Ad Creative Intelligence Workflow for Mobile UA Teams in 2026: Find, Analyze, Brief & Build
A complete 2026 ad creative intelligence workflow for mobile UA teams — the four-stage loop to find winning competitor creatives, analyze why they work, brief production from them, and build a sustainable competitive-intelligence system, with the data inputs, a fixed taxonomy, tiered competitor monitoring, an observation-to-hypothesis method, a structured brief format, a weekly operating cadence, team-size tool choices, and the learning log that makes each cycle compound.
Ad Creative Intelligence Workflow for Mobile UA Teams in 2026: Find, Analyze, Brief & Build
By the AdMapix Research Team — Updated June 21, 2026
If your mobile UA team is still doing "creative research" by dropping random competitor ads into Slack whenever someone has time, you already know the feeling: lots of activity, very little repeatable impact. An ad creative intelligence workflow fixes that by turning four scattered jobs — finding winning creatives, analyzing why they work, briefing production from them, and building a competitive-intelligence system — into one repeatable weekly loop that links observation to decision. This guide is for UA managers, performance marketers, and growth teams who need a practical, sustainable workflow they can run every week, not a one-off audit, not a dashboard graveyard, and not a process that depends on one person's memory. It's the canonical workflow that covers the whole loop end to end; for the two specialized pieces, see our playable ad analysis method for reverse-engineering interactive creatives and our mobile game ad formats guide for the format-by-platform map.
We've helped mobile UA teams build creative-intelligence processes across casual, midcore, and hybrid titles, and the difference between teams that compound learnings and teams that spin in place is never the quality of the ads they find — it's whether they have a system that connects what they observe to what they ship. A team with a fixed taxonomy, a tiered monitoring cadence, and a learning log out-iterates a team with sharper analysts and no system, every cycle. This guide is that system, organized around the four stages every creative-intelligence workflow has to cover.

TL;DR — The Ad Creative Intelligence Workflow in One Screen
- The workflow is a four-stage loop: find winning creatives, analyze why they work, brief production from them, and build a system that makes the loop repeatable. Ad hoc research breaks because it skips the system stage.
- Standardize inputs, not just outputs. A fixed taxonomy applied at capture time (hook type, message angle, format behavior) is what makes signals comparable over time — without it, you have noise.
- Tier your competitors. Tier 1 (3-5 direct rivals) weekly, Tier 2 (adjacent) bi-weekly, Tier 3 (market watchlist) monthly, with explicit escalation triggers. Tiering prevents both wasted time and blind spots.
- Every observation becomes a testable hypothesis, never an "interesting trend." Observation → interpretation → transfer rule → test hypothesis is the chain that turns a competitor signal into a brief.
- Briefs need four linked blocks: strategic context, intelligence-derived hypothesis, execution guardrails, and a measurement plan. A brief that says "5 fresh TikTok concepts" isn't a brief.
- Run a fixed weekly cadence: Monday capture, Tuesday prioritize, Wed-Thu brief, Friday learn. Build for cadence, not heroics — the process must survive launches, holidays, and turnover.
- Close the loop with a learning log that maps every test outcome back to its source hypothesis. The log is the compounding asset; without it, the team relives the same mistakes.
Why Ad Hoc Creative Research Fails
Ad hoc creative research fails for a simple reason: it doesn't create a system that links observations to decisions. When research is ad hoc, four things reliably break, and understanding them is what motivates every part of the workflow that follows.
- Coverage is inconsistent. You track whichever competitors are top-of-mind, not the ones that matter by genre, geography, and growth stage. You miss new entrants and sudden spend shifts because nobody's responsible for systematic coverage.
- Signals aren't comparable over time. If one week you log ad formats and the next week you log themes, you can't identify trends. Without consistent fields and cadence, there's no baseline to measure change against — every week starts from scratch.
- Insights never reach production briefs. Teams collect "inspiration" but creative strategists receive vague requests like "make it more TikTok-native." No hook taxonomy, no isolated test variable, no platform-specific direction — so the inspiration evaporates between research and production.
- Learning loops break after launch. Even when a creative idea ships, performance isn't mapped back to the original competitive hypothesis. So the team can't answer the question that matters: did this concept win because of the hook, the format, the mechanic, or the audience fit? Without that answer, the next test is another guess.
The cost is real and compounding: slower iteration cycles, repeated creative mistakes, and budget spent testing low-probability ideas. A workflow fixes this by making creative intelligence operational — a routine that runs every week — rather than optional — something that happens when someone has spare time, which is never. The rest of this guide builds that operational system, stage by stage.

The Design Principles Behind the Workflow
Before defining tasks, tools, and templates, align the team on five principles — because a workflow built on the wrong assumptions fails no matter how good the tools are. These principles are what keep the system sustainable.
- Standardize inputs, not just outputs. Most teams standardize reports but not collection. If collection fields are inconsistent, reports are noise. Define exactly what gets logged for every observed ad, and enforce it at capture time.
- Separate monitoring from analysis. Monitoring is routine capture — what changed this week. Analysis is interpretation — why it matters and what to test. If one meeting tries to do both from scratch, neither gets done deeply. Split them.
- Tie every insight to an actionable hypothesis. No "interesting trend" survives unless it becomes a falsifiable bet: if we test X in Y context, we expect Z outcome because… An insight that can't be phrased that way isn't ready for production.
- Build for cadence, not heroics. The process must work during launches, holidays, and team turnover. If it requires one brilliant analyst doing six-hour deep dives every Friday, it will collapse the first week that analyst is on vacation. Design for the team you have on a normal week.
