading the AI's output with an eye for the early signal rather than just accepting the loudest pattern it reports. Use the AI to map what is common, then deliberately hunt the edges of that map for what is not yet crowded.
Who the Atria Ad Library Is Right and Wrong For
It is easy to make any tool sound right for everyone, so it is more useful to be specific about who the Atria ad library fits and who should look elsewhere — because the clearest path to a good buying decision is recognizing whether you are the right buyer.
Atria fits creative strategists and brand teams who live inside one or two networks and whose bottleneck is interpretation and ideation rather than raw discovery. If your job is to look at competitor creative and figure out what to test next, and you want an AI layer that helps you read patterns and draft concepts faster, that is precisely what the collect-summarize-ideate stack is built for. It also fits a team that ships a high volume of creative and needs to compress the research-to-brief cycle, because the time the AI saves on interpretation compounds across many briefs. For these teams, the AI premium is the value, not the cost.
Atria is the wrong buy for a few clear profiles. It is wrong for a team whose bottleneck is pure discovery across many networks, who needs the broadest possible cross-network coverage more than AI interpretation — that team is better served by a tool optimized for cross-network breadth. It is wrong for a team that only needs a cheap place to save and organize ads, with no need for AI ideation, because they would be paying the AI premium for a feature they will not use. And it is wrong for a team that needs hard performance intelligence — spend, ROAS, share of voice — because no creative ad library, however AI-powered, provides that; that is a different category of tool entirely. Recognizing yourself in a wrong-fit profile is more valuable than any feature list, because it saves you from paying for a tool that was never built for your job. The right buying decision starts with honestly placing yourself, then running the trial to confirm the fit.
A useful way to place yourself is to look at how your team currently spends its creative-research time, broken into the three steps. If most of the time goes to hunting for relevant ads — opening libraries, scrolling, trying to find what competitors are running across your channels — your bottleneck is discovery, and an AI ideation layer fixes a step that is not your problem. If most of the time goes to staring at a folder of saved ads trying to figure out what they mean and what to do, your bottleneck is interpretation, and that is precisely the step Atria's AI is built to compress. If most of the time goes to translating insights into briefs that the creative team can build from, your bottleneck is production, and you should test the handoff hard. Most teams have a dominant bottleneck even if they feel all three; the dominant one is what should drive the decision. A team that honestly audits its time usually discovers its bottleneck is more specific than "we want better creative research," and that specificity is what makes the buying decision clear.
There is also a team-size and structure angle worth considering. The AI ideation layer tends to pay off most for small-to-mid creative teams who are doing the research-to-brief work themselves and are time-constrained — the AI effectively adds capacity to a team that cannot hire its way to faster interpretation. For a very large organization with dedicated creative researchers and analysts, the calculus is different: those specialists may already produce hypothesis-level interpretation manually, and the AI's marginal value is smaller, while the cross-network coverage and reporting needs of a big team may be larger. So the same tool can be high-leverage for a lean team and a modest add for a large one — not because the tool changes, but because what it replaces (manual interpretation time) is scarcer and more valuable on a small team. Factor your team's size and how it spends research time into the fit judgment, not just the feature checklist.
A Workflow That Gets Value From Any Ad Library
Whichever ad library you choose, the workflow that turns it into results is the same. A tool only pays off if your process forces every saved ad to become a decision, and that discipline matters more than which library you buy.
- Name the decision first. Finding examples, interpreting patterns, or producing briefs are different jobs. Write down which one this session is for before you open the tool.
- Search your real competitors and channels. Use the same three to five real advertisers in your real networks and date window, so what you find reflects your market, not the tool's showcase.
- Read for structure, not just surface. Tag the hook, the offer, the format, and the conversion logic — the transferable structure — not just what the ad depicts.
- Save with context. Keep the ad, the advertiser, the date, the pattern, and a one-line note on why it matters and what to test. Provenance is what makes the saved ad usable next month.
