Ad Creative Analysis in 2026: The 6-Dimension Scorecard, SOP & Teardown Templates
A complete ad creative analysis playbook for 2026 — a 6-dimension scoring scorecard, a 10-minute teardown SOP, hook and offer frameworks, a hypothesis-writing system, honest caveats about what public ad evidence can and cannot prove, and an FAQ that settles the terms teams keep arguing about.

Ad Creative Analysis in 2026: The 6-Dimension Scorecard, SOP & Teardown Templates
Updated June 21, 2026 — written and reviewed by the AdMapix Research team.
Ad creative analysis is the practice of breaking an advertisement into its working parts — hook, audience signal, proof, offer, format fit, and landing-page match — so you can explain why it works (or doesn't) and decide exactly what to test next. It is the difference between a mood-board full of screenshots and a repeatable system that turns every ad you study into a single, shippable hypothesis. This guide is for creative strategists, user-acquisition (UA) managers, performance marketers, and founders who want a disciplined teardown they can run on any ad in about ten minutes — whether it's their own underperformer or a competitor's evergreen winner. If you want the broader competitive lens that sits above the single-ad teardown, pair this with our competitor ad analysis framework; if you want to see where the saved ad examples come from, the ad creative database explains the evidence layer; and once you have hypotheses, the creative testing framework tells you how to ship them without fooling yourself.
By the end of this article you will have a six-dimension scorecard, a ten-minute teardown SOP, a hook taxonomy, an offer-clarity test, a proof ladder, a format-fit matrix, and a hypothesis-writing template — plus an honest accounting of what public ad evidence can and cannot tell you. The single most important reframe is this: ad creative analysis is not a verdict ("good ad" / "bad ad"), it is a diagnosis ("which one dimension, if fixed, changes the result?"). A verdict ends the conversation. A diagnosis starts a test.

We have torn down tens of thousands of ads across direct-to-consumer (DTC), mobile gaming, subscription apps, and B2B SaaS, and the same failure mode repeats: teams "analyze" creative by admiring it, screenshotting it, and dropping it into a swipe folder nobody reopens. That is collecting, not analyzing. Real ad creative analysis is observation plus inference plus a decision. You observe what the ad shows. You infer what choices the advertiser made and why. You decide which inference is worth a test. Everything below is built to force that third step, because analysis that never produces a test is, to put it bluntly, cosplay.
TL;DR — Ad Creative Analysis in One Screen
- Ad creative analysis means scoring an ad across six dimensions — hook, audience signal, proof, offer, format fit, and landing match — and ending with one decision: what to test next. It is a diagnosis, not a verdict.
- The first three seconds and the offer carry most of the weight. Everything else either earns the attention the hook bought or wastes it.
- Score each dimension 0–2, total out of 12, and read the low scores as your test backlog. The point isn't the total — it's locating the single weakest link.
- The output of a good teardown is a brief (hypothesis, asset to build, success metric, sample size), not a screenshot in a folder.
- A competitor ad you can see in public proves the ad ran; it does not prove it worked. Treat longevity and recurrence as soft signals, never as performance data.
- Tools that surface public creatives — including AdMapix — give you searchable cross-network creative evidence (saved examples, video breakdowns, recurring reports). They cannot show competitor spend, ROAS, impressions, or audience targeting. Plan your inferences around that limit.
- Run the teardown on a cadence: a 10-minute single-ad scorecard, a weekly batch of 5–10, and a monthly pattern rollup that names the hooks and offers winning in your category.
What Ad Creative Analysis Actually Is (and Isn't)
Ad creative analysis is the structured process of decomposing a single advertisement into the discrete choices its maker controlled — the opening frame, the spoken or written hook, the visual proof, the offer, the format, and the page it leads to — then judging each choice against what the target audience needs in order to act. It is creative-level work: the unit of analysis is one ad, or one advertiser's body of ads, not a whole market. That distinction matters because it tells you which questions are answerable. "Which hook should we test?" is a creative-analysis question. "How big is this market and who's winning it on revenue?" is a market-intelligence question that no amount of creative teardown will answer.
What ad creative analysis isn't: it isn't a swipe file, a "top 10 best ads" listicle, or a once-a-quarter audit nobody acts on. Those artifacts have reference value, but they aren't analysis any more than a pile of X-rays is a diagnosis. Analysis requires a frame — specific questions asked against specific dimensions, with the answers recorded in a structure you can compare across ads and across weeks. Without the frame, ten people look at the same ad and produce ten different vibes, and none of them converts into a test.

There's a vocabulary tangle worth cutting through, because marketers use these terms interchangeably and then talk past each other in the same meeting:
- Ad creative analysis (this guide) is the deep teardown of one ad or one advertiser's creative library — hooks, visuals, formats, offers, pacing.
- Competitor ad analysis is the umbrella discipline: creative plus messaging, channel, budget signals, and funnel, across many competitors over time. The teardown is one module inside it.
- Creative testing is what happens after analysis — you take the hypotheses the teardown produced and run controlled experiments to see which actually move the metric.
- Ad intelligence is the data layer that feeds the whole thing: the searchable evidence of which creatives ran, where, and for how long.
Holding these apart keeps you from over-claiming. A teardown can tell you an ad is well-built for its job. It cannot, on its own, tell you the ad won. The only thing that proves an ad won is performance data — and for your own ads, that lives in your analytics, not in any spy tool. For a competitor's ads, performance is, for the most part, unknowable from the outside. We'll return to that honesty repeatedly, because it's the line that separates rigorous analysts from people who confidently bet on guesses.
The Six-Dimension Scorecard
Score every ad on six dimensions, because a single "good vs. bad" verdict hides the exact part you need to fix. Rate each dimension 0–2 (0 = absent or broken, 1 = present but soft, 2 = strong and unmistakable), then read the low scores as your test backlog. The total out of 12 is a convenient label, but it is the shape of the scores — where the zeros and ones cluster — that tells you what to do Monday morning.