- Design for decision rights. Who chooses what gets tested — the UA lead, the creative strategist, or the growth manager? Define this explicitly. Intelligence without ownership turns into documentation theater: lots of logged observations, no decisions made.
These five principles are the foundation; the four-stage loop below is what you build on them.

Stage 1: Find — Discovering Winning Competitor Creatives
The first stage of the workflow is finding the creatives worth studying, and the discipline here is systematic coverage, not random discovery — you want to reliably surface the creatives that matter, not just the ones someone happened to scroll past. Finding winning creatives well means defining what data you capture and which competitors you watch.
Creative intelligence isn't just "what ads competitors run." You need a small but complete dataset across creative, market, and performance context, captured consistently for every observed ad.
| Input category | What to collect | Why it matters |
|---|---|---|
| Creative asset metadata | Platform, format (video/image/playable), aspect ratio, duration, CTA style | Controls where an idea can transfer and how production effort changes |
| Message & hook taxonomy | First-3-second hook type, emotional angle, value prop, visual motif | Identifies repeatable message patterns, not isolated examples |
| Gameplay/feature framing | Core mechanic shown, progression, social proof, reward loop | Connects the ad concept to product truth (or exposes a mismatch) |
| Creative freshness & history | First seen, last seen, active run length, recurrence | Longevity is a directional performance proxy |
| Competitive pressure signals | Creative volume trend, new format adoption, geo expansion | Indicates where spend is likely intensifying |
| Market context | Store rank shifts, estimated downloads/revenue trend by geo | Distinguishes creative change from demand/seasonality shifts |
| Your own test outcomes | CTR, IPM/CVR proxy, CPI/CAC, retention quality by concept cluster | Closes the learning loop; prevents copying low-quality winners |
The non-negotiable in the find stage is a fixed taxonomy applied at capture time. If everyone labels hooks differently ("shock," "pattern break," "surprise reveal" for the same thing), you can't compare anything. Keep the taxonomy lean — hook type (fail, challenge, comparison, reward tease, social proof), message angle (progression speed, strategic mastery, relaxation, status), format behavior (UGC-style, gameplay overlay, static-to-video hybrid) — with 8-12 options per field maximum. The taxonomy is what turns a folder of saved ads into a queryable dataset, and applying it at capture (not "later," which means never) is what makes the find stage produce comparable signals instead of a screenshot pile.
A creative-intelligence platform like AdMapix is useful in the find stage because it combines creative discovery with creative history and market signals (store ranks, download/revenue estimates) in one place. The value isn't "more data" — it's reducing the context-switching that otherwise stops weekly analysis from happening at all.

Organizing Competitive Monitoring by Tiers
Not all competitors deserve equal attention every week, so tiering your competitor set is what keeps the find stage sustainable while preserving strategic coverage. Tiering prevents the two opposite failures: spreading attention so thin that you miss critical rivals, and chasing so many competitors that the weekly workload collapses.
The recommended tier structure:
- Tier 1 (3-5 apps): direct genre and business-model overlap in your same core geos. These are your direct UA rivals, reviewed in full every week.
- Tier 2 (5-10 apps): adjacent mechanics or audience overlap. Reviewed at the pattern level every two weeks.
- Tier 3 (ongoing scan): emerging titles, regional challengers, breakout newcomers. A lightweight monthly scan plus alerts.
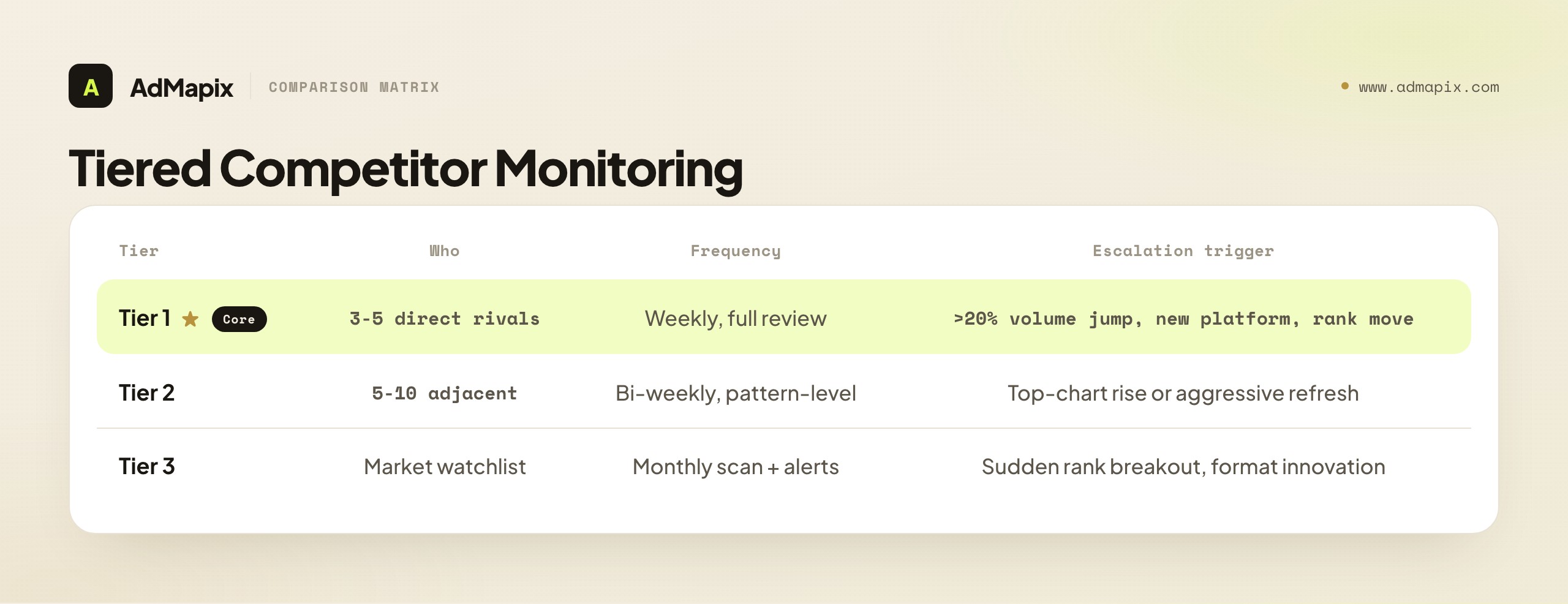
| Tier | Who belongs | Monitoring frequency | Depth of review | Escalation trigger |
|---|---|---|---|---|
| Tier 1 | Direct UA rivals | Weekly | Full review: new creatives, format mix, message shifts, run-length | >20% creative volume jump, new platform push, major rank move |
| Tier 2 | Adjacent competitors | Bi-weekly | Pattern-level: formats, hooks, themes | Consistent top-chart rise or aggressive creative refresh |
| Tier 3 | Market watchlist | Monthly scan + alerts | Lightweight: new entrants, standout concepts | Sudden rank breakout, unusual format innovation |