- Force a brief, then validate. Every saved ad should become an angle, a script, or a test — and your own performance data, not the library or its AI, decides whether the borrowed pattern actually works.
The discipline is in steps 3 through 5, and it is what separates teams that compound their research from teams that hoard screenshots. An AI layer like Atria's can accelerate step 3 (reading for structure) and step 5's setup (drafting the brief), which is exactly where its value lives — but it cannot replace step 5's validation, because only your numbers prove a pattern works. Use the AI to move faster through interpretation and ideation, keep your own data as the judge, and the library compounds into better creative over time. Skip the discipline and even the best AI-assisted library produces a folder of well-summarized ads nobody ships.
One practical addition to this workflow makes the AI specifically more valuable: feed your own results back into how you read the AI's future output. When you test a pattern the AI surfaced and it wins — or loses — for your offer, you learn something about which kinds of AI hypotheses are reliable for your specific audience and economics. Over a few cycles, you build a calibrated sense of which of the AI's pattern-types tend to translate into real wins for you and which tend to be mirages, and you can weight its future suggestions accordingly. This closes the loop between the AI's hypothesis generation and your validated reality, and it is where an AI ideation tool becomes genuinely smarter for your team over time — not because the AI learns, but because you learn how to read it. A team that runs this loop turns the AI from a generic pattern-spotter into a tuned instrument calibrated against their own results, which is the highest-leverage way to use any AI ideation layer: not as an oracle to obey, but as a hypothesis engine whose output you have learned to weight against your own hard-won data.
Judging the AI Layer in Depth: Recap vs Hypothesis
Because the AI layer is the entire reason to pay a premium for the Atria ad library over a plain swipe file, it deserves a deeper look at how to judge it well — because the difference between an AI that earns its keep and one that does not is subtle enough that many buyers cannot tell which they are evaluating until after they have paid.
The cleanest test is the recap-versus-hypothesis distinction, but it helps to have a graded sense of AI output quality rather than a binary. At the bottom is pure description: "this ad is a 15-second video with a discount and a product demo." That is something you could see in two seconds yourself, and an AI that mostly produces it is adding nothing but words. One level up is aggregation: "across this advertiser's ads, discounts appear in 60% of them." That is mildly useful — it summarizes volume — but it still does not tell you what to do. The level that earns the premium is hypothesis: "this advertiser consistently pairs a problem-agitation opening with a social-proof close in the ads they appear to be scaling, which is a structure your current creative does not use and is worth testing." That output names a transferable pattern, contrasts it with your situation, and points at an action. An AI that reliably produces hypothesis-level output is doing real interpretive work; one stuck at description or aggregation is not, however fluent it sounds.
The trap is that fluent description reads like insight. Modern AI writes confidently and smoothly, so a recap dressed in good prose can feel like analysis when it is not. The defense is to ask, after every AI summary, "could I have produced this just by looking at the ads myself, in about the same time?" If yes, it is a recap, no matter how well-written. If the AI genuinely surfaced a pattern across many ads that you would have taken much longer to spot, or connected the competitor's structure to a gap in your own creative, it is doing the interpretive work you are paying for. Run this test repeatedly in a trial, on your real competitors, because the quality of AI interpretation varies by vertical and by how much creative an advertiser has running — an AI might produce hypotheses beautifully for a high-volume advertiser and only recaps for a thin one. Judge it across several real cases, not one curated demo, and weight the cases that look like your actual research.
One more nuance: even excellent AI interpretation is a hypothesis generator, not an oracle. The best possible AI output is "here is a strong, specific pattern worth testing," and the word "testing" is load-bearing. The AI cannot know whether the pattern converts for your offer and audience, because it cannot see the competitor's results or yours. So the right way to value the AI is as a faster path to better hypotheses, which still have to be validated against your own data. A team that treats the AI's best output as a tested conclusion will scale patterns that were never proven; a team that treats it as a high-quality hypothesis to validate will move faster than manual research while keeping their own numbers as the judge. The AI's job is to get you to a better starting hypothesis sooner; your job is still to run the test.