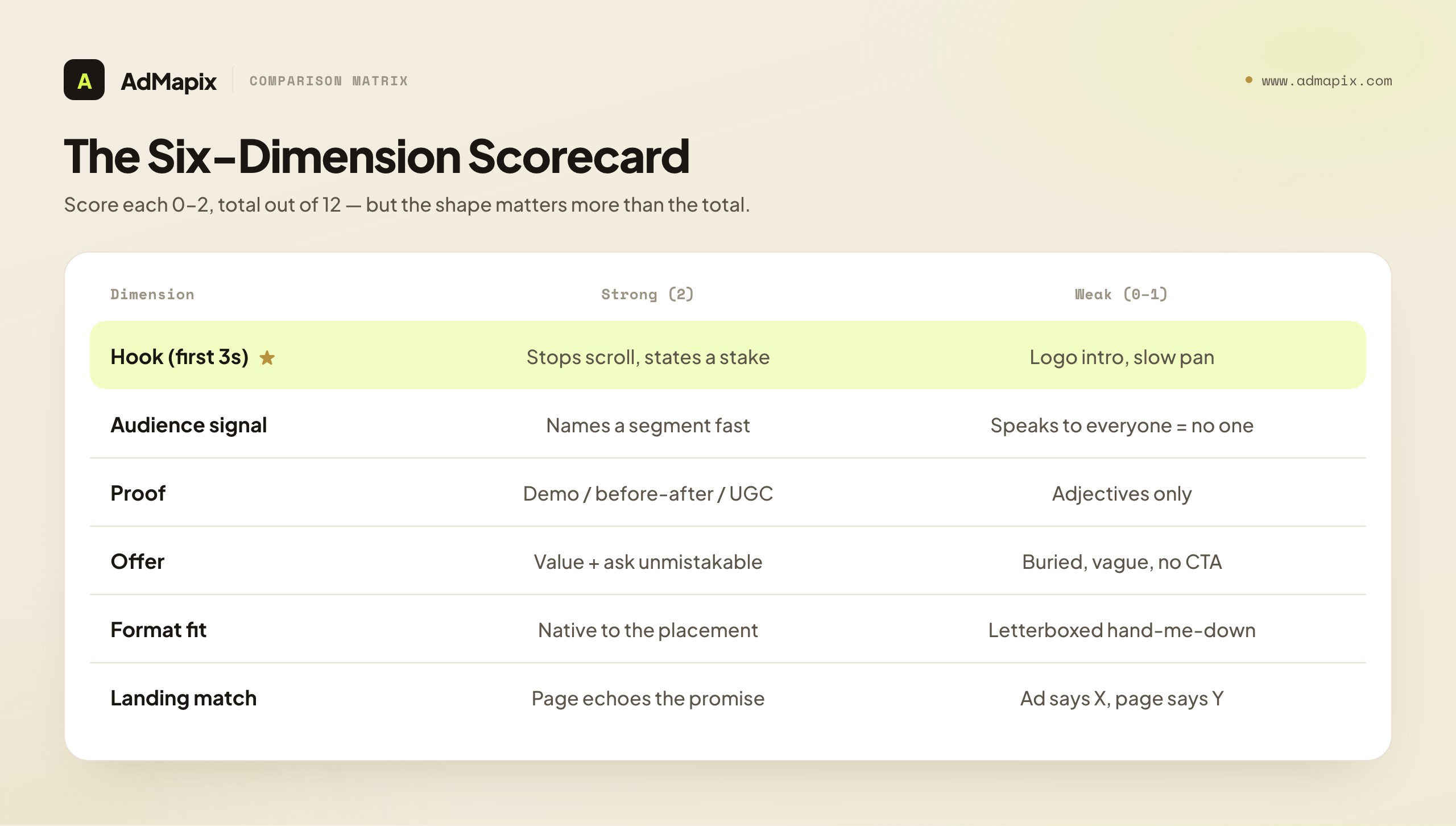
| Dimension | What to check | Strong signal (2) | Weak signal (0–1) | Next action if weak |
|---|---|---|---|---|
| Hook (first 3s) | Does the opening frame or line stop the scroll and state a stake? | A concrete problem, pattern interrupt, or specific number up front | Logo intro, slow pan, generic "introducing" | Test 3 new openings against the same body |
| Audience signal | Can you tell who this is for in one viewing? | Language, setting, or pain that names a segment | Could be for anyone, so it lands on no one | Rewrite for one named persona |
| Proof | Is the claim backed by something a skeptic accepts? | Demo, before/after, UGC, screenshot, count | Adjectives only ("amazing," "best") | Add one proof element, hold offer constant |
| Offer | Is the value and the ask unmistakable? | Clear what you get and what to do next | Buried, vague, or missing CTA | Restate the offer in the first half |
| Format fit | Does it use the placement's native strengths? | Vertical UGC for Reels, demo for in-feed video | Letterboxed landscape ad in a vertical feed | Re-cut natively for the placement |
| Landing match | Does the page deliver the ad's exact promise? | Headline, image, and offer echo the ad | Ad promises X, page opens with Y | Align the page hero to the winning ad |
The useful question after scoring is never "is this a good ad?" It is "which one dimension, if fixed, changes the result?" A 10/12 ad with a zero on landing match is leaking conversions a copywriter can recover in an afternoon. A 6/12 ad that's even across the board needs a rebuild, not a patch. The scorecard's job is to route your effort to the cheapest, highest-leverage fix — and to stop you from rewriting a hook that already works because the real problem was a page that didn't keep the ad's promise.
A note on calibration: have two people score the same five ads independently before you trust anyone's solo scores. If your "2" is someone else's "1," your backlog is noise. Spend twenty minutes aligning on what each level means for your category, write the definitions down, and re-use them. Calibrated scoring is the difference between a scorecard and a Ouija board.
One more thing about the six dimensions: they are deliberately ordered by when the viewer encounters them, not by importance. The hook comes first because it's literally the first thing on screen; landing match comes last because it happens after the click. Reading the scorecard in viewing order forces you to follow the viewer's actual experience rather than jumping to whatever you personally find interesting. Analysts who skip straight to "the offer" because they're a copywriter, or straight to "format fit" because they're an editor, consistently miss that the ad died at the hook and nothing they fixed downstream ever had a chance to matter. Score in order, every time, even when you're sure you already know the problem.
Dimension 1 — Hook: The First Three Seconds Decide the Rest
Start every teardown at the opening, because if the hook fails nothing downstream gets a chance. Mark three things: the first frame (what the eye lands on), the first spoken or written line (what the brain processes), and the exact moment the viewer learns what the ad is about. A strong hook states a stake the target audience already feels — a problem, a surprising claim, or a specific number — inside three seconds. If the product appears before the reason to care, that's your first test.