For Tier 1, "weekly monitoring" should mean a fixed checklist run every Monday, not an open-ended browse: new creatives in the last seven days by platform; format-mix changes (video/image/playable share); new hook or message patterns introduced; creatives with unusual run-length persistence; geo or platform expansion clues; and correlated market movement (rank/download direction). If an item isn't on that checklist, it belongs in ad hoc exploration, not in weekly ops — keeping the routine checklist tight is what makes it survivable every week. The escalation triggers are what pull a Tier 2 or Tier 3 competitor into closer attention when they make a move worth a full review, so coverage stays both efficient and responsive.
Stage 2: Analyze — Turning Observations Into Testable Insights
The second stage is analysis, and this is where most workflows quietly fail — they stop at "Competitor X uses lots of fake-fail hooks," which is an observation, not an insight. An observation becomes useful only when it's translated into a hypothesis with scope: what to test, in what context, expecting what outcome, and why. Analysis is the bridge between finding a creative and briefing a test.
The chain that turns an observation into a testable insight:
- Observation: what changed externally? (Stated factually, from your captured data.)
- Interpretation: why might it be working in that context? (Your read of the mechanism.)
- Transfer rule: what conditions must be true for you to adapt it? (The crucial step most teams skip.)
- Test hypothesis: what exactly will you ship and measure? (A falsifiable, scoped prediction.)
A worked example of the chain:
- Observation: a rival increased short portrait videos with early "near-loss" gameplay hooks.
- Interpretation: near-loss creates tension quickly and communicates skill fantasy in the first seconds.
- Transfer rule: this works only if our early gameplay is readable without heavy UI clutter — if our HUD is busy, the near-loss moment won't land.
- Hypothesis: two 15-second concepts using a "near-loss rescue" in the first two seconds should improve thumb-stop rate versus our current baseline concept family.
That level of specificity is what a creative team can actually brief and produce against. The transfer rule is the analytical step that separates rigorous workflows from copy-cat ones: it forces you to ask whether the competitor's winning idea even can work in your product context before you spend producing it. A near-loss hook that works for a rival with clean, readable gameplay may be impossible for a game with a cluttered early experience — and the transfer rule catches that before the test budget is spent, not after. Analysis without the transfer rule produces a backlog of competitor ideas that fail in your context for reasons you could have predicted.

Stage 3: Brief — Connecting Insights to Real Creative Briefs
The third stage is briefing, and it's the point where many intelligence workflows fail even after good find and analyze work: the team gathers data, runs the analysis, and then the brief still says "need 5 fresh concepts for TikTok." A usable brief connects the intelligence to production with four linked blocks, so the producer knows not just what to make but why, with what constraints, and how success will be judged.
The four blocks every creative brief needs:
- Strategic context. The target audience slice, the platform, the campaign objective, and the spend intent. This anchors the concept to a real campaign, not a generic "more creative" request.
- Intelligence-derived hypothesis. What market signal inspired this concept and why now — the output of the analyze stage, carried directly into the brief so the rationale travels with the request.
- Execution guardrails. The must-show gameplay moment, the hook timing, the visual-style constraints, and the claim boundaries. Guardrails are what keep the producer's interpretation aligned with the hypothesis — without them, a "near-loss hook" brief comes back as something unrecognizable.
- Measurement plan. The primary decision metric, the secondary quality metric, the kill/scale threshold, and the readout date. Defined before production, so the test is judged against a pre-committed standard, not a post-hoc rationalization.
Before any brief goes to production, run a quality check: Is the hook variable isolated enough to learn from? Does the concept reflect platform behavior, not just a resized asset? Are the success and failure criteria defined before launch? Can the outcome be mapped back to the source insight in one sentence? If any answer is no, rewrite the brief. The discipline of the brief stage is what ensures the intelligence work actually changes what gets produced — a workflow that finds and analyzes brilliantly but briefs vaguely produces the same generic creative as a team that does no research at all. The brief is where intelligence becomes production direction, and the four blocks are what make that translation reliable. For the hook variations that populate these briefs, see our ad hook examples guide.