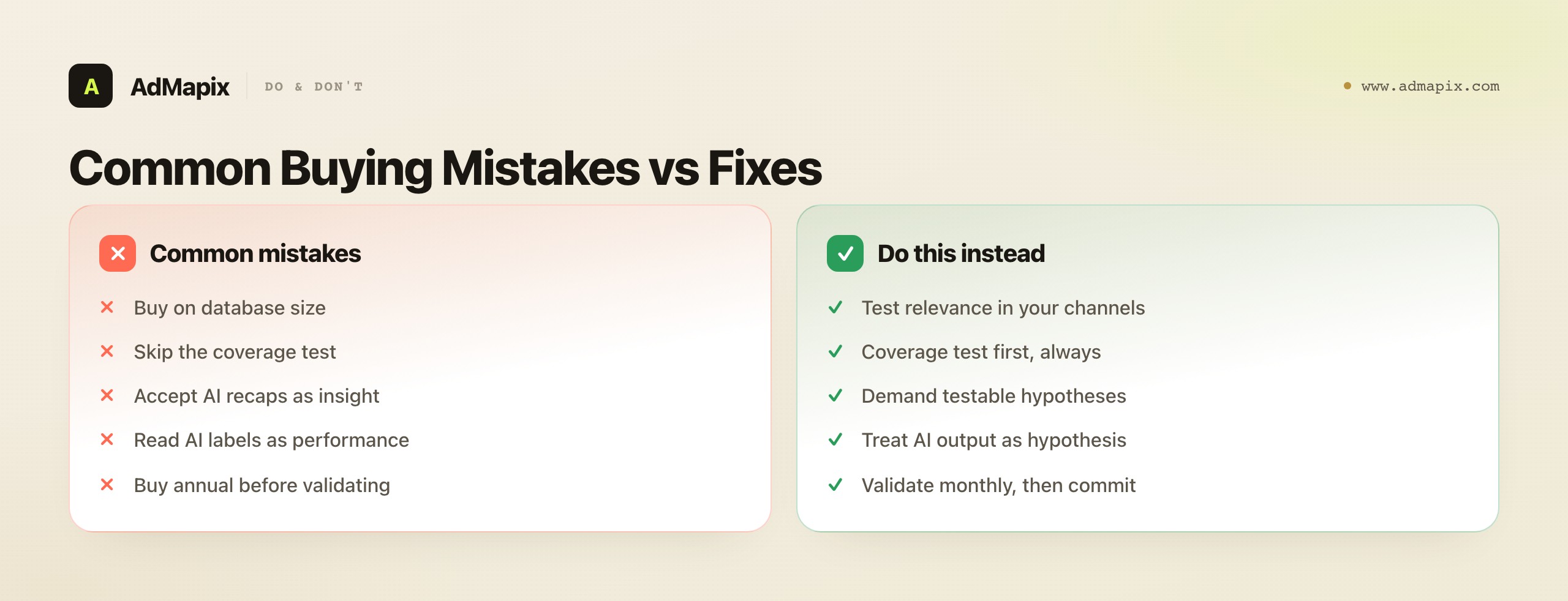
Common Mistakes When Evaluating the Atria Ad Library
Most buying regret with AI-powered ad libraries traces back to a few avoidable evaluation errors.
- Buying on database size. Size is a marketing metric that decides nothing. A huge library thin in your channels is smaller for you than a focused one. Test relevance in your real networks, not headline counts.
- Skipping the coverage test. Coverage is the gate. A tool that does not return recent, relevant ads for the networks you buy on fails on day one, no matter how good its AI is. Test it first, before anything else.
- Mistaking AI fluency for insight. A well-written recap is still a recap. Ask whether the AI produced a hypothesis you can act on or just described what you could already see, and judge it on that.
- Reading AI labels as performance data. "Top creative" or "winning ad" in an AI summary is an inference from visible signals, not a measurement of spend or ROAS. Treat it as a hypothesis, never a verdict on a competitor's results.