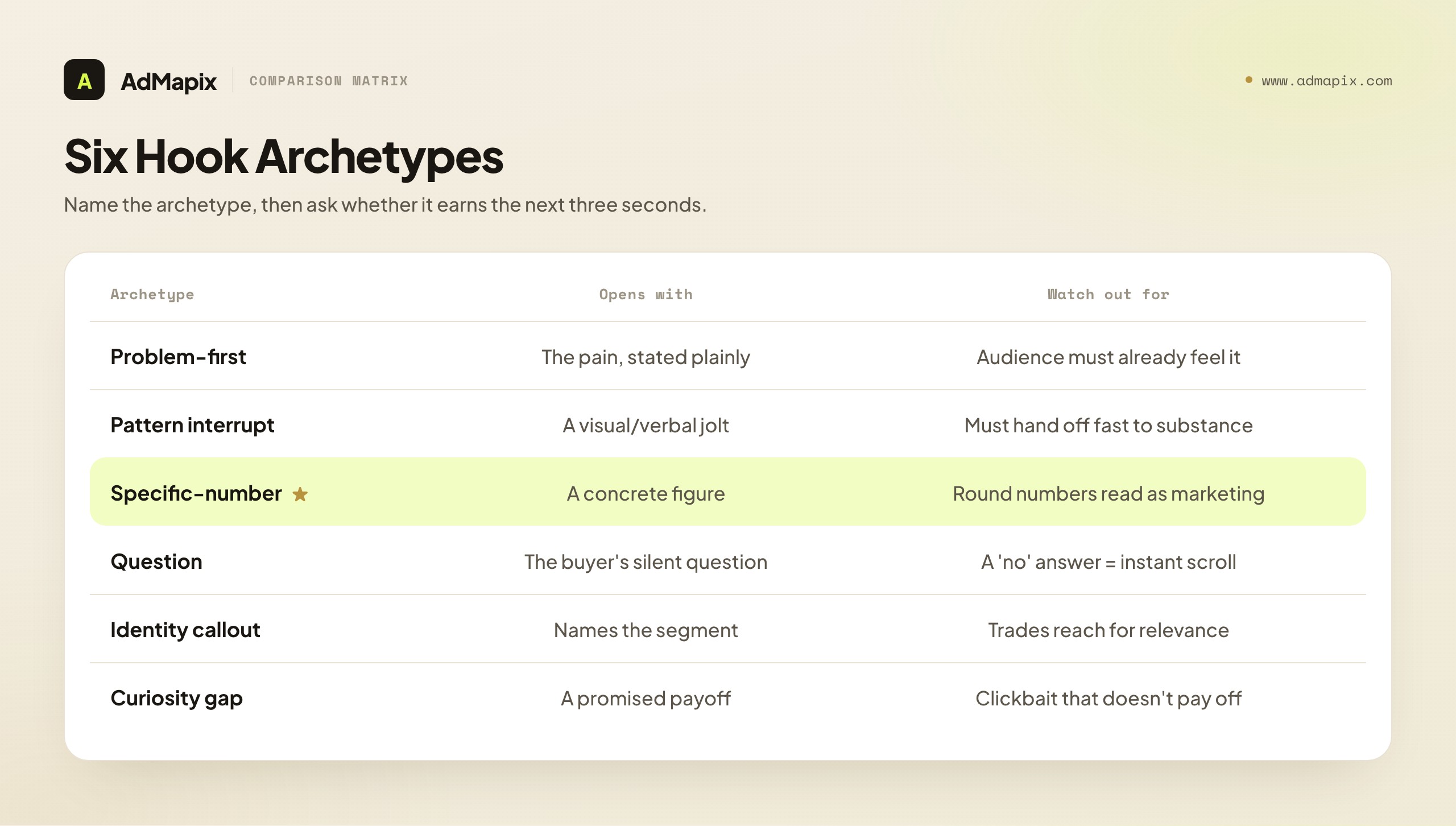
Hooks fall into a small number of repeatable archetypes, and naming them turns "I like this opening" into a pattern you can reuse:
- Problem-first — opens on the pain ("Still scrubbing burnt pans by hand?"). Works when the audience already knows the problem and is primed to nod.
- Pattern interrupt — a visual or verbal jolt that breaks the scroll's rhythm (an unexpected sound, a freeze-frame, a contrarian claim). Buys attention; must hand off fast to substance.
- Specific-number — leads with a concrete figure ("I cut my CAC 41% in six weeks"). Specificity reads as credibility; round numbers read as marketing.
- Question hook — poses the exact question the buyer is silently asking. Risk: a yes/no question the viewer answers "no" to, and scrolls.
- Identity callout — names the segment in the first line ("If you run paid social for a DTC brand…"). Sacrifices reach for relevance; brilliant for niche offers.
- Curiosity gap — promises a payoff the viewer must keep watching to get. Powerful and easily abused; clickbait that doesn't pay off trains the audience to distrust you.
When you tear down a hook, don't just label the archetype — ask whether it earns the next three seconds. Many ads buy attention with a strong open and then squander it on a logo, a slow brand intro, or a tangent. The hook's only job is to make the next beat feel mandatory. Score a 2 only when the open both stops the scroll and sets up the rest so the viewer can't comfortably leave. If an ad has a great open but you'd happily scroll at second four, that's a 1, and your test is to fix the handoff, not the open.
A practical drill: collect six hooks from ads in your category, transcribe the literal first line of each, and sort them by archetype. You'll usually find one archetype dominates the winners in your vertical. That's not a coincidence to admire — it's a hypothesis to test against a different archetype, because the category's defaults are also where everyone's ads start to look the same. The fastest creative wins often come from importing a hook archetype that's standard in an adjacent category but rare in yours.
Dimension 2 — Audience Signal: Who Is This Actually For?
The second dimension asks a deceptively simple question: after one viewing, can you name who this ad is for? Great ads make their target legible in the first few seconds through casting, setting, vocabulary, and the specific pain they name. Weak ads try to talk to everyone — and an ad addressed to everyone is addressed to no one, because the viewer never feels the jolt of "wait, that's me."

Look for the audience signal in four places. Casting and setting: does the person on screen, and the world around them, look like the buyer or like a stock-photo composite of "a human"? Vocabulary: does the script use the words the segment uses, or generic marketing-speak? "Macro your meals" signals a fitness audience; "eat healthier" signals nobody in particular. Named pain: does the ad name a problem specific enough that an outsider wouldn't fully get it? Specificity is a filter, and filters are good — they trade reach for resonance. Stage of awareness: is the ad pitched at someone who already knows they have the problem, someone shopping for solutions, or someone who's never heard of the category? An ad built for the wrong awareness stage feels "off" even when every individual element is competent.
The most common audience-signal failure is the "feature soup" ad that lists everything the product does in the hope that something resonates. It almost never does, because the viewer has to do the work of figuring out which feature is for them — and viewers don't do work. The fix is rarely "say more"; it's "say less to one person." When you score this dimension a 0 or 1, your test is almost always a persona-narrowing rewrite: take the single sharpest segment, write the ad as if it could only ever speak to them, and accept that it will repel everyone else. The repelling is the point.