Stage 4: Build — The Weekly Operating Cadence and System
The fourth stage is building the system that makes the first three repeatable — a fixed weekly cadence, clear ownership, and a learning log — because find, analyze, and brief only compound when they run as a sustained operating rhythm rather than occasional bursts. The build stage is what separates a workflow that lasts from one that fizzles after two enthusiastic weeks.
A practical week-to-week rhythm for a mid-size UA and creative team:
- Monday — capture and triage (60-90 min). Update Tier 1 competitor logs, tag new creatives with the taxonomy, flag anomalies (volume spikes, new formats, message pivots), and select 3-5 candidate insights for discussion. This is monitoring, kept routine and checklist-driven.
- Tuesday — insight-to-brief workshop (45-60 min). Review the candidates, approve 1-3 hypotheses for production testing, assign a concept owner and due dates, and archive rejected insights with a reason (which improves the filter over time). This is where decision rights are exercised.
- Wednesday-Thursday — briefing and production handoff. Build the four-block briefs from approved hypotheses, confirm platform-specific variants (Meta vs. TikTok vs. YouTube), and lock the measurement plan with the UA lead before assets are finalized.
- Friday — performance readout and learning log (45 min). Review active test performance by concept cluster, label outcomes (scale, iterate, kill, or reframe), record what was learned about hook/message/format interaction, and feed validated patterns back into next week's monitoring priorities.
This cycle is short enough to sustain but rigorous enough to produce cumulative learning. The single most important component — and the one teams skip under sprint pressure — is the Friday learning log. It's what closes the loop: every test outcome maps back to its source hypothesis, so the team can answer why a concept won or lost and feed that answer into next week's find and analyze stages. Without the learning log, the workflow generates activity but no compounding knowledge; with it, each cycle makes the next one sharper. The build stage's whole purpose is to make the loop turn reliably and accumulate learnings, week after week.
One operational detail makes or breaks the build stage: the cadence has to be protected like any other recurring commitment, not treated as the thing that slides when the team is busy. The weeks the team is busiest — a launch, a crunch, a fire — are exactly the weeks creative intelligence is most valuable and most likely to be skipped, and a skipped week breaks the comparability the whole system depends on. So the build stage's discipline isn't just defining the cadence; it's defending it, treating the Monday capture and Friday learning log as non-negotiable standing commitments rather than nice-to-haves that yield to whatever's urgent. A team that protects the cadence through its busy weeks builds an unbroken time series and a compounding learning log; a team that skips the loop whenever things get hectic ends up with a gappy dataset and a workflow that exists on paper but not in practice. The cadence is only as valuable as it is consistent — which is why the build stage is about the habit as much as the steps.

Choosing Tools by Team Size and Maturity
There's no universal best stack for a creative-intelligence workflow — the right setup depends on headcount, campaign complexity, and reporting demands — so matching the tooling to your team's stage prevents both over-buying and under-building. The four-stage loop is constant; how you tool it scales.
| Team stage | Tooling approach | Primary risk |
|---|---|---|
| Lean (1-3 people) | Shared spreadsheet/lightweight DB, fixed taxonomy drop-downs, weekly meeting + one-page decision log, optional intelligence platform for faster discovery | Overcomplicating — keep fields minimal and cadence strict |
| Growing (4-10 people) | Dedicated intelligence owner (part- or full-time), structured repository (Notion/Airtable/BI), platform-level tracking views, brief templates integrated with creative ops | Fragmented ownership between UA and creative — define decision rights |
| Larger org / agency (10+ or multi-client) | Automated competitor-pull pipelines, taxonomy governance, role-specific dashboards, quarterly framework refresh | Reporting bloat — protect a small set of decision-critical metrics |
The reads that matter: a lean team should resist overcomplicating — minimal fields, strict cadence, and a single intelligence platform to speed discovery beat an elaborate stack nobody maintains. A growing team earns a dedicated intelligence owner and a structured repository, but its real risk is fragmented ownership between UA and creative, which the design principle of explicit decision rights solves. A larger org or agency needs automation and governance but must guard against reporting bloat — protecting a small set of decision-critical metrics rather than building dashboards nobody acts on. The trap at every stage is tool-first implementation: a platform demo looks like an instant process fix, but the tool doesn't define your cadence, taxonomy, or decision rights — those come first, and the tool accelerates them. AdMapix fits especially well for growing teams that need to monitor many competitors and geos without manual tab-switching, and for agencies needing fast comparative scans across apps and markets — but it accelerates a defined workflow, it doesn't replace defining one.
There's a sequencing lesson buried in the tool-first trap worth stating plainly: the value a tool adds is proportional to how well-defined your workflow already is. A team with a fixed taxonomy, clear tiers, a weekly cadence, and explicit decision rights gets enormous leverage from a discovery-and-history platform, because the platform feeds a machine that's ready to use the data. A team without those foundations gets a faster firehose of creatives it still doesn't know how to turn into decisions — the tool amplifies the disorganization rather than fixing it. So the right order is always foundations first, tool second: define the cadence, taxonomy, and decision rights on a spreadsheet, prove the loop produces shipped tests for a few weeks, and only then add the platform to remove the manual-collection bottleneck. Buying the tool first, hoping it will impose a process, reliably produces an expensive subscription and the same ad hoc behavior — the most common and most expensive mistake in standing up creative intelligence. The tool is a multiplier on a defined workflow, and a multiplier on zero is still zero.

A Worked Scenario: From Monitoring to a Winning Test Plan
Principles stick when applied, so here's the full four-stage loop running on a real situation. You run UA for a midcore strategy game in the US, UK, and DE. CPI has risen for six weeks, and your top three concept families are saturating.