- Evaluating on a curated demo instead of a real trial. Demos show the tool at its best on its examples; trials show it on your competitors and channels. Always test your real situation, not the showcase.
- Buying for the wrong bottleneck. A tool that helps brilliantly with a step that is not your constraint is a cost, not leverage. Name whether your bottleneck is finding, interpreting, or producing, and judge Atria against that.
- Committing annually before validating. Annual discounts lock you into a fit you have not confirmed. Validate monthly on your real work, then commit for the discount once the fit is proven.
The two costliest errors are the third and the fourth: mistaking fluency for insight, and reading AI labels as performance data. They share a root — over-trusting confident-sounding AI output. The discipline that prevents both is the same: judge the AI on whether it produces testable hypotheses rather than polished descriptions, and remember that no AI summary, however confident, can see a competitor's spend or ROAS. Hold that line and the AI accelerates genuinely good research; drop it and it produces a faster path to confident, expensive mistakes.
When a Cross-Network Creative-Evidence Layer Helps
The Atria ad library is built around AI-assisted ideation inside the networks it covers. When the missing piece is something else — broad cross-network discovery, saved media you can search later, video-level structure breakdowns, and shareable reports — a gap opens that an ideation-focused library is not built to close.
A cross-network creative-evidence layer like AdMapix fits here, as a complement rather than a replacement. It is built for teams that need to search ad creatives across networks with Search, save the media in Media, break down video structure and hooks with Video Analysis — the first three seconds, the proof, the CTA that a static summary cannot show — tag what they find, and turn it into a Report. The reason this is a separate layer rather than something an ideation tool should absorb is that the jobs differ in kind: Atria's stack is organized around interpreting and ideating on creative within its coverage, while a cross-network evidence layer is organized around finding, saving, dissecting, and reporting creative across many networks. A team whose competitors run across Meta, TikTok, YouTube, and beyond often wants both — the AI ideation for the interpretation step, and the cross-network layer for the discovery, video analysis, and reporting steps. Compare access on Pricing once the workflow repeats, or log in to run your first cross-network search.
It is honestly not the right tool if all you need is AI-assisted ideation on top of ads in one or two networks — that is exactly what the Atria ad library is built for, and a cross-network layer would be breadth and reporting capacity you do not use. A cross-network creative-evidence layer earns its place specifically when discovery has to span many networks, when creatives have to become searchable saved media with video analysis, and when findings have to become shareable reports for a team or client. Name the gap first: AI ideation inside your core channels points to the Atria ad library; cross-network discovery, saved media, video breakdowns, and reports point to a layer like AdMapix — and many teams that work across channels end up wanting one of each.
The reporting dimension is worth drawing out, because it is the job most often discovered to be missing after a team has already bought an ideation tool. AI ideation is fundamentally a researcher's tool — it helps the individual reading competitor creative move faster from ads to a concept. But the moment that research has to leave the researcher's head and become a shared artifact — a report a client signs off on, a deck that justifies a creative direction to leadership, an archive a new hire can learn from — the constraint shifts from interpretation to communication and preservation, and an ideation tool is not built for that shift. A cross-network layer with saved searchable media, tagging, and reports is built for exactly the multiplayer job of turning one person's research into the team's durable, shareable knowledge. So a team that does its creative research solo and ships briefs internally may never feel this gap, while an agency that has to defend recommendations to clients every week will feel it constantly. If reporting and shareability are part of your job, weigh that explicitly, because it is a need an AI ideation library is structurally not designed to meet, however good its interpretation is.