There's a subtle trap here for competitive teardowns. When you study a competitor's ad and can clearly name the audience, that tells you who they are targeting with that creative — it does not tell you their whole audience, their budget split, or which segment is most profitable for them. You're reading one frame of their strategy. Useful, but don't extrapolate a full media plan from a single well-targeted ad. The honest read is "they have a creative built for segment X," not "their business depends on segment X."
Dimension 3 — Proof: Would a Skeptic Believe It?
Proof is the dimension that separates ads that claim from ads that convince. The test is simple: imagine a mildly skeptical version of your buyer watching the ad. Does anything in it survive their "yeah, right"? Adjectives don't — "amazing," "revolutionary," "best-in-class" are noise to a skeptic. Evidence does. The strongest creative replaces assertion with demonstration: show the thing working rather than saying it works.
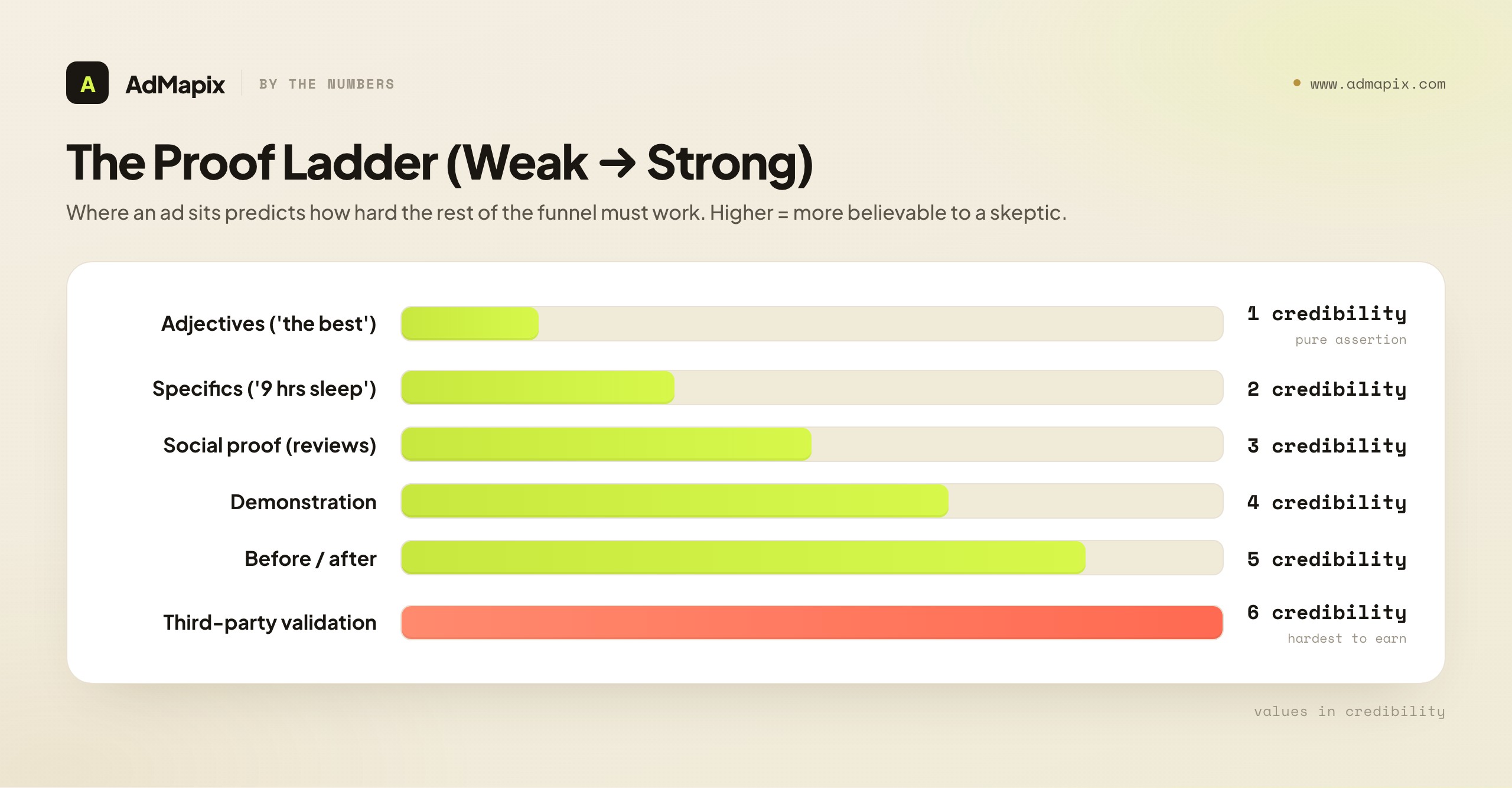
There's a rough hierarchy of proof, from weakest to strongest, and where an ad sits on it usually predicts how hard the rest of the funnel has to work:
- Adjectives ("the best sleep of your life") — zero proof; pure assertion. Skeptics discount entirely.
- Specifics ("9 hours, no waking up at 3am") — concreteness reads as more honest than superlatives.
- Social proof (review counts, ratings, "50,000 sold") — borrows credibility from the crowd; weakens if it feels fabricated or stock.
- Demonstration (the product visibly doing its job) — hard to fake, easy to believe; the workhorse of high-performing video.
- Before/after (a visible state change) — the most intuitive proof for transformation products; regulated in some categories, so check the rules.
- Third-party validation (press, named experts, verifiable test results) — strongest, but expensive to earn and easy to over-claim.
When you tear down proof, identify which rung the ad stands on, then ask whether the claim it's making requires a higher rung. A small, low-risk purchase can ride on specifics and a few reviews. A high-consideration claim ("reverse your symptoms") needs demonstration or third-party validation, or the skeptic's "yeah, right" kills the conversion no matter how good the hook was. The classic fixable failure is a strong hook and offer attached to adjective-only proof — the test is to add exactly one proof element (a demo clip, a real review, a screenshot of results) while holding everything else constant, so you can attribute the lift cleanly.
A word on user-generated content (UGC). UGC works as proof not because it's cheap to make but because it reads as un-coached — a real person, in a real setting, with the rough edges intact. The moment UGC looks produced, it loses the credibility that made it valuable and becomes just another ad with worse production. When you score a UGC ad's proof, judge authenticity, not polish. Over-polished UGC is often a downgrade disguised as an upgrade.