Stage 1 — Monday monitoring (find). Your team logs these Tier 1 changes from the fixed checklist: Competitor A launched 14 new TikTok videos in seven days, mostly 12-18s; Competitor B increased playable share on Meta in the US; Competitor C kept only four creatives active, but each has a long run-length and a repeated hook structure. Rank movement: Competitor A rising in the UK, B stabilizing in the US, C flat. Every observation is captured with the taxonomy, so it's comparable to prior weeks.
Stage 2 — Tuesday analysis (analyze). You run each observation through the observation-to-hypothesis chain and select three, each with a transfer rule checked against your product: (1) a hook-timing hypothesis — earlier conflict reveal (0-2s) will improve first-quartile view retention on TikTok; (2) an interactive-intent hypothesis — "choice moment" creatives can pre-qualify users better than passive gameplay reels on Meta; (3) a message-clarity hypothesis — repeating one strategic payoff line across variants may beat multi-message scripts.
Stage 3 — brief conversion. Each hypothesis becomes a separate four-block brief: a fixed audience and platform, one primary variable, a pre-defined success metric, and a decision threshold after a minimum spend window. The briefs isolate the variable so the result is attributable (the discipline from our creative testing framework).
Stage 4 — Friday readout (build/learn). After the initial spend window: Hypothesis 1 shows better early retention but neutral install efficiency → iterate; Hypothesis 2 shows lower CTR but better downstream quality → continue with audience refinement; Hypothesis 3 shows no lift → kill and archive. Most important, the learning log records why each result happened relative to the original assumption, so next week's monitoring focuses on hook execution and qualification signals — not random new ideas. The loop has turned: monitoring fed analysis, analysis fed briefs, briefs fed tests, and test outcomes fed next week's monitoring. That's the workflow compounding.

Creative-Product Fit: Why the Transfer Rule Is the Hardest Step
The transfer rule deserves a deeper treatment because it's the step that most determines whether a competitor-inspired test succeeds or fails — and it's the one teams find hardest, because it requires honesty about your own product, not just observation of a competitor's. Creative-product fit is the question of whether a competitor's winning creative angle can even work given your game's reality, and getting it wrong is how teams burn budget on concepts that were never going to transfer.
The dimensions of creative-product fit to check before adapting any competitor concept:
- Gameplay readability. A near-loss hook, a satisfying-merge hook, or a fast-progression hook all depend on the gameplay being legible in the first seconds. If your early-game experience is cluttered, slow, or tutorial-heavy, a hook that depends on instant gameplay clarity won't land — the competitor's clean game made the hook work, and your game can't replicate the precondition.
- Mechanic honesty. If a competitor's creative shows a mechanic, can your game deliver it? A fake-mechanic creative (showing a mechanic your game doesn't really have) might win installs but cause day-1 churn when the install experience disappoints — a mismatch the transfer rule should catch. (Our playable analysis method covers this honesty check in depth for interactive creatives.)
- Audience and positioning fit. A competitor targeting a different audience slice (more casual, more hardcore, a different geo) may have a winning creative that's tuned to their audience, not yours. The angle that converts their audience may repel yours.
- Production feasibility. Some competitor creatives depend on production resources (high-end CGI, a roster of creators, a complex playable build) you may not have. The transfer rule should include "can we actually produce this at a quality that makes the angle work?"
The discipline the transfer rule enforces is product honesty: it forces the team to look at its own game clearly and ask whether the competitor's winning idea has the preconditions it needs to work here. This is uncomfortable because it sometimes means passing on a concept that's clearly working for a competitor — but adapting a concept whose preconditions you don't share is how teams produce expensive creatives that fail for predictable reasons. The teams that adapt competitor creatives successfully aren't the ones that copy the most; they're the ones whose transfer rules are honest enough to filter out the concepts that can't work in their product context, so the tests they do run have a real chance. Creative-product fit is where competitor intelligence meets product reality, and the transfer rule is the gate.
Reading Run-Length and Market Signals Together
Two of the most useful signals in the find stage — creative run-length and market movement — are most powerful when read together, because each alone is ambiguous and the combination disambiguates them. Learning to read them as a pair is what turns raw monitoring data into a confident read on what a competitor is doing.
How the signals combine:
- Run-length alone is a directional performance proxy. A creative a competitor has kept live and scaled for weeks is more likely to be working than a one-off, because advertisers rarely keep funding losers. But run-length alone can't tell you whether the creative is driving growth or just maintaining a position — for that, you need the market signal.
- Market movement alone is ambiguous. A competitor rising in the rankings could be driven by a creative win, a seasonal demand spike, a price change, a featuring, or a PR moment. The rank movement alone doesn't tell you the cause.
- Together, they disambiguate. A competitor whose ranking is rising while a specific creative or format is gaining run-length and volume is a strong signal that the creative is driving the growth — the two signals corroborate each other. Conversely, a rank rise with no creative change suggests a non-creative cause (seasonality, featuring), and a creative scaling with flat rank suggests the creative is maintaining, not growing.
- The annotation discipline. This is why the monitoring checklist includes annotating market movement beside creative changes — so that when you read the week's data, you can see which creative changes correlate with which market movements, and read the pair rather than either alone.
The strategic payoff: reading run-length and market signals together lets you distinguish a competitor's creative-driven growth (worth studying and adapting) from their demand-driven growth (not a creative lesson) and their maintenance creative (working but not a growth driver). This distinction matters enormously for prioritization — you want to study and adapt the creatives that are demonstrably driving growth, not the ones that happen to be running during a seasonal spike. The find stage produces both signals; reading them as a pair in the analyze stage is what extracts the real intelligence. A creative-intelligence platform that combines creative history with market signals (ranks, download/revenue estimates) in one view is valuable precisely because it makes reading the pair possible without manually stitching two data sources together.