The video-analysis dimension is the other commonly-missed piece, and it matters more as creative shifts toward video across networks. AI summaries of a video ad can describe what it shows, but the structure of a video — the first three seconds that earn the watch, the proof beat, the pacing, the CTA — is a distinct analytical object that a text summary flattens. A team that competes on video creative often needs that structural breakdown, and a cross-network layer that treats the video as a first-class object to dissect provides something an ideation summary does not. None of this makes the Atria ad library worse at its job; it simply marks the edges of that job. The clean mental model is three questions: "what should we test next?" (Atria's AI ideation), "what are competitors running across all our networks, saved and searchable?" (cross-network discovery), and "how is this video built, and how do we report it?" (video analysis and reporting). The first is Atria's home turf; the second and third are where a complementary layer earns its place. Most cross-channel teams end up wanting answers to all three, which is why the realistic picture is a stack, not a single winner.
For the broader landscape, our guide to the best ad spy tools of 2026 compares the whole field by price, coverage, and use case. If you are weighing Atria against specific competitors, the Atria alternatives guide covers what else fits the AI-ideation niche, and the Atria vs Foreplay and Atria vs MagicBrief breakdowns compare Atria head-to-head with the closest creative-research tools. For building a durable creative archive, ad creative database goes deeper.
FAQ
What is the Atria ad library?
The Atria ad library is an AI-powered creative research tool that collects competitor ads, uses AI to summarize patterns across them, and helps turn those observations into creative concepts. It positions itself as a platform for ad insights, inspiration, and ideation rather than a static swipe folder. Its value depends on whether its AI layer genuinely shortens the path from saved competitor ads to a testable creative angle — if it does, it is an ideation platform; if it only recaps what you can already see, it is an expensive library.
Is the Atria ad library worth paying for?
It depends on whether your bottleneck matches what it does best. Judge it on four things: does it cover the channels you actually buy, does it surface relevant ads in minutes, does its AI add testable hypotheses rather than recaps, and does a saved ad become a shippable brief? If your bottleneck is interpreting competitor creative and producing concepts, and it passes those tests on your real competitors in a trial, it is worth it. If your bottleneck is pure cross-network discovery or you only need a cheap swipe file, it likely is not.
How should I evaluate the Atria ad library before buying?
Run a structured trial, not just a demo. Write down the one weekly decision you need it to improve, then test coverage first by searching three to five real competitors in your real networks. If coverage passes, time how fast you can get from a search to the patterns that matter, judge whether the AI produces hypotheses or recaps, and try to produce one real brief from what you find. A tool that takes you from your real competitors to a shippable brief in one short session is demonstrating its weekly value; one that fails on coverage, relevance, or interpretation has shown its limits before you paid.
Should I compare ad libraries by database size?
No. Database size is a marketing metric that sounds decisive and decides nothing. A huge library that is thin in your networks and verticals is functionally smaller for you than a smaller one concentrated where you buy. Relevance, not raw count, determines usefulness, and relevance is local to your channels. Compare libraries by whether they return relevant, recent ads for your specific situation, faster — which you can only judge by running your own real searches in a trial, not by comparing headline numbers.
Does the Atria ad library show competitor spend or ROAS?
No. Like any creative ad library, Atria shows observable creative — the hook, format, copy, offer, advertiser, and often run dates and landing page — but it does not reveal a competitor's spend, click-through rate, conversion rate, ROAS, targeting, or profitability. That data is not published. Its AI can identify and articulate patterns in what is running, but "top" or "winning" in an AI summary is an inference from visible signals, not a measurement of actual results. Treat every insight as a hypothesis and validate against your own performance data.
What does the AI layer actually add over a normal swipe file?
The AI layer's promise is to read across many saved ads and surface a testable pattern faster than you could manually — turning "here are forty competitor ads" into "here is the structure they keep using that we should test." When it does that well, it compresses hours of pattern-spotting into minutes. When it does it poorly, it just restates what you can already see, and you are paying a premium for polish. The test is whether its output is a hypothesis you can act on or a recap of what the ad shows — push it hard on your real competitors in a trial to find out.
Who is the Atria ad library best for?
Creative strategists and brand teams who live inside one or two networks and whose bottleneck is interpretation and ideation rather than raw discovery. If your job is reading competitor creative to decide what to test next, and you want an AI layer to help you spot patterns and draft concepts faster, that is what it is built for. It is also a fit for high-volume creative teams who need to compress the research-to-brief cycle. It is a weaker fit for teams needing the broadest cross-network discovery, a cheap save-only library, or hard performance metrics.