Dimension 4 — Offer: Is the Value and the Ask Unmistakable?
The offer is what the viewer gets and what you're asking them to do — and it's the dimension teams most often under-weight because it feels like "the boring part." It isn't. A brilliant hook attached to a muddy offer converts worse than a mediocre hook attached to a crisp one, because attention without a clear next step evaporates. Two questions decide this dimension: What do I get? and What do I do next? If a stranger can't answer both after one viewing, the offer scores a 0 or 1.

Common offer failures, each with a clean fix:
- Buried offer — the value shows up at second 25 of a 30-second ad. Fix: restate the offer in the first half; assume most viewers never reach the end.
- Vague value — "transform your business" tells the viewer nothing. Fix: name the specific, concrete benefit ("invoices paid in 2 days, not 30").
- Missing or weak CTA — the ad informs but never asks. Fix: add one unambiguous action ("Get the free trial," "Shop the sale today").
- Offer/landing mismatch — the ad promises 40% off; the page opens at full price. Fix: make the page hero echo the ad's exact offer (this overlaps with Dimension 6 and is the single most common conversion leak we see).
- Too many asks — "subscribe, follow, share, and buy." Fix: one ad, one action. Every extra ask divides the conversion.
The offer is also where you separate brand ads from performance ads, and judging them on the same rubric is a category error. A brand ad can legitimately score low on "explicit CTA" because its job is recall, not immediate action. A performance ad with a vague CTA is just broken. Before you score the offer, decide which kind of ad you're tearing down. If it's a competitor's ad and you can't tell, that ambiguity is itself a finding — it often means the advertiser hasn't decided either, which is a beatable weakness.
One more reframe that pays off: the strongest offers reduce perceived risk, not just price. A free trial, a money-back guarantee, "cancel anytime," or "no card required" can lift conversion more than a discount because they remove the fear that stops the click. When you tear down an offer that's converting despite a modest discount, look for the risk-reversal — it's often the real engine, and it's cheaper to copy than a price cut.
Dimension 5 — Format Fit: Native to the Placement, or a Repurposed Hand-Me-Down?
Format fit asks whether the creative uses the native strengths of the placement it's running in — or whether it's a hand-me-down from another channel wearing the wrong clothes. The classic tell is a letterboxed landscape video sitting in a vertical feed, black bars top and bottom, screaming "this was made for a different platform." Viewers register that as low-effort before they process a single word, and low-effort creative gets the scroll.

Native format fit means matching the creative to how people actually consume the placement. Vertical, sound-optional, fast-cut UGC suits short-form feeds. A clean product demo suits in-feed video where the viewer has opted into a longer watch. A static with a single bold claim suits placements where motion isn't supported or wanted. A carousel suits offers with multiple distinct value props or steps. The point isn't that one format is universally better — it's that each placement rewards a different shape, and an ad that ignores the shape is fighting the medium.
When you score format fit, check four things: aspect ratio (does it fill the frame natively, no letterboxing?), sound dependence (does it work muted, with captions, since most feeds autoplay silent?), pacing (does it match the placement's attention span — fast for feeds, patient for opted-in video?), and first-frame legibility (does a still of frame one already communicate something, since that's what shows before autoplay kicks in?). A 2 means the ad feels like it was born for that placement. A 0–1 means it's a guest wearing borrowed clothes, and the fix is a native re-cut, not a new concept.
Format fit is also the dimension where you'll see the clearest competitor patterns. Advertisers running the same core concept re-cut natively for three placements are signaling a mature creative operation — they understand that the concept and the cut are different problems. When a teardown reveals that pattern, the inference is "this team takes creative production seriously," which is more strategically useful than admiring any single cut. And if you see a competitor running the same letterboxed file everywhere, that's a soft signal of a thin creative operation — a gap you might out-execute on craft alone.
Dimension 6 — Landing Match: Does the Page Keep the Ad's Promise?
The last dimension lives outside the ad itself, which is exactly why teams forget it — and why it's the most common conversion leak in the whole funnel. Landing match measures whether the destination page delivers the exact promise the ad made. The viewer clicked because of a specific hook, a specific offer, a specific image. If the page opens with a different headline, a different price, or a generic homepage, you've broken the continuity that the click was built on, and a meaningful share of that hard-won traffic bounces in the first two seconds.

Three things must echo from the ad to the page: the message (the page headline should restate or directly continue the ad's hook), the offer (if the ad said 40% off, the page hero says 40% off — not "welcome to our store"), and the visual (the hero image or video should feel like the same world as the ad, so the viewer's brain confirms "yes, I'm in the right place"). This is sometimes called message match or scent — the idea that a click leaves a "scent" the page must continue, or the visitor feels lost and leaves.
You can't always inspect a competitor's landing page in a teardown — and even when you can, the page may be personalized or A/B tested, so what you see may not be what their traffic sees. For your own ads, though, landing match is the cheapest, fastest fix on this entire scorecard. It requires no new creative — just a copywriter aligning the page hero to the winning ad. We routinely see teams pour weeks into new hooks while the real leak is a page that never echoed the hook they already had. Before you green-light a creative rebuild, score landing match honestly. If it's a 0, fix the page first; you may discover the creative was fine all along.
A useful exercise: screenshot the ad's hook frame and the page's hero side by side. If a stranger couldn't tell they belong together, you have a match problem. Do this for your top three converting ads and you'll often find one quick fix that lifts conversion more than a month of creative iteration.
The 10-Minute Teardown SOP
A scorecard is only useful if you can run it fast and consistently. Here is the standard operating procedure we use to tear down a single ad in about ten minutes, designed so two people running it on the same ad land within a point of each other. The discipline is in the order: you watch before you judge, you score before you opine, and you finish with a decision before you move on.