Cross-Platform Creative Adaptation
A competitor's creative that wins on one platform isn't automatically a winner on another, so the workflow has to handle cross-platform adaptation explicitly — because the same concept needs genuinely different execution on TikTok, Meta, and YouTube, and treating a resized asset as a "platform variant" is a common, costly shortcut. Cross-platform adaptation is part of both the analyze stage (does this concept transfer across platforms?) and the brief stage (specify the platform-native execution).
The platform-adaptation realities the workflow must account for:
- TikTok rewards native, fast, sound-on creative. A concept that works on TikTok usually leads with a fast hook, feels creator-made, and is designed for sound. A polished, logo-forward version of the same concept underperforms here. TikTok's own guidance emphasizes TikTok-first, vertical, sound-on creative — a concept ported from another platform without this native treatment is a different (worse) creative.
- Meta spans a broader audience with mixed sound. The same concept on Meta needs to work with sound off as often as on, so the visual interrupt and on-screen text carry more weight. A TikTok creative's audio-dependent hook may need a visual-first re-execution for Meta.
- YouTube has the skip dynamic. On skippable YouTube placements, the concept needs to promise value before the skip button, which is a different opening than a TikTok scroll-stop. The same concept needs a different first few seconds for each.
- Playable and rewarded placements need interactive execution. A video concept doesn't automatically become a playable; adapting a winning video angle into a playable is a real production task, not a format toggle. (See the ad formats guide for the format-by-platform map.)
The discipline for the workflow: when a concept is approved for testing across platforms, the brief must specify the platform-native execution for each, not just "resize for TikTok." A concept is a strategic bet (the angle, the hook type, the mechanic shown); the execution is platform-specific. Treating a resized asset as a platform variant is the brief-stage version of skipping the transfer rule — it produces a creative that doesn't fit the platform's behavior and underperforms for predictable reasons. The strongest workflows brief each platform's execution deliberately, so a winning concept gets a real chance on each channel rather than one good native execution and several resized afterthoughts.
Scaling the Workflow as the Team Grows
The four-stage workflow is the same at every team size, but how you run it has to evolve as the team grows, so anticipating the scaling transitions keeps the workflow from breaking at the moments it's most stressed. A process that works for a three-person team will fragment at fifteen people without deliberate evolution, and the failure modes are predictable.
The scaling transitions and how to handle them:
- From solo to a small team: formalize the taxonomy. When one person did all the research, the taxonomy could live in their head. As soon as two people log creatives, the taxonomy has to be written, fixed, and enforced — otherwise the two people label things differently and the comparability that makes the workflow valuable evaporates. Formalizing the taxonomy is the first scaling task.
- From a small team to a growing one: assign an intelligence owner. As the competitor set and the channel mix grow, the research stops fitting into everyone's spare time, and it needs a named owner (part- or full-time) responsible for the find and analyze stages. Without an owner, the research becomes everyone's job and therefore no one's, and the weekly cadence slips.
- From a growing team to a larger org: govern the standards. At scale, multiple people contribute to the research, so the taxonomy, naming, and brief standards need governance — a defined owner of the standards who keeps them consistent as the team grows. Without governance, each contributor drifts toward their own conventions and the dataset fragments.
- For agencies: standardize across clients. An agency runs the workflow per client, so the challenge is a standardized process that applies across accounts with client-specific competitor sets. The standardization is what lets analysts move between clients without relearning the system, and what makes the agency's creative intelligence a repeatable, billable capability rather than a per-client improvisation.
The strategic point: the workflow's method is constant, but its operating model — who owns it, how the standards are governed, how the work is divided — has to evolve at each scaling transition, and the transitions are predictable enough to plan for. Teams that anticipate them (formalizing the taxonomy before the second researcher joins, assigning an owner before the cadence slips, governing standards before the dataset fragments) keep the workflow running smoothly through growth. Teams that don't find the workflow breaking exactly when the team is busiest and the stakes are highest — which is the worst time to rebuild it. Plan the scaling transitions, and the workflow scales with the team instead of breaking under it.
Standing Up the Workflow: The First 90 Days
Building this workflow from scratch is itself a project, so a phased first-90-days plan prevents the common failure of trying to launch the full system at once and abandoning it when it's overwhelming. The workflow compounds over time, which means starting small and adding rigor as the habit forms beats a big-bang launch that collapses under its own ambition.
A realistic phasing for standing up the workflow:
- Weeks 1-2: Define the foundations. Write the fixed taxonomy (hook types, message angles, format behaviors — 8-12 options each), pick the initial Tier 1 competitor set (just 3-5, resist more), and decide the decision rights (who approves what gets tested). Don't tool-shop yet — a spreadsheet is fine. The foundations are taxonomy, tiers, and ownership; everything else builds on them.
- Weeks 3-6: Run the monitoring loop only. Start with just the Monday capture and the find stage — log Tier 1 creatives with the taxonomy every week. Don't try to run the full Monday-to-Friday cadence yet; just build the habit of consistent, taxonomied capture. This is the foundation the rest depends on, and it has to become routine before you add analysis on top.
- Weeks 7-10: Add the analyze and brief stages. Once monitoring is a reliable habit, add the Tuesday analysis (observation-to-hypothesis with transfer rules) and the Wednesday-Thursday briefing. Now the loop produces tests, not just logs. Expect the first few hypotheses to be rough; the transfer-rule discipline takes practice.