Can a cross-network tool like AdMapix replace the Atria ad library?
Not as a like-for-like AI-ideation replacement. A cross-network creative-evidence layer like AdMapix is built for broad cross-network discovery, saved searchable media, video-level structure breakdowns, and shareable reports — a different set of jobs from AI-assisted ideation inside one or two networks. Teams that depend on Atria's AI interpretation will keep it for that step. The realistic picture is complementary: Atria for AI ideation within your core channels, and a cross-network layer for the discovery, video analysis, and reporting that span more networks.
How do I turn Atria insights into actual results?
Force every saved ad and AI insight into a decision. Search your real competitors, read for transferable structure rather than surface, save with context (the pattern, the date, why it matters, what to test), draft a brief, and then validate the borrowed pattern against your own ad account and conversion data before scaling. The AI accelerates the interpretation and the first draft of the brief, but only your performance data proves whether a pattern works. Insights that never become briefs, and briefs that never get validated, are where the tool's value leaks away.
Should I buy Atria annually to save money?
Not before validating it on a monthly or trial plan first. Annual discounts look attractive until you are locked into a tool whose coverage or AI fit turns out not to match your job. Run the trial on your real competitors and channels, confirm it passes the four criteria for your specific bottleneck, and only then commit to annual for the discount. Verify current plans, trial terms, and limits on Atria's official pricing page before deciding, since tiers and features change — and treat value per job, what it costs to get the outcome you need, as the real measure rather than a headline price you read in a comparison.
Key Takeaways
- Judge the Atria ad library on four criteria — channel coverage, filter speed, AI insight quality, and brief handoff — against your own bottleneck, not against a feature page or a database-size claim.
- The AI layer is the value and the risk. It earns its premium only when it turns saved ads into testable hypotheses faster than you could manually; if it only recaps, you are paying for polish.
- Run a structured trial, not just a demo. Test coverage first on your real competitors, then time the path to a brief and judge the AI on the recap-versus-hypothesis test before you pay.
- No ad library proves performance. Atria shows what is running and helps interpret it; it does not reveal spend, ROAS, or profitability. Treat every insight, including the AI's, as a hypothesis to validate against your own data.
- Add a cross-network creative-evidence layer when the gap is discovery, video analysis, or reporting — it complements, never replaces, AI-assisted ideation inside your core channels.
Sources
- Atria — AI-powered ad research platform for collecting competitor ads, summarizing patterns, and ideating creative concepts (as checked June 2026).
- Atria pricing — current plans, trial terms, and limits; verify before purchase, since tiers and features change.
- Meta Ad Library — the public, free baseline for what is observable in a creative ad library, useful as a coverage and relevance reference point (as checked June 2026).
Plan names, tiers, trial terms, and features change often, so confirm current details on Atria's official pages before deciding. All links checked as of June 21, 2026. Disclosure: AdMapix is our own product, and its data scope covers cross-network ad creative search, saved media, video analysis, tagging, and reports — separated from claims sourced to Atria's own pages.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles
Outbrain Ad Spy Tool in 2026: Native Ad Research for the Open Web
How to research Outbrain native ads from public evidence in 2026 — what a spy tool can and cannot prove, how to decode headline-and-thumbnail hooks, advertorial landing paths, retargeting trails, and how to turn patterns into testable native campaigns.

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.

AI Creative Brief Template in 2026: Turn Competitor Evidence Into Testable Ads
A complete 2026 guide to the AI creative brief template — the nine fill-in fields that feed a model evidence instead of vibes, why the hook pattern is the highest-leverage input, how to gather example ads responsibly, the do-not-say list that keeps output honest, a prompt structure that uses the brief, how to rank output into a test backlog, a fully filled worked example, the limits of AI and public data, and where AdMapix fits.