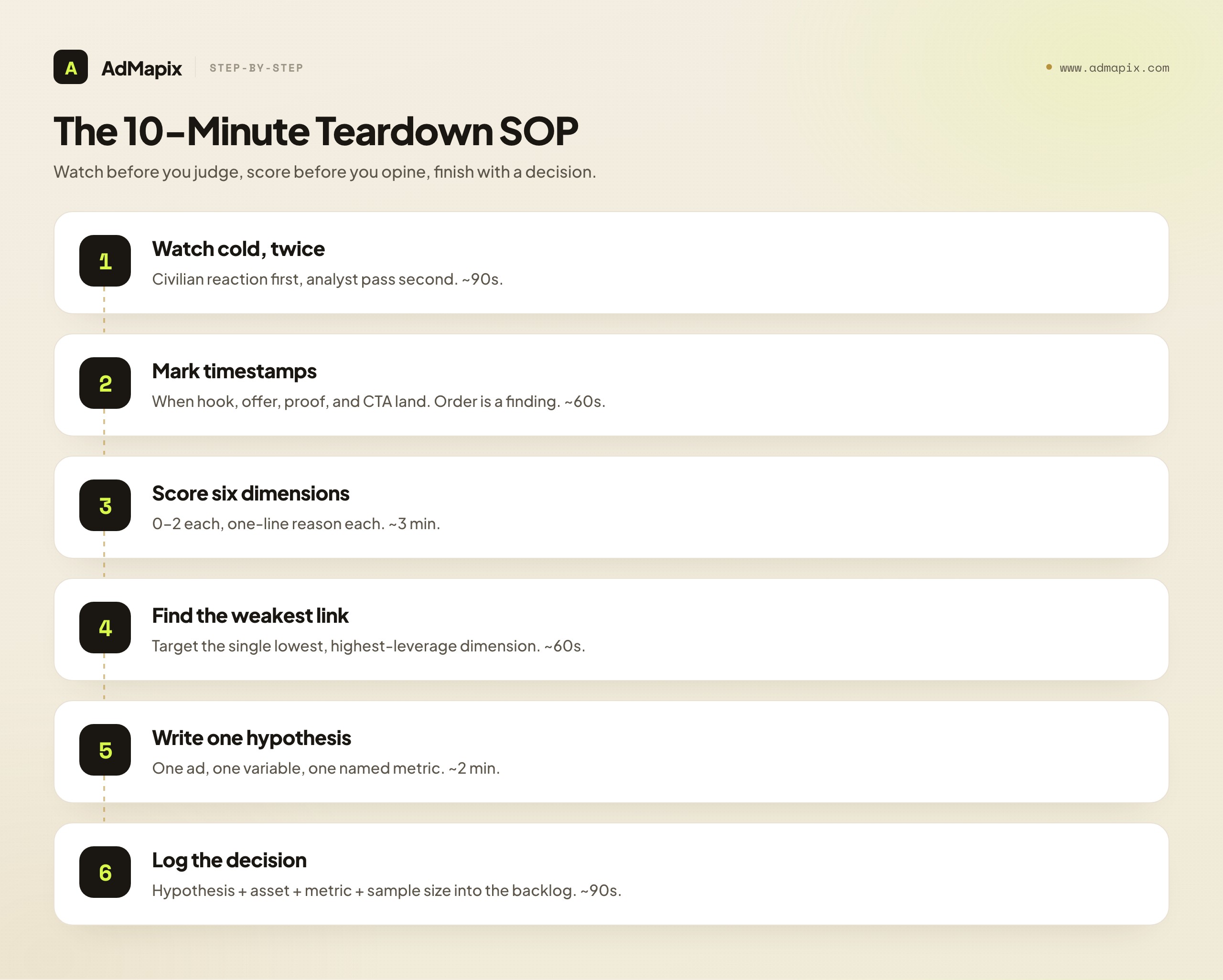
- Watch it cold, twice (90 seconds). First pass: react as a normal viewer — where did your attention go, where did it drift? Second pass: watch as an analyst, noting the first frame, first line, and the moment intent becomes clear. Don't take notes on pass one; you want the civilian reaction before the expert one contaminates it.
- Mark the timestamps (60 seconds). Note when the hook lands, when the offer appears, when proof shows up, and when the CTA fires. The order of these beats is itself a finding — proof before offer reads very differently from offer before proof.
- Score the six dimensions (3 minutes). Use the 0–2 rubric. Resist the urge to explain yet; just put down the numbers, then your one-line reason for each. If you can't write the reason in a line, you don't understand the dimension well enough to score it.
- Find the weakest link (60 seconds). Look at the zeros and ones. The single lowest, highest-leverage dimension is your target — not all of them. Fixing one thing cleanly beats nudging five.
- Write one hypothesis (2 minutes). Convert the weakest link into a testable statement (template below). One ad, one hypothesis. Resist the urge to fix everything; you won't learn anything from a five-variable change.
- Log the decision (90 seconds). Record the hypothesis, the asset to build, the success metric, and the minimum sample size. If it doesn't enter the test backlog, the teardown didn't happen — it was just admiring.
The whole point of the time-box is to make teardowns cheap enough to do often. A 90-minute artisanal teardown gets done once and forgotten. A 10-minute teardown gets run on ten ads a week, and the patterns across those ten are where the real intelligence lives. Speed plus volume plus structure beats depth-on-one every time, because creative analysis is a time series, not a snapshot.
Turning a Teardown Into a Testable Hypothesis
The deliverable of ad creative analysis is not insight — it's a hypothesis you can ship. A vague takeaway ("the hook could be stronger") dies in the meeting. A structured hypothesis enters the backlog and changes the next campaign. Use this template every time, because the structure forces you to specify the things that make a test interpretable.

Because [observed weakness from the teardown], we believe [specific change] will [predicted effect on a named metric] for [audience], and we'll know we're right if [metric] moves [threshold] at [sample size].
A worked example: Because the ad opens on a slow brand intro before naming the problem (Hook = 1), we believe replacing the first three seconds with a problem-first open will lift 3-second video view rate for cold prospecting, and we'll know we're right if hook rate moves +20% relative over 50,000 impressions. Notice what the template forces: a single variable (the open), a named metric (3-second hook rate), a direction and threshold (+20% relative), and a stopping rule (50k impressions). Without those, you'll either call a win on noise or argue forever about whether it worked.
Three rules keep hypotheses honest. One variable at a time — if you change the hook and the offer, a win tells you nothing about which mattered. Name the metric before you run — picking the metric after you see the data is how people fool themselves. Set the sample size up front — small samples produce big, fake swings; decide how much data you need to believe the result before you start. These rules feel pedantic until the first time a "winner" reverses on more data and you realize you shipped noise. The teardown finds the lever; the test confirms it's real. Skipping the second half is how teams accumulate confident, expensive superstitions.
What Public Ad Evidence Can and Cannot Prove (Read This Twice)
This is the section that keeps your analysis honest, so don't skim it. When you tear down a competitor's ad, you are working from public evidence — the ad ran, it ran in certain placements, and (sometimes) it ran for a certain duration. That's real signal. But there is a hard ceiling on what public creative evidence can tell you, and pretending otherwise is how teams make confident, wrong bets.