- Weeks 11-13: Close the loop with the learning log. Add the Friday readout and learning log, mapping the first tests' outcomes back to their hypotheses. This is when the workflow starts compounding — the first learnings feed the next week's monitoring. Only now is the full four-stage loop running.
The phasing principle is to build the habit before adding the rigor: a team that nails consistent taxonomied capture in weeks 3-6 has a foundation to build analysis and briefing on, while a team that tries to run the full cadence in week one usually produces a chaotic first month and quits. Each phase adds one layer to a foundation that's already solid. By day 90, the full loop is running and starting to compound — and the team has built the habit gradually enough that it sticks. The most common mistake in standing up the workflow is impatience: trying to have the complete, polished system in week two, being overwhelmed, and reverting to ad hoc research. Phase it, build the habit first, and the workflow takes root instead of collapsing.
What Competitor Creative Data Can and Cannot Prove
The whole workflow runs on competitor creative observation, so it has to be honest about what that data proves: it's excellent for generating hypotheses and terrible for proving they work. You can see which creatives a competitor runs, in which formats and markets, and how long they keep running — which is a directional signal that a creative earns its spend (advertisers rarely keep funding losers). You cannot see their IPM, CPI, retention, spend, or whether a creative is genuinely winning or just stuck in an unoptimized campaign.
That boundary is why the workflow's analyze stage uses competitor data as input to a hypothesis, never as the result. Run-length is the most useful public signal — a creative a competitor has kept live for weeks, or relaunched across formats, is a stronger hypothesis than a one-off — but it's still a hypothesis your own test confirms. The learning loop closes only with your own test outcomes, because the performance that defines a winning creative for your audience is private to your account. Treat every competitor signal, however strong, as a reason to test rather than proof to copy: the competitor data tells you where to point your tests, and your own results tell you what actually works. This honest division — competitor observation generates the backlog, your tests validate it — is what keeps the workflow from degrading into copying competitors' expensive mistakes.
Common Mistakes (and Why They Keep Happening)
- Tracking too many competitors equally. It happens out of fear of missing out, and it hurts by producing shallow coverage of the rivals that actually matter. Fix: enforce tiered monitoring with explicit escalation rules.
- Logging assets without a taxonomy. It happens because "we'll label later" feels efficient, and it hurts because there's no trend analysis or clustering without consistent tags. Fix: mandatory tags at capture time; reject incomplete entries.
- Confusing novelty with transferable value. It happens because flashy ads look compelling, and it hurts because copied concepts fail in different product contexts. Fix: always write the transfer rule before approving a test.
- Briefs that bundle too many variables. It happens under pressure to "make each test count," and it hurts by producing inconclusive outcomes with no reusable learning. Fix: one dominant variable per test concept family.
- No post-test learning archive. It happens because sprint pressure shifts attention forward, and it hurts through repeated failed experiments and institutional amnesia. Fix: the Friday learning log is mandatory, no exceptions.
- Tool-first implementation. It happens because platform demos look like instant process fixes, and it hurts by producing an expensive stack with the same broken behavior. Fix: define cadence, taxonomy, and ownership first, then choose tools.
- Skipping the transfer rule. It happens because copying a competitor's winner feels safe, and it hurts because the winner often depends on a product context you don't share. Fix: every adapted concept states the conditions under which it can work for you.
When to Use AdMapix
AdMapix fits the find and analyze stages of this workflow — the cross-network creative discovery and the market context that feed the loop. Use Search AdMapix to discover competitor creatives across networks by genre, geo, format, and time range; Media to save the examples your taxonomy tags; Video Analysis to break down hooks, pacing, and mechanics in winning videos; and Reports to turn the weekly monitoring into a shareable record. The platform's combination of creative history and market signals (store ranks, download/revenue estimates) is what reduces the context-switching that otherwise stops the weekly loop from happening.
It's a good fit for growing UA teams monitoring many competitors and geos, and for agencies needing fast comparative scans across apps and markets. It's not a campaign manager, an analytics platform, or a substitute for your own test results — it won't tell you a competitor's CPI or predict your own performance, and it doesn't run the test for you. AdMapix accelerates the find and analyze stages so your team's time goes to the brief and the test; the cadence, taxonomy, decision rights, and learning log — the actual workflow — stay yours to define and run.
FAQ
What is an ad creative intelligence workflow?
It's a repeatable weekly system that connects four stages — finding winning competitor creatives, analyzing why they work, briefing production from them, and building the operating system that makes the loop sustainable. The goal is to turn creative research from ad hoc activity into an operational routine that links every observation to a decision and every test outcome back to its source hypothesis.
Why does ad hoc creative research fail for UA teams?
Because it doesn't create a system linking observation to decision. Coverage becomes inconsistent (you track top-of-mind competitors, not the strategic ones), signals aren't comparable over time (inconsistent fields mean no baseline), insights never reach production briefs (inspiration evaporates into vague requests), and learning loops break after launch (outcomes aren't mapped back to hypotheses). The result is slower iteration and budget spent on low-probability ideas.
How do I find which competitor creatives to study?
Define a fixed taxonomy and tier your competitors. Capture every observed ad with consistent fields (format, hook type, message angle, run-length, market context), and review Tier 1 direct rivals weekly, Tier 2 adjacent competitors bi-weekly, and a Tier 3 market watchlist monthly, with escalation triggers when a lower tier makes a significant move. Run-length and creative-volume trends are your strongest directional signals for which creatives are worth analyzing.
How do I analyze a competitor creative properly?
Run it through the observation-to-hypothesis chain: state what changed (observation), why it might work (interpretation), what conditions must be true for you to adapt it (transfer rule), and what exactly you'll test and measure (hypothesis). The transfer rule is the critical step — it forces you to check whether the competitor's winning idea can even work in your product context before you spend producing it, which is what separates rigorous analysis from copying.
What makes a good creative brief from competitive intelligence?
Four linked blocks: strategic context (audience, platform, objective, spend intent), the intelligence-derived hypothesis (what signal inspired it and why now), execution guardrails (must-show moment, hook timing, style and claim constraints), and a measurement plan (primary metric, quality metric, kill/scale threshold, readout date) defined before production. A brief that says "5 fresh TikTok concepts" isn't a brief — it's a request that loses all the intelligence work behind it.
What weekly cadence should a UA team run?
Monday: capture and triage Tier 1 competitor changes with the taxonomy and select candidate insights. Tuesday: prioritize 1-3 hypotheses for testing and assign owners. Wednesday-Thursday: build the four-block briefs and lock the measurement plan. Friday: read out performance by concept cluster and update the learning log. The cadence is short enough to sustain through launches and turnover but rigorous enough to compound learnings.
How do I tier competitors for monitoring?
Tier 1 is 3-5 direct rivals with genre, business-model, and geo overlap — reviewed in full weekly. Tier 2 is 5-10 adjacent competitors with mechanic or audience overlap — reviewed at the pattern level bi-weekly. Tier 3 is an ongoing market watchlist of emerging titles and regional challengers — a lightweight monthly scan plus alerts. Escalation triggers (a volume jump, a rank breakout, a new format push) pull a lower-tier competitor into closer review when they make a move worth it.
Can competitor creative data tell me what's actually winning?
No. Public creative data shows what competitors run, in what formats and markets, and how long — which is a directional signal (run-length suggests a creative earns its spend) but never proof. You can't see their IPM, CPI, retention, or spend. Use competitor data to generate hypotheses and point your tests; confirm what actually works only in your own account, because the performance that defines a winning creative for your audience is private to you.
What tools do I need for a creative intelligence workflow?
Match the tooling to your team size. A lean team (1-3) needs a shared spreadsheet with a fixed taxonomy and a strict weekly cadence, optionally a creative-intelligence platform for faster discovery. A growing team (4-10) earns a dedicated intelligence owner and a structured repository. A larger org or agency needs automated competitor pulls and taxonomy governance. The trap at every stage is buying tools before defining the cadence, taxonomy, and decision rights — the tool accelerates a workflow, it doesn't create one.
How does this workflow connect to playable analysis and ad formats?
This is the canonical workflow that covers the whole loop; two specialized pieces plug into it. The playable ad analysis method is the deep-dive technique for the analyze stage when the creative is an interactive playable, and the mobile game ad formats guide is the format-by-platform map that informs both the find stage (what to look for) and the brief stage (what format to specify). The workflow is the operating system; those two are specialized tools that run inside it.
Related Reading
- Playable Ad Analysis for Mobile Games: A Practical Method — the deep-dive technique for analyzing interactive playables inside this workflow.
- Top-Performing Mobile Game Ad Formats by Platform, Genre & Funnel Stage — the format map that informs the find and brief stages.
- Creative Testing Framework: Isolate, Prioritize & Scale Winners — the testing discipline the brief stage feeds into.
- Ad Creative Fatigue Analysis: Signals, Thresholds & Refresh Decisions — diagnosing when your own creatives need the refresh this workflow produces.
- Ad Hook Examples: 7 First-3-Second Patterns — the hook taxonomy that populates briefs.
- Playable Ads: Teardowns of Hooks, Mechanics & End Cards — example library for the interactive creatives you'll analyze.
- Paid User Acquisition: A 2026 Playbook — the UA strategy this creative-intelligence loop serves.
Sources
- Google Ads ad variations — explains testing and iterating creative messages, including headline and CTA changes, across campaigns.
- TikTok creative best practices — recommends TikTok-first, vertical 9:16, designed-for-sound creative featuring real creators.
- Google Developers: rewarded ads — describes rewarded ads as letting users earn in-app items by interacting with video and playable ads.
- Meta Ads Library — the public archive for observing how competitors run and rotate their creatives over time.
Sources checked as of June 21, 2026. Platform features and recommendations change, so verify each URL before relying on specifics in an operating playbook. AdMapix surfaces cross-network ad creatives and market signals to feed this workflow; it does not expose competitor spend, IPM, or your own performance outcomes, which remain private.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Meta Ads API Alternative in 2026: Ad Library API, Marketing API, or a Creative Layer?
A 2026 guide to choosing a Meta ads API alternative — what the Ad Library API, Marketing API, and Graph Ads Archive each actually expose and where they stop, how a creative-intelligence layer fills the saved-media, video-breakdown, and reporting gap, exactly what public Meta data can and cannot prove (creative yes; spend, targeting, and ROAS no), and a decision framework matched to the job you are doing.

Ad Intelligence API: What Developers Need Beyond a Raw Ads-Library Endpoint in 2026
A developer-focused guide to ad intelligence APIs: what fields make a creative record queryable, why official ads-library endpoints stop short, the buy-vs-build tradeoff for a cross-network layer, and how to design a pipeline that survives schema and rate-limit changes.

AI Creative Brief Template in 2026: Turn Competitor Evidence Into Testable Ads
A complete 2026 guide to the AI creative brief template — the nine fill-in fields that feed a model evidence instead of vibes, why the hook pattern is the highest-leverage input, how to gather example ads responsibly, the do-not-say list that keeps output honest, a prompt structure that uses the brief, how to rank output into a test backlog, a fully filled worked example, the limits of AI and public data, and where AdMapix fits.