Here's the honest split. You can read, from public ad evidence: which creatives an advertiser ran, the formats and placements they used, the hooks and offers and proof they chose, and — when the source timestamps it — roughly how long a creative stayed live. You cannot read: the ad's actual spend, its ROAS or conversion rate, its impressions or reach, the audience it was targeted to, the bids behind it, or whether it was a winner or a money-losing test the advertiser killed quietly. Longevity is the most tempting proxy — "it ran 60 days, so it must work" — but it's a soft signal, not proof. An ad can run a long time because it's a winner, because nobody's minding the account, or because it's a brand placement judged on metrics you can't see.
This is exactly where tools like AdMapix are honest about their lane. AdMapix gives you searchable, cross-network creative evidence — saved ad examples, video breakdowns, and recurring reports — so you can find and tear down what's actually running across platforms in your category. That's genuinely valuable: it's the raw material this entire scorecard runs on. But AdMapix cannot show you a competitor's spend, ROAS, impressions, or targeting, and it doesn't claim to, because that data simply isn't public. The strength is evidence of creative, not proof of performance. Build your inferences on that foundation and you'll be right more often; treat a long-running competitor ad as confirmed truth and you'll eventually copy someone else's expensive mistake.
The discipline this demands is small but crucial: when you record a competitor finding, label it as evidence, not result. Write "they ran a problem-first UGC hook for 6+ weeks" (evidence), not "their problem-first hook is their top performer" (a result you can't verify). The first is a hypothesis worth testing in your account, where you can measure the result. The second is a guess wearing the costume of a fact. Your own analytics is the only place creative performance becomes knowable — which is why every teardown should end pointed at a test, not at a conclusion.
Building a Teardown Cadence (Single Ad → Weekly Batch → Monthly Pattern)
A one-off teardown is a tactic; a cadence is a system. The value of ad creative analysis compounds when you run it on a rhythm, because patterns only emerge across volume and time. Here's the cadence we recommend, scaled to a small performance team.
The single-ad scorecard (10 minutes, on demand). Run it whenever an ad over- or under-performs, whenever you spot a competitor creative worth studying, or whenever you're stuck on what to test next. This is the atomic unit. Every other layer is built from these.
The weekly batch (60–90 minutes, every Monday). Tear down 5–10 ads — a mix of your own recent performers, your own losers, and competitor creatives surfaced from your ad-evidence tool. Score them all, then look across the batch: which hooks recur, which offers cluster, where the category's defaults are. The weekly batch is where you build your test backlog for the sprint. Aim to leave with three to five hypotheses, ranked by leverage (biggest expected lift for the cheapest build).
The monthly pattern rollup (half a day). Aggregate the month's teardowns and name the patterns: the hooks winning in your category, the offers gaining traction, the formats your competitors are converging on, and the gaps nobody's exploiting. This is also where you grade your own hit rate — what fraction of last month's hypotheses, once tested, actually moved the metric? A team running below ~30% hypothesis-hit-rate is teardown-ing well but testing badly (or vice versa); the rollup is where you catch that.
The rollup feeds strategy; the weekly batch feeds the sprint; the single-ad scorecard feeds the moment. Skip the rollup and you'll keep re-discovering the same patterns. Skip the batch and your teardowns stay disconnected. Skip the scorecard and you have no inputs at all. The cadence is what turns ad creative analysis from a skill a few people have into a capability the team owns — and capabilities, unlike skills, survive someone leaving.
Common Teardown Mistakes (and How to Avoid Them)
Even teams that adopt a scorecard fall into the same traps. Knowing them in advance is cheaper than learning them in production.
Admiring instead of analyzing. The most common failure: a beautiful ad gets a "wow, that's good" and a screenshot, and no decision follows. The fix is structural — never close a teardown without a logged hypothesis. If the ad is genuinely great with nothing to test, the finding is "import this hook archetype into our next test," which is still a decision.
Scoring the production, not the strategy. High production value is seductive and frequently irrelevant. A gorgeous ad with a buried offer converts worse than an ugly one with a crisp offer. Score the choices, not the polish. When you catch yourself giving points for "it looks expensive," stop and re-read the offer and proof dimensions.
Extrapolating a strategy from one ad. A single competitor creative is one frame of their movie. It tells you they have a creative built a certain way; it does not reveal their budget, their best segment, or their plan. Record the evidence; resist the narrative.
Changing five things and calling the result a learning. A multi-variable change that wins teaches you nothing about why. One variable per test, always — even though it feels slow. The slowness is the price of actually knowing.
Treating longevity as performance. "It's been running for months" is a soft signal at best. Plenty of long-running ads are neglected, brand-judged, or losing money the account owner hasn't noticed. Never bet real budget on someone else's unverified ad.
Skipping calibration. If two analysts score the same ad three points apart, your backlog is noise. Calibrate on five ads, write down what each level means, and re-calibrate quarterly. Uncalibrated scores feel rigorous and aren't.
Forgetting landing match. Teams obsess over the ad and ignore the page the ad leads to — and the page is where the cheapest fix usually hides. Score Dimension 6 honestly before you green-light any creative rebuild.
Avoiding these seven is most of the battle. The scorecard gives you the structure; this list keeps you from gaming it.
There's an eighth, quieter failure worth naming because it kills teams slowly rather than loudly: letting the backlog rot. A team can run flawless teardowns, write crisp hypotheses, log them diligently — and then never ship them, because the backlog grows faster than the test budget. Six months later they have a beautiful spreadsheet of insights and the same creative they started with. The fix is to treat the backlog as a queue with a fixed throughput, not an infinite inbox. Cap it. Rank by leverage. Ship the top item every sprint, and ruthlessly drop hypotheses that have sat untested for two months — if they were going to matter, you'd have run them. A short, live backlog that turns over weekly beats a long, dead one that documents your good intentions.
Putting It Together: A Worked End-to-End Teardown
Let's run the whole system on a hypothetical but realistic ad so the abstractions land. Imagine a 22-second in-feed video for a meal-prep app. It opens on the app's logo animation (two seconds), cuts to a person scrolling recipes, lists four features in quick captions, and ends with "Download now" over a price-free CTA. The landing page, when you click, is the app store listing.
Watch cold: attention drifts during the logo intro; the feature captions go by too fast to absorb; the ad never names who it's for. Timestamps: hook never really lands (logo, then generic scrolling), offer is vague ("download"), proof is absent (no demo of meals, no reviews), CTA is present but value-free. Score: Hook 0 (logo intro, no stake), Audience 1 (vaguely "people who cook," but no segment named), Proof 0 (no demonstration or social proof), Offer 1 (CTA exists, value unclear), Format fit 2 (vertical, sound-optional, fine), Landing match 1 (store listing is on-topic but doesn't echo any specific promise). Total: 5/12.
Weakest link: Hook (0) and Proof (0) are tied at the bottom, but Hook gates everything — a fixed hook gives the other dimensions a chance, while better proof behind a dead hook is wasted. So Hook is the target. Hypothesis: Because the ad opens on a logo intro with no stake (Hook = 0), we believe replacing the first three seconds with a problem-first open ("Spending Sunday cooking five days of lunches?") will lift the 3-second hook rate for cold prospecting, and we'll know we're right if hook rate moves +25% relative over 50,000 impressions. Decision logged: build three problem-first openers on the same body, hold offer and proof constant, run to 50k impressions, judge on hook rate, then re-tear-down the winner to attack the next weakest link (Proof).
Notice the discipline: one variable, named metric, threshold, sample size, and a plan for the next iteration. That's the loop. Teardown finds the lever, hypothesis specifies the test, the test produces a result your analytics can verify, and the winner goes back through the scorecard so the next weakest link becomes the next test. Run that loop on a cadence and your creative gets measurably better — not because you found one magic ad to copy, but because you built a system that keeps finding the cheapest next improvement.
FAQ
What is ad creative analysis, in one sentence?
Ad creative analysis is breaking an advertisement into its working parts — hook, audience signal, proof, offer, format fit, and landing match — scoring each, and finishing with one decision about what to test next. It's a diagnosis that produces a testable hypothesis, not a verdict that ends the conversation.
How is ad creative analysis different from competitor ad analysis?
Ad creative analysis is the deep teardown of one ad or one advertiser's creative library — it's creative-level work. Competitor ad analysis is the broader discipline that adds messaging, channel, budget signals, and funnel across many competitors over time. The teardown is one module inside the larger framework; see our competitor ad analysis framework for the umbrella view.
How long should a single ad teardown take?
About ten minutes once you've internalized the scorecard. The discipline is the time-box, not the depth — a fast, structured teardown you run on ten ads a week beats a 90-minute artisanal one you do once and forget, because creative analysis is a time series and patterns only show up across volume.
Can ad creative analysis tell me if a competitor's ad is actually working?
No. Public ad evidence proves an ad ran; it can't prove it worked. You can't see a competitor's spend, ROAS, impressions, or targeting from the outside. Treat longevity and recurrence as soft signals and record competitor findings as evidence ("they ran a problem-first hook for 6+ weeks"), not as results you can verify.
What can AdMapix actually show me for creative analysis?
AdMapix gives you searchable, cross-network creative evidence — saved ad examples, video breakdowns, and recurring reports — so you can find and tear down what's running across platforms in your category. That's the raw material this scorecard runs on. It cannot show competitor spend, ROAS, impressions, or audience targeting, because that data isn't public; its strength is evidence of creative, not proof of performance.
Which dimension matters most?
The hook and the offer carry the most weight. The hook gates everything — if the first three seconds fail, no downstream element gets a chance — and the offer determines whether the attention the hook bought converts. That said, the right answer is whichever dimension scores lowest, because fixing the weakest link is almost always the cheapest, highest-leverage move.
How do I turn a teardown into something my team can act on?
Convert the weakest-scoring dimension into a structured hypothesis: "Because [weakness], we believe [one change] will [effect on a named metric] for [audience], and we'll know if [metric] moves [threshold] at [sample size]." That single sentence — one variable, named metric, threshold, sample size — is what enters the test backlog. A vague takeaway dies in the meeting; a structured hypothesis ships.
Why score 0–2 instead of a 1–10 rating?
Because 1–10 invites false precision and arguments about whether something is a 6 or a 7. A 0–2 scale (absent / soft / strong) is coarse enough that two calibrated analysts agree, and the goal isn't a precise total anyway — it's locating the single weakest link. Coarse-but-reliable beats fine-but-noisy for routing your effort.
How often should I run teardowns?
On a cadence: a 10-minute single-ad scorecard on demand, a weekly batch of 5–10 ads to build your test backlog, and a monthly pattern rollup to name the hooks and offers winning in your category and to grade your own hypothesis-hit-rate. The single ad feeds the moment, the batch feeds the sprint, the rollup feeds strategy.
Does high production value mean a better ad?
No — and conflating the two is a classic teardown mistake. A polished ad with a buried offer converts worse than a rough one with a crisp offer. Score the strategic choices (hook, audience, proof, offer, fit, match), not the polish. If you catch yourself awarding points for "it looks expensive," re-read the offer and proof dimensions.
What's the single most overlooked dimension?
Landing match. Teams pour effort into the ad and ignore the page it leads to, where the cheapest fix usually hides. If the page doesn't echo the ad's exact message, offer, and visual, you break the continuity the click was built on and bounce hard-won traffic. Score it honestly before green-lighting any creative rebuild — you may find the creative was fine all along.
Related Reading
Take the single-ad teardown up a level with the competitor ad analysis framework, see where the creative evidence comes from in the ad creative database guide, and learn how to ship your hypotheses without fooling yourself in the creative testing framework. For the tooling landscape, compare the best ad spy tools for 2026 and the best ad intelligence tools, and for the strategic context that wraps it all, read the advertising intelligence guide.
See what competitors are really running
Search 6M+ ad creatives, landing pages, and weekly spend across 200+ countries. No credit card, no commitment.
Related Articles

Playable Ad Analysis for Mobile Games: A Practical Method
A practical method for playable ad analysis in mobile games: how to reverse-engineer a competitor's playable by the job it is built to do, decode its structure beat by beat, infer which concepts are likely working, turn observations into testable briefs, and stay honest about what a public playable proves (structure and intent) versus what it never can (spend, installs, retention, ROAS).

Best Mobile Game Ad Formats Across Platforms: A 2026 UA Playbook
A platform-by-platform guide to the best mobile game ad formats in 2026: which formats do the heavy lifting on Meta, Google, TikTok, AppLovin, and Unity; why the right format depends on platform, genre, and funnel stage; a format-selection framework; a creative-testing cadence; and the honest limits of what competitor ads can and cannot tell you about which format wins.

Meta Ads Library vs Ad Intelligence Tools for Game UA (2026): Which to Use, When, and Why
A definitive 2026 comparison of the Meta Ads Library vs dedicated ad intelligence tools for mobile game user acquisition — where the free transparency library genuinely helps, the structural limits that create blind spots for game UA creative research, a side-by-side capability matrix, the exact decision criteria for when to add a paid intelligence layer, and an honest account of what neither can